



Livy0.7.0 提交sparkStreaming 任务
livy提交spark方式:
Livy是一个基于Spark的开源REST服务,它能够通过REST的方式将代码片段或是序列化的二进制代码提交到Spark集群中去执行。
livy 将每一个启动的spark任务称之为session,Session是通过RPC协议在spark集群和livy服务端进行通信。根据处理方式不同分为两种Session类型:
(1)交互式会话,这与Spark中的交互式处理相同 如spark shell,交互式会话在其启动后可以接收用户所提交的代码片段,在远端的Spark集群上编译并执行;
(2)批处理会话, 用户可以通过Livy以批处理的方式启动Spark应用 如spark submit,这样的一个方式在Livy中称之为批处理会话,这与Spark中的批处理是相同的。
1.交互式会话 livy rest API 测试
以下为部分测试,cdh3是livy所在主机名
官网更多API:http://livy.apache.org/docs/latest/rest-api.html#batch
1.1获取livy所有session http://cdh3:8998/sessions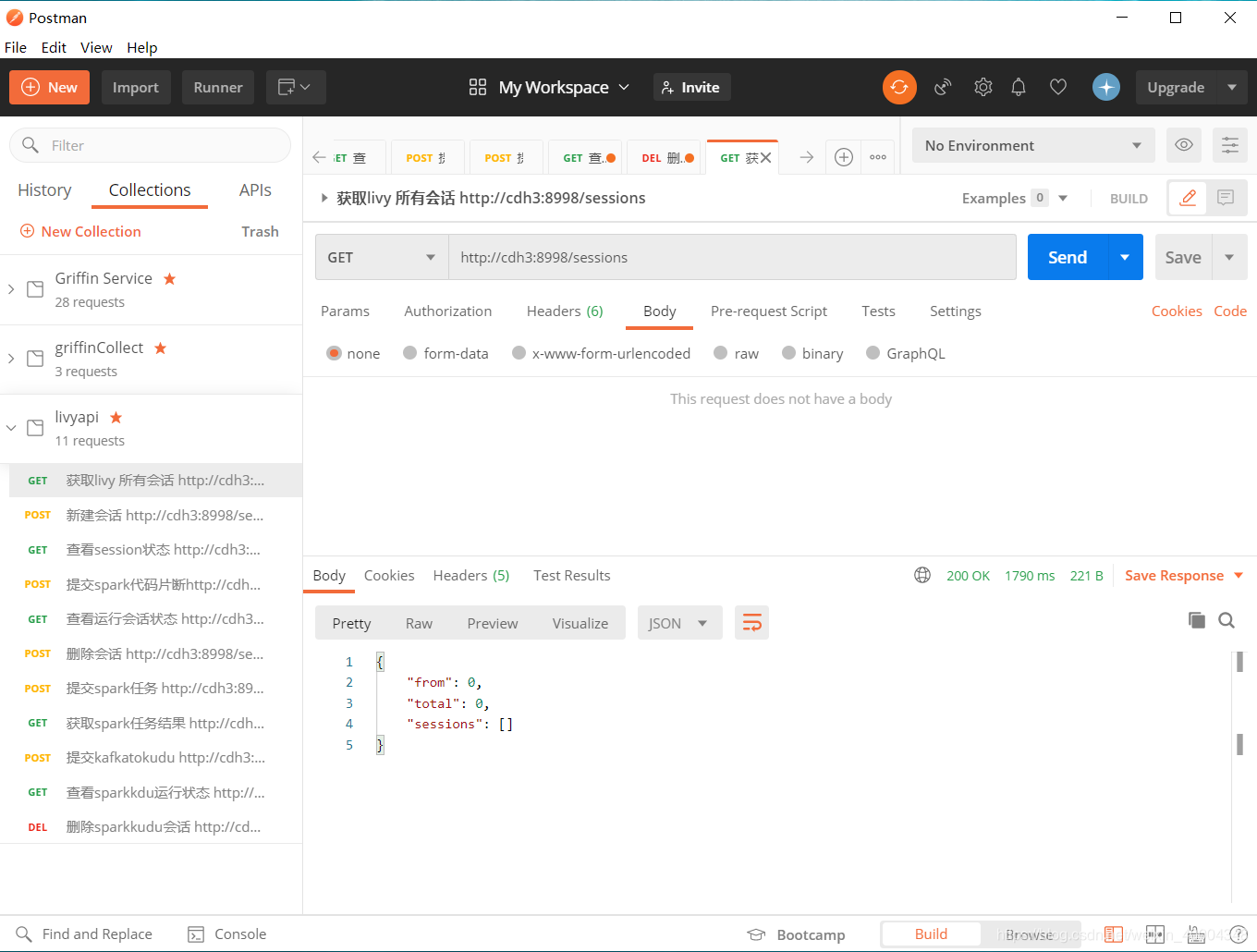
1.2新建session
http://cdh3:8998/sessions
{"name":"sparkshell-4", "kind":"spark", "executorMemory":"512m"}
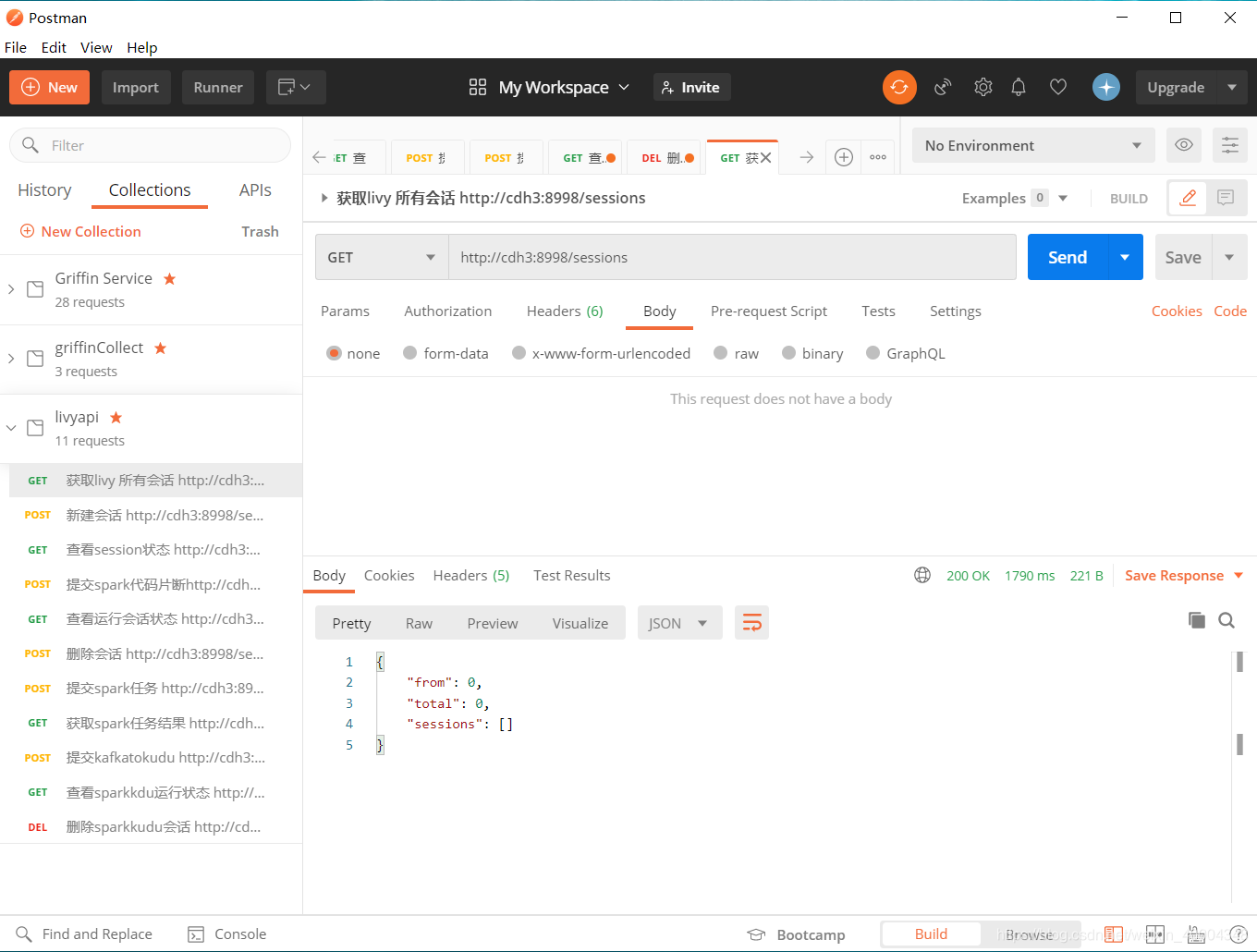
1.3 查看session状态
http://cdh3:8998/sessions
