





Myers'Diff
前言
写这篇文章已经拖了很久了,因为一直在准备后续的 Myers‘Diff之线性空间细化 。最初不知道是什么时候发现 DiffUtil 对比列表 item 数据进行局部刷新,git 文件对比都用到了这个算法。上个月刚好再一次看到了就想深入了解一下。但发现发现国内的博客和帖子,对这个算法的讲述内容比较少,每篇文章都讲述了作者自己认为重要的内容,所以有一个点搞不懂的话没法整体性的进行理解。刚开始我自己就有一个点没想清楚想了好几天,我觉得程序员不能怕算法,书读百遍其义自现,阅读算法代码也是如此,平时多思考偶尔的一点灵光出现会减少你死磕算法浪费的时间。
Myer差分算法
举一个最常见的例子,我们使用 git 进行提交时,通常会查看这次提交做了哪些改动,这里我们先简单定义一下什么是 diff :diff 就是目标文本和源文本之间的区别,也就是将源文本变成目标文本所需要的操作。Myers算法 由 Eugene W.Myers 在 1986 年发表在 《 Algorithmica》 杂志上的一篇论文中提出,是一个能在大部分情况产生最短的直观的diff 的一个算法。
定义
File A and File B
The diff algorithm takes two files as input. The first, usually older, one is file A, and the second one is file B. The algorithm generates instructions to turn file A into file B.(diff算法将两个文件作为输入。第一个通常是较旧的文件是文件A,第二个是文件B。算法生成指令以将文件A转换为文件B。)
Shortest Edit Script ( SES )
The algorithm finds the Shortest Edit Script that converts file A into file B. The SES contains only two types of commands: deletions from file A and insertions in file B.(该算法找到将文件A转换为文件B的最短编辑脚本。SES仅包含两种类型的命令:从文件A删除和在文件B中插入。)
Longest Common Subsequence ( LCS )
Finding the SES is equivalent to finding the Longest Common Subsequence of the two files. The LCS is the longest list of characters that can be generated from both files by removing some characters. The LCS is distinct from the Longest Common Substring, which has to be contiguous.(查找SES等同于找到两个文件的最长公共子序列。LCS是可以通过删除某些字符从两个文件生成的最长字符列表。LCS与最长公共子字符串不同,后者必须是连续的。)