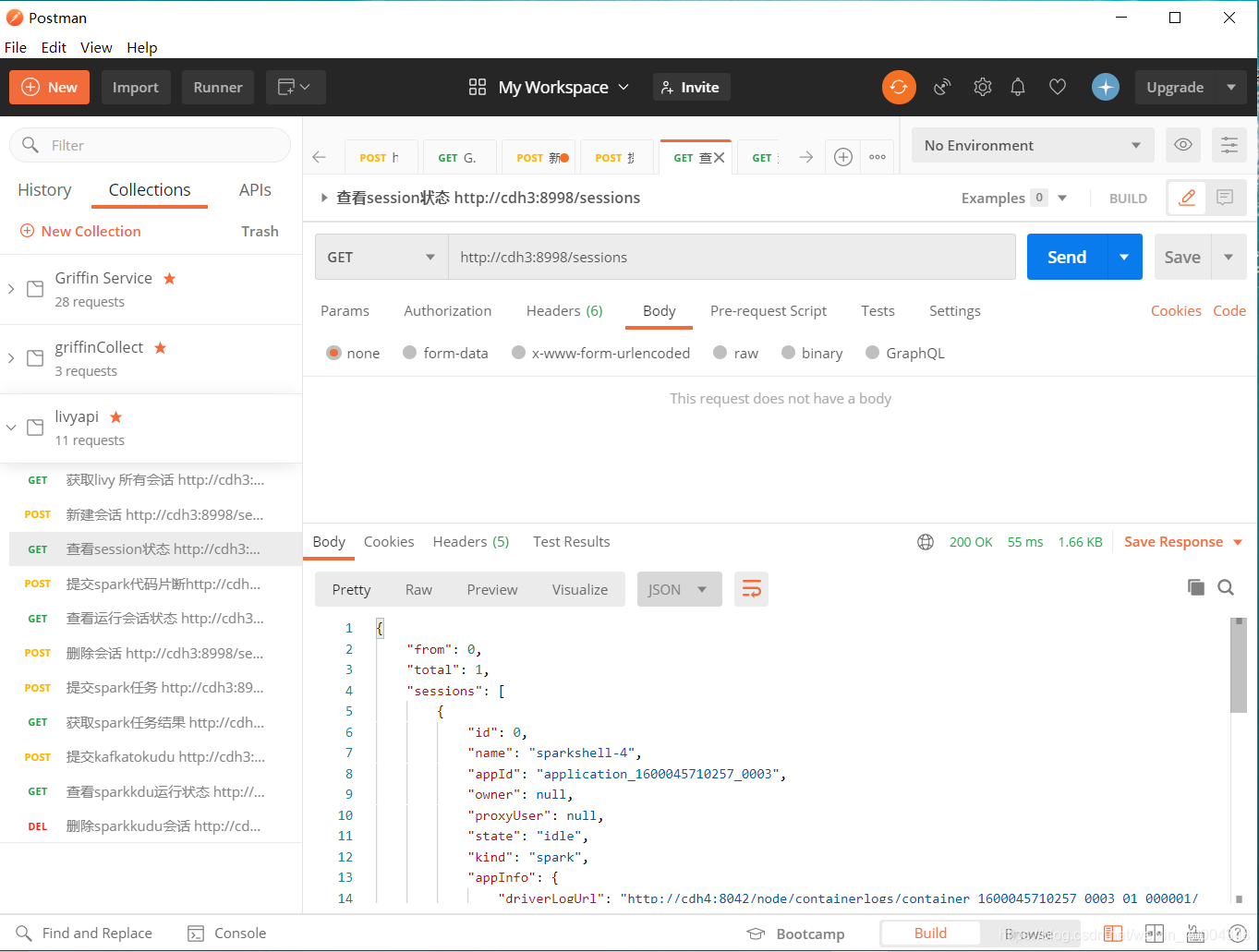
livy web显示session ,此时相当于提交了spark-shell,等待spark代码进行计算,可通过livy application的log查看状态。session id 为0,后续根据该id对该session操作
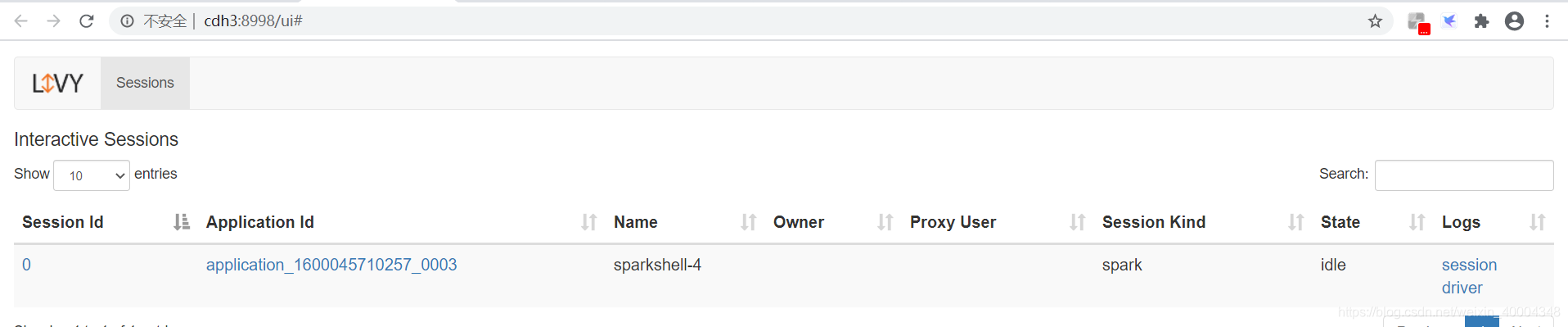
1.4提交spark代码片段到session 0
http://cdh3:8998/sessions/0/statements
{ "code":"sc.makeRDD(List(1,2,3,4)).count"}
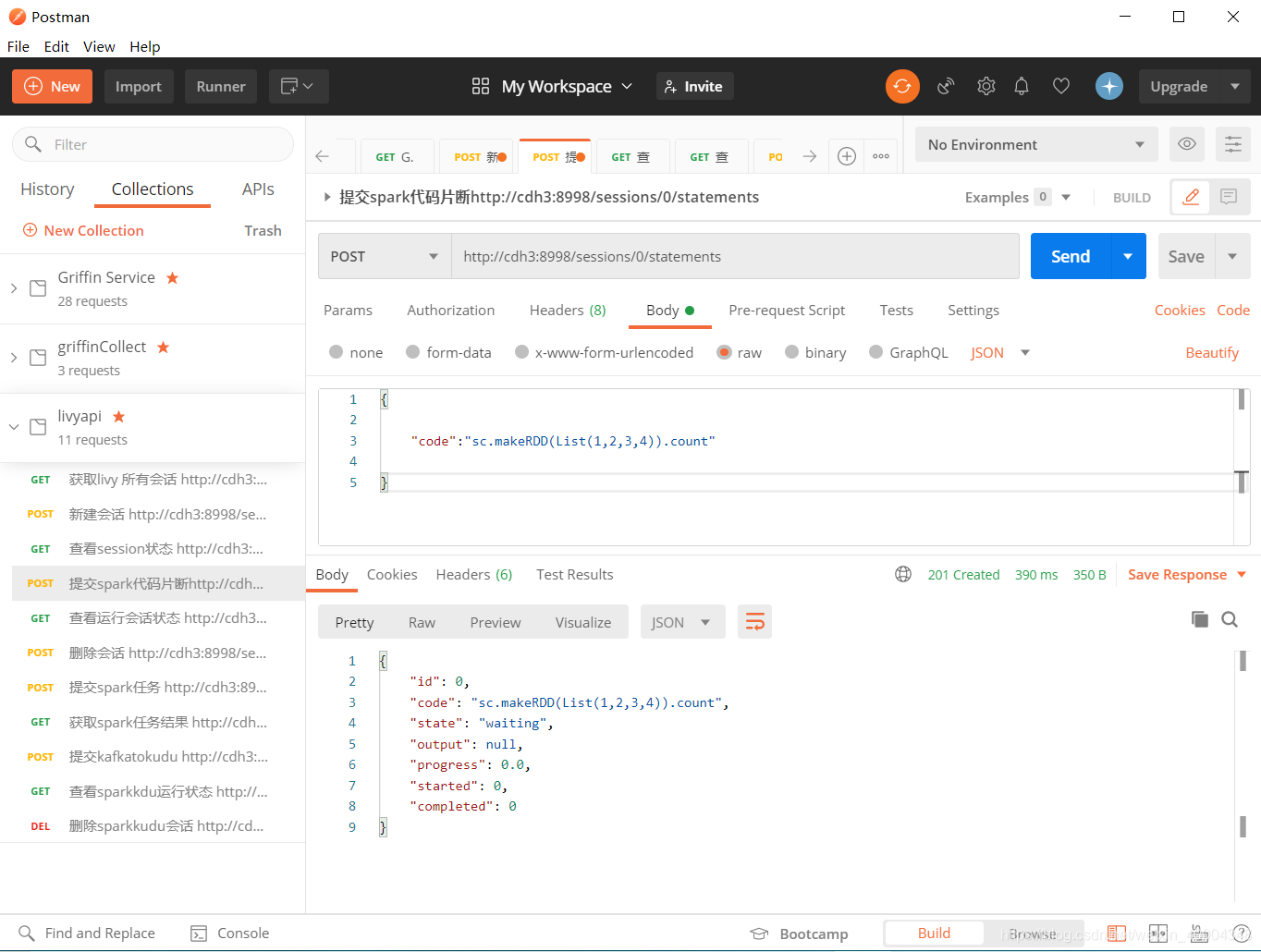
livy为异步提交,post提交后即返回结果。计算后台运行。要查看最终结果得主动调用查询。
1.5 查看session运行状态
http://cdh3:8998/sessions/0/statements
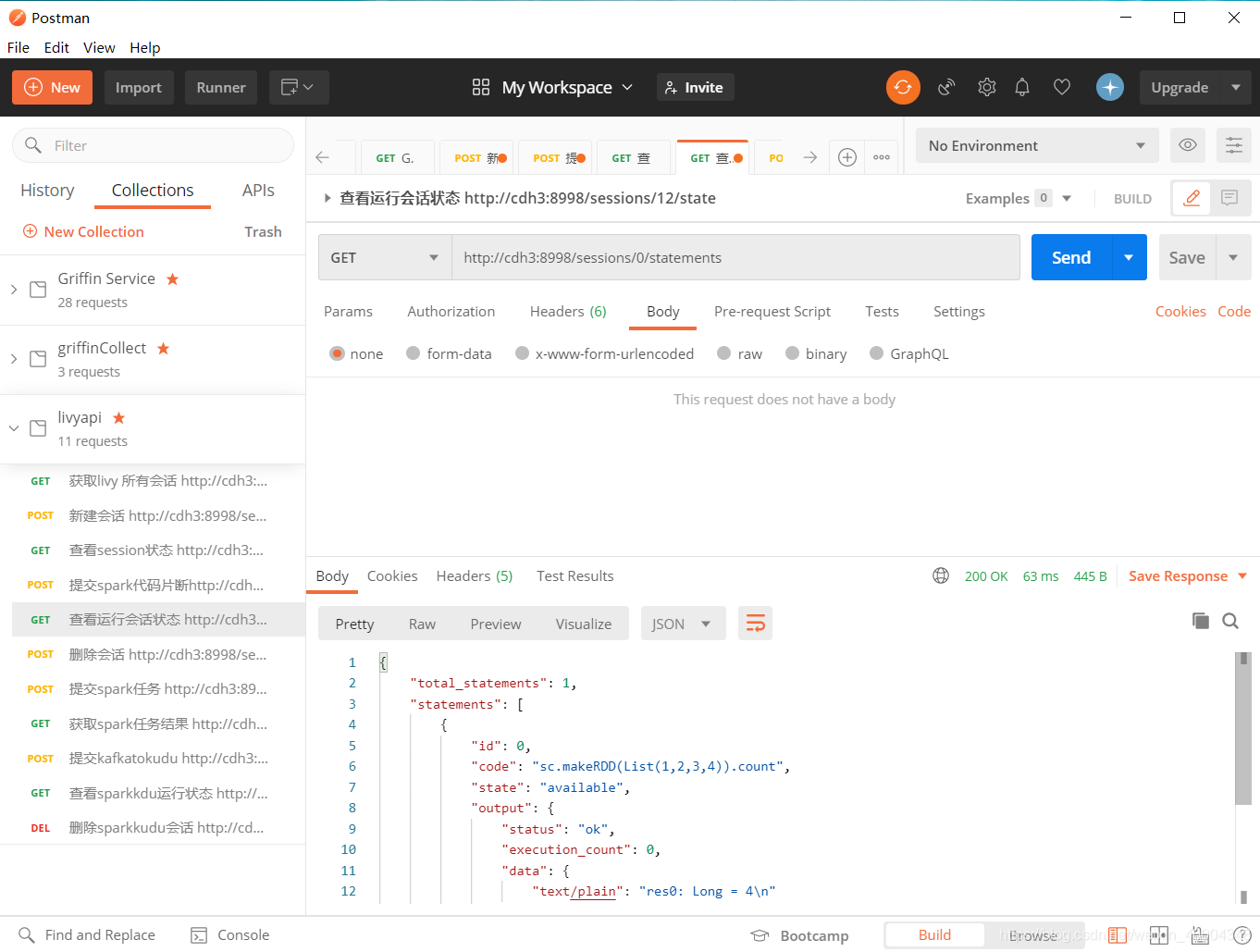
1.6 删除session
http://cdh3:8998/sessions/0
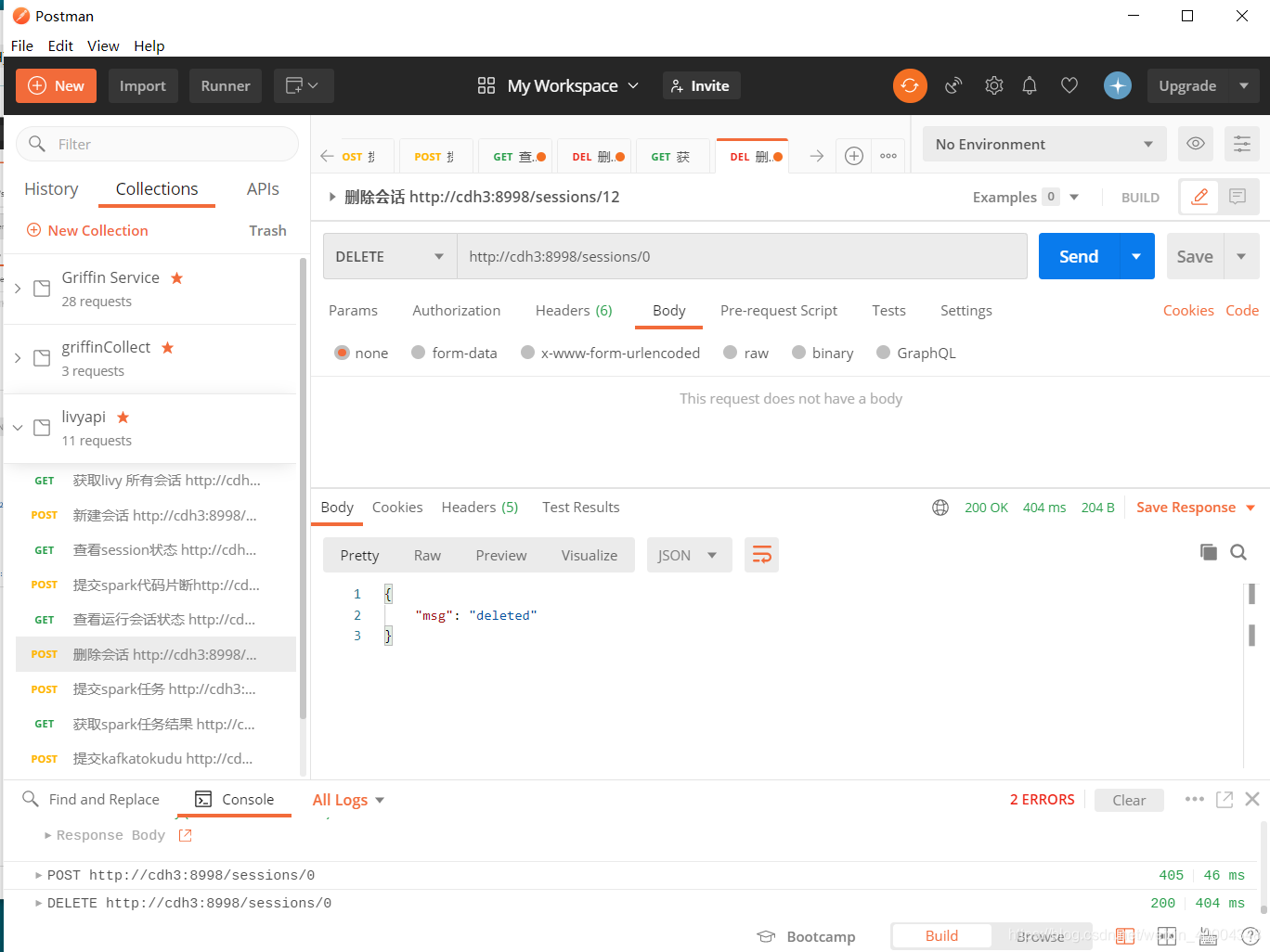
此时livy web界面为空。相当于kill了spark shell

2.批处理会话 livy rest API 测试
提前找到spark example 中的测试jar包spark-examples_2.11-2.4.0-cdh6.3.2.jar,put到hdfs 某个路径下,我的为 hdfs://cdh2:8020/jars/。我们要测试spark自带的SparkPi 测试包。默认为yarn client 模式运行,如果调整根据"conf": {“spark.master”:“yarn-client”} 进行调整。
2.1提交spark任务
http://cdh3:8998/batches
{
"file":"hdfs://cdh2:8020/jars/spark-examples_2.11-2.4.0-cdh6.3.2.jar",
"driverMemory":"512m",
"executorMemory":"512m",
"className":"org.apache.spark.examples.SparkPi",
"name":"Sparkpi"
}
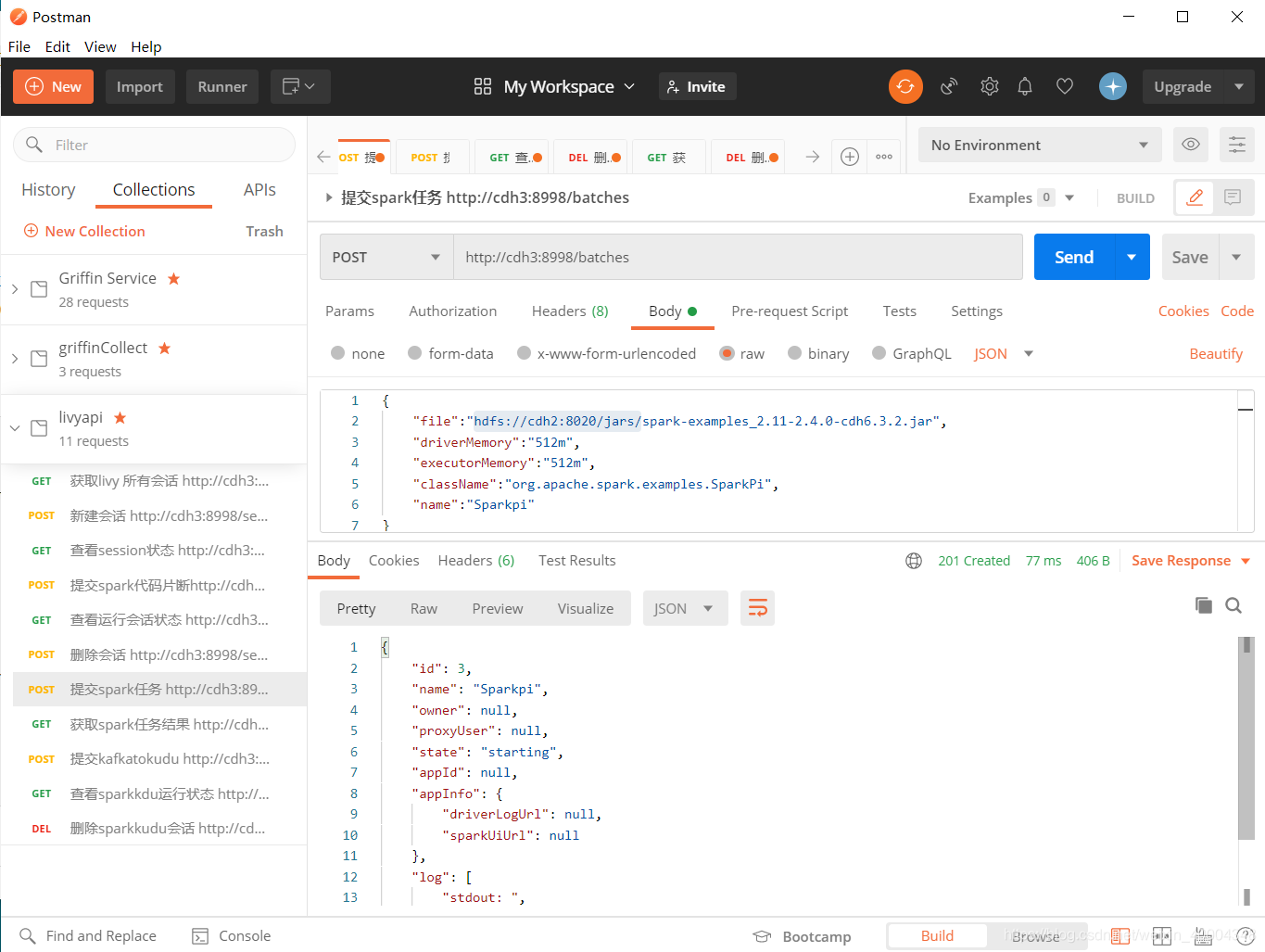
batch id 为3.
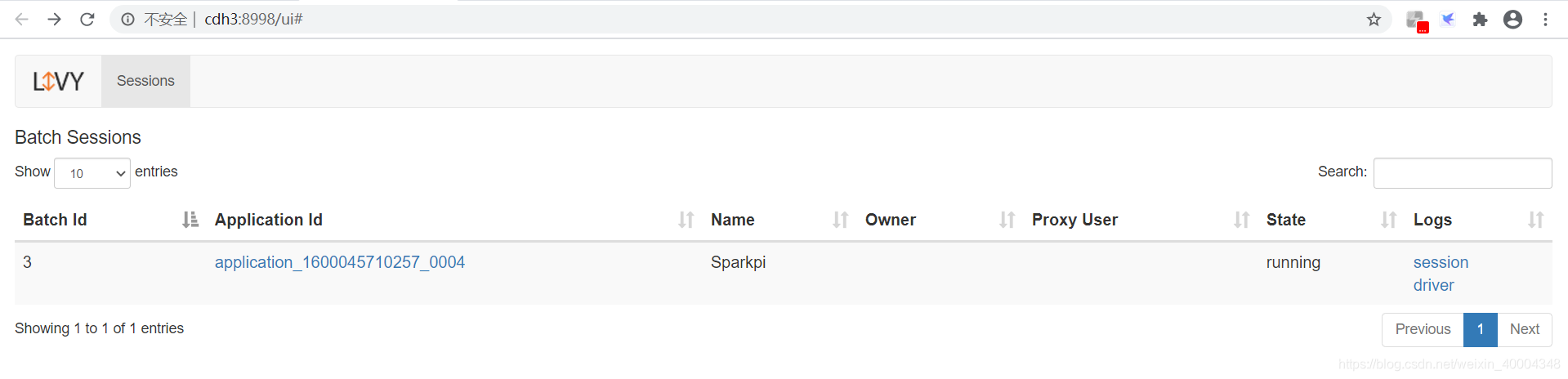
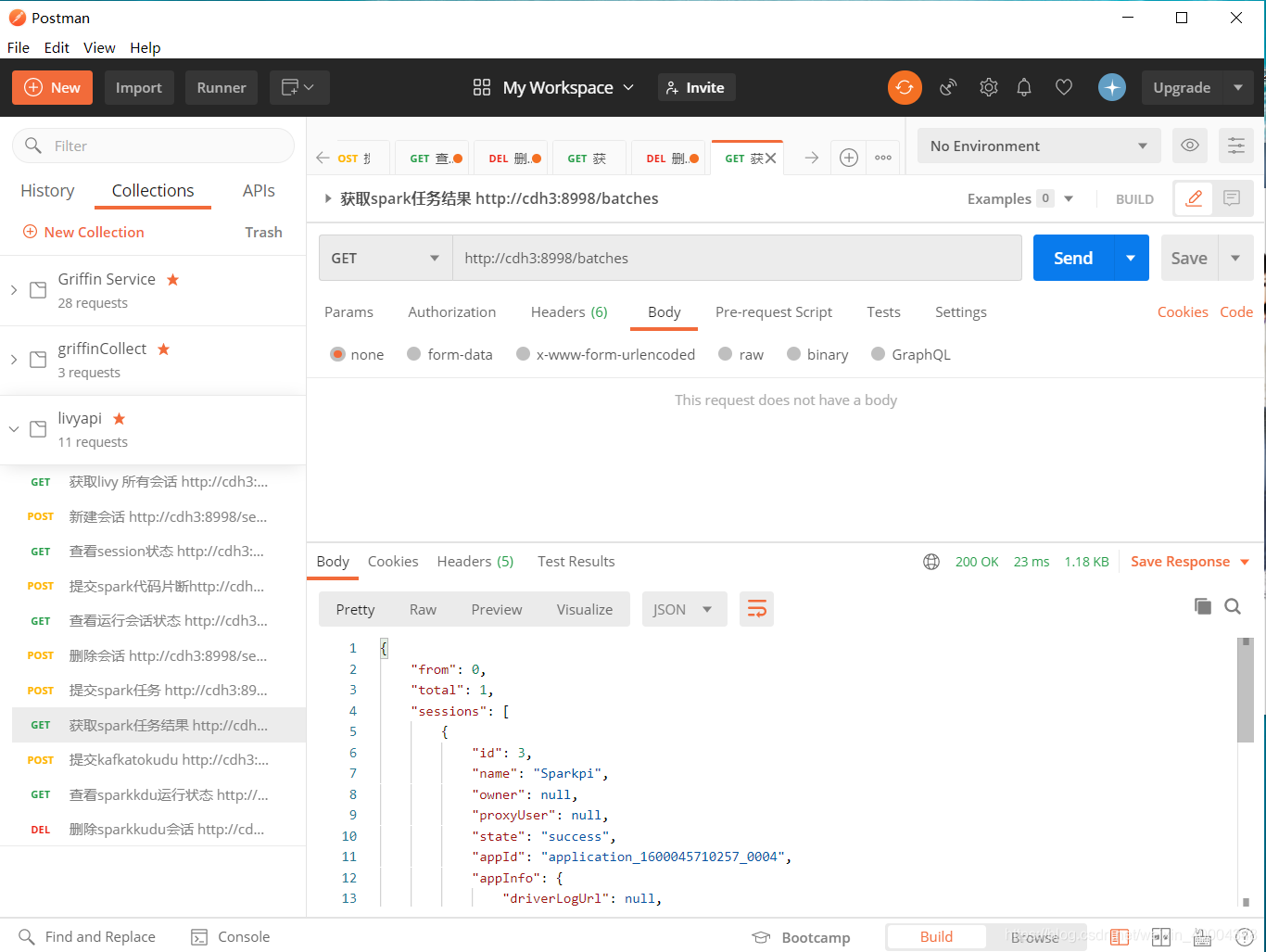
2.2 获取batch 处理结果
http://cdh3:8998/batches

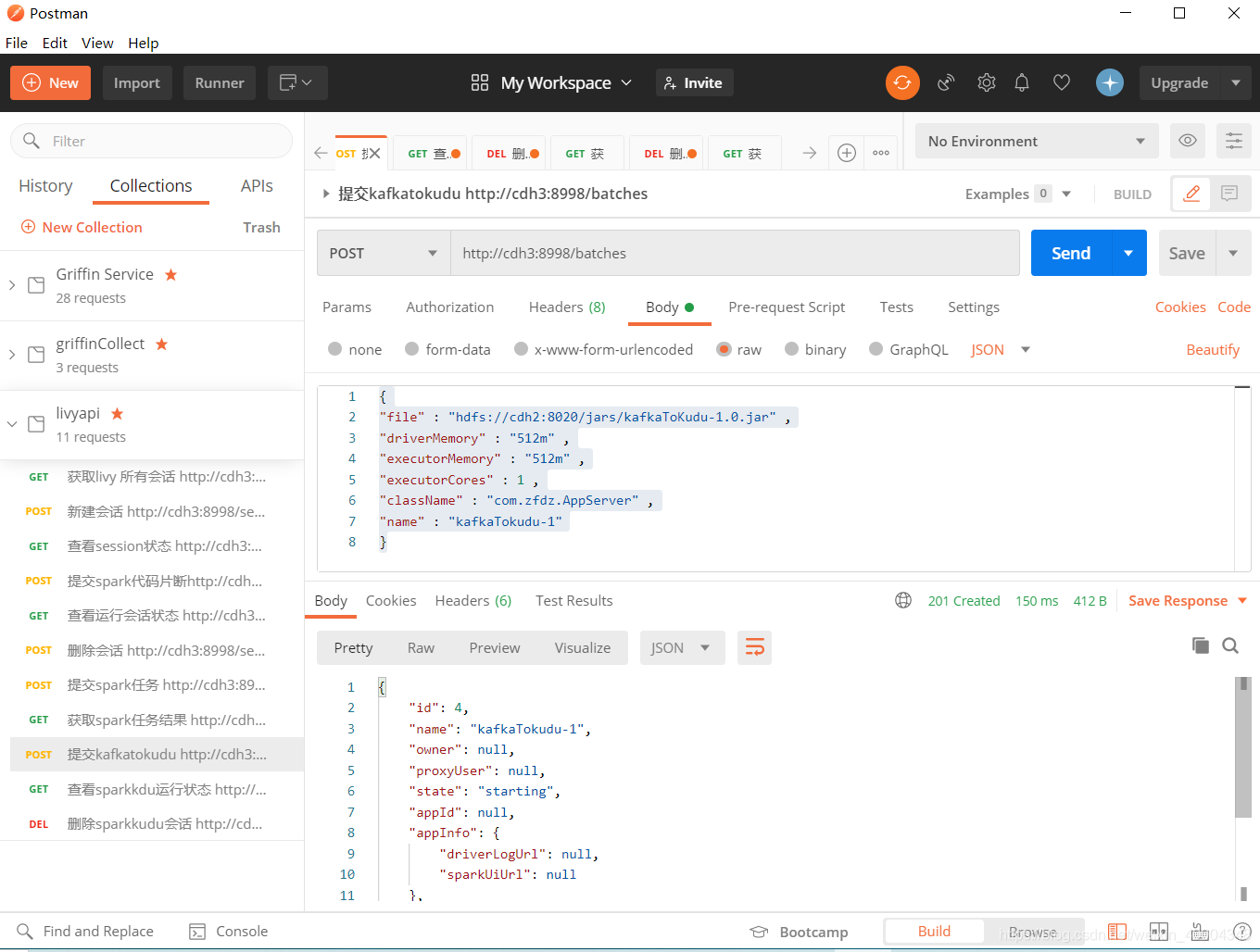
2.3 提交自己的spark streaming jar包
到hdfs://cdh2:8020/jars/下。我的jar为kafkaToKudu-1.0.jar。其他的参数可根据官网更多参数进行修改。
http://cdh3:8998/batches
{
"file" : "hdfs://cdh2:8020/jars/kafkaToKudu-1.0.jar" ,
"driverMemory" : "512m" ,
"executorMemory" : "512m" ,
"executorCores" : 1 ,
"className" : "com.zfdz.AppServer" ,
"name" : "kafkaTokudu-1"
}
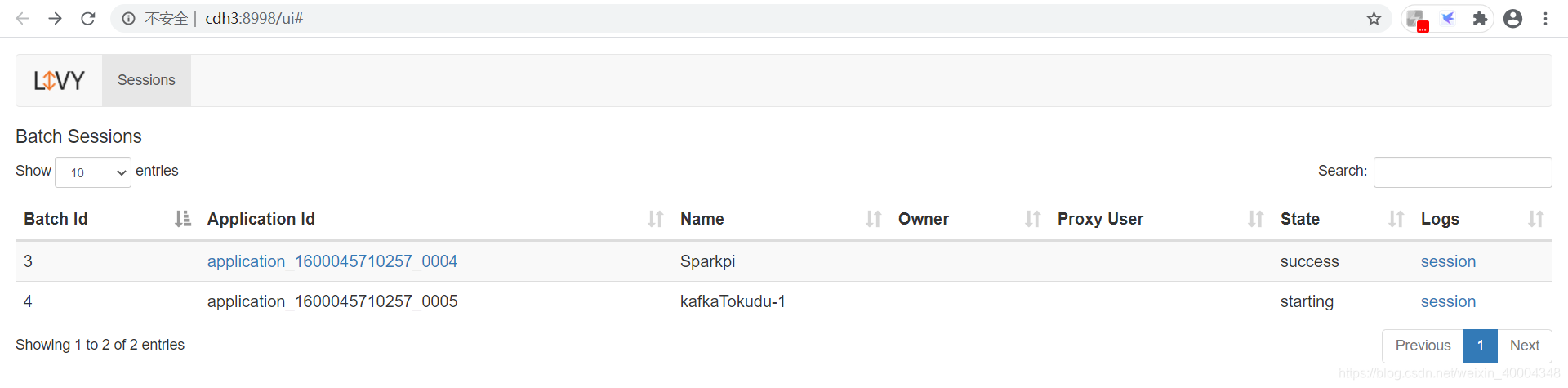
2.4 查看batch 会话运行状态
根据batch name进行查看
http://cdh3:8998/batches/livy-kafkaTokudu-1/state
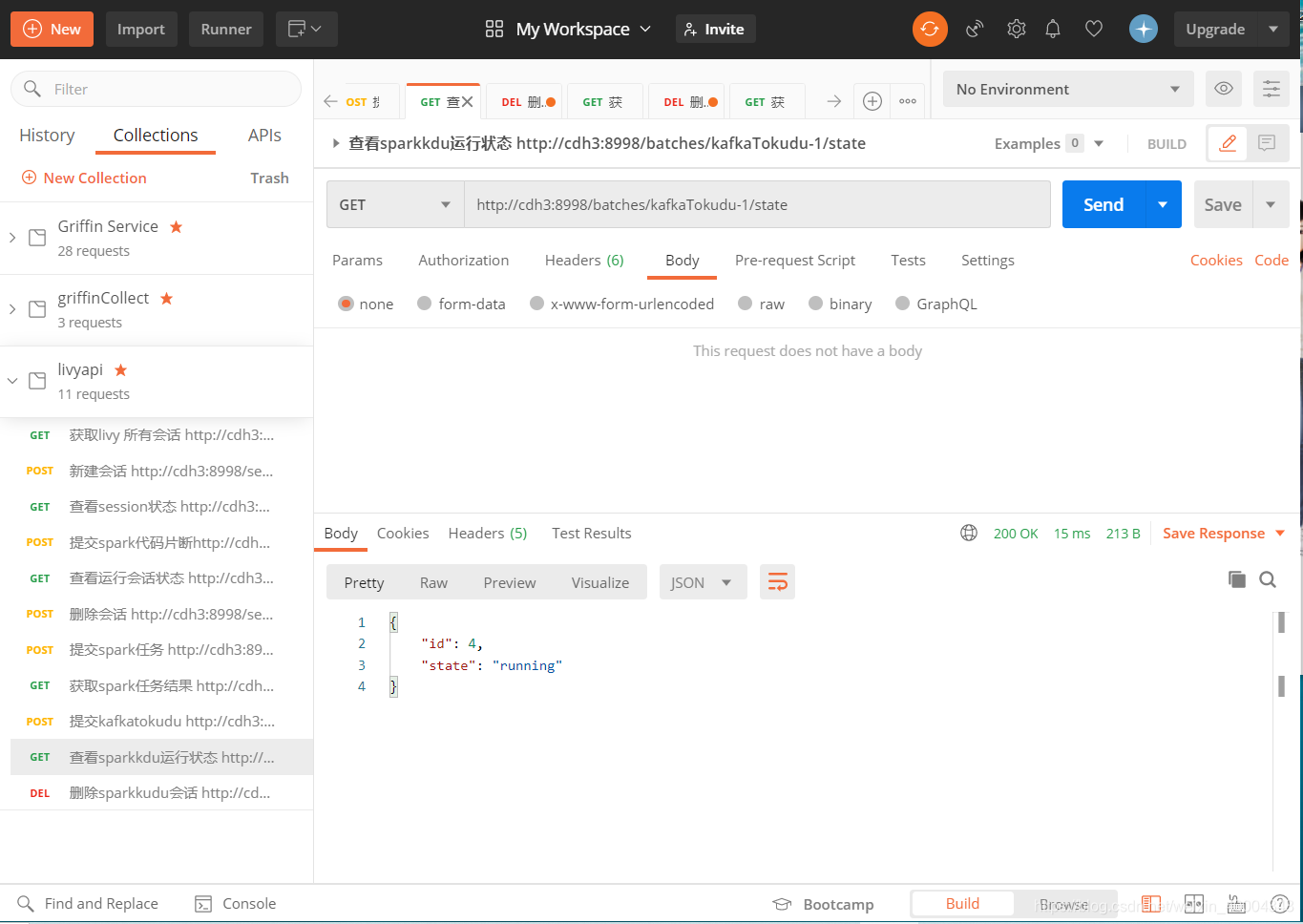
2.5删除batch会话
http://cdh3:8998/batches/kafkaTokudu-1

3.编写shell脚本,使用curl 对livy 提交sparkStreaming jar包进行封装:
kafka2kudu.sh 脚本如下 :
#!/bin/bash
def_hadoop_url="hdfs://cdh2:8020"
def_livy_url="http://cdh3:8998"
def_livy_batchname="livy-kafkaTokudu-client"
#执行环境配置
bin=`dirname "$0"`
bin=`cd "$bin"; pwd`
#参数解析 操作/start/status/stop
operate=$1
#判断输入参数是否为空
if [ ! -n "${operate}" ] ;then
echo "请输入操作动作参数:start 或者 status 或者 stop"
exit
fi
if [ $operate = "start" ] ; then
echo "send create batch session to livy"
curl -XPOST -H "Content-Type:application/json" "${def_livy_url}"/batches --data '{
"conf": {"spark.master":"yarn-client"},
"file": "'${def_hadoop_url}'/jars/kafkaToKudu-1.0.jar",
"className": "com.zfdz.AppServer",
"name": "'${def_livy_batchname}'",
"executorCores":1,
"executorMemory":"512m",
"driverCores":1,
"driverMemory":"512m",
"queue":"default"
}' | python -m json.tool
elif
[ $operate = "status" ] ; then
echo "send get status to livy"
curl -XGET "${def_livy_url}/batches/${def_livy_batchname}/state " | python -m json.tool
elif
[ $operate = "stop" ] ; then
echo "send kill batch session to livy"
curl -XDELETE ${def_livy_url}/batches/${def_livy_batchname} | python -m json.tool
else
echo "operate para is error,add [start/status/stop] commond pls."
exit
fi

batch name为自定义,不可重复。提交方式如果为yarn cluster,spark streaming 程序所需的配置文件也需要一并放入hdfs下。
以下链接写的很明白,参考链接:
https://blog.csdn.net/camel84/article/details/81990383?utm_source=blogxgwz9

















 3356
3356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