示例
本文使用与本文相同的示例。文件A包含 ABCABBA,文件B包含CBABAC。这些被表示为两个字符数组:A []和B []。A []的长度为N,B []的长度为M。
我们就可以求解从A数组变成B数组的问题,转换成为求解从A字符串变成B字符串的问题(将抽象问题具现)。
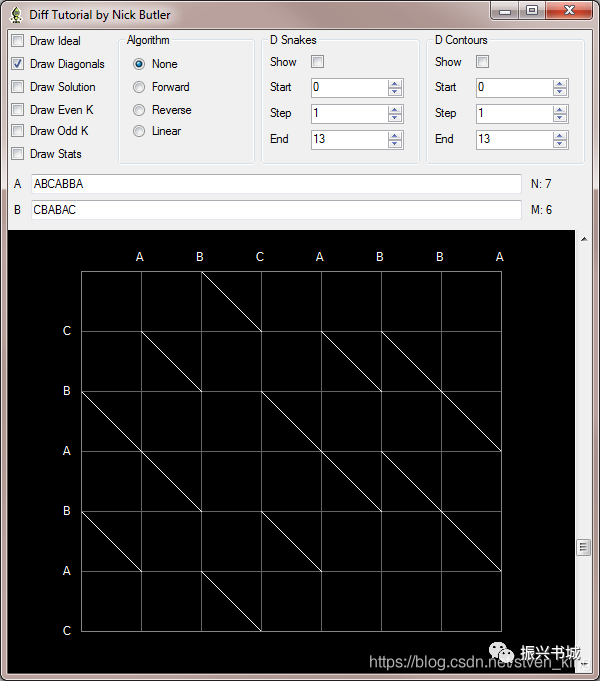
数组A沿
x轴放在顶部。
数组B沿
y轴向下放置。
PS:文章中的图都是由DiffTutorial软件制作而成,该应用程序是一种学习辅助工具。它显示算法各个阶段的图形表示。
解决方案:从左上角(0,0)到右下角(7,6)的最短路径。您始终可以水平或垂直移动一个字符。水平(右)移动表示从文件A中删除,垂直(向下)移动表示在文件B中插入。如果存在匹配的字符,则还可以对角移动,以匹配结束。解决方案是包含最多对角线的迹线。LCS是轨迹中的对角线,SES是轨迹中的水平和垂直移动。例如,LCS的长度为4个字符,SES的长度为5个差异。
snake: 一条snake代表走一步。例如从(0,0)->(0,1) / (0,0)->(1,0) / (0,1)->(0,2)->(2,4) 这分别为三条snake,走对角线不计入步数。
k line: k lines表示长的对角线,其中每个k = x - y。假设一个点m(m,n),那么它所在的k line值为m - n。
d contour: 每条有效路径(能从(0,0)到(m,n)的路径都称为有效路径)的步数。形象点,一条path有多个snake组成,这里d contours表示snake的个数。
贪婪算法
该算法是迭代的。它计算连续 d 的每条 k 线上最远的到达路径。当路径到达右下角时,将找到解决方案。
这里面有很重要的几点:
路径的终点必然在
k线上。迭代进行,所以k线的上一步操作是k+1向下移动或者k-1向右移动;计算连续的
d每条k线上最远的到达路径(偶数d的端点在偶数k线,奇数类似);路径到达右下角结束;
其中1和2都是在论文中进行了证明~!
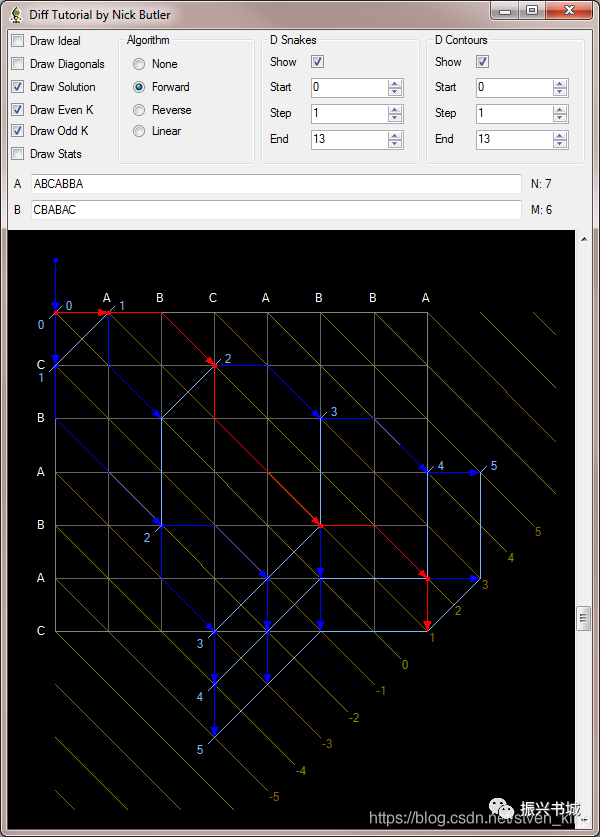
k line:棕色线是k的奇数值的k条线。黄线是k的偶数值的k线。snake:深蓝色的线条是蛇。红蛇显示溶液痕迹。d contours:淡蓝色的线是差异轮廓。例如,标记为“ 2”的直线上的三个端点全部具有2个水平或垂直移动。
外循环次数
从(x、y)组成的矩形左上角,到右下角。最长的路径莫过于所有对角线都不经过。也就是只走X和Y的长度即最大长度=N+M。for ( int d = 0 ; d <= N + M ; d++ )
内循环的次数
在此循环内,我们必须为每条k线找到最远的到达路径。对于给定的d,只能到达的k线位于[-d .. + d]范围内。当所有移动都向下时,k = -d 是可能的;当所有移动都在右侧时,k = + d 是可能的。for ( int k = -d ; k <= d ; k += 2 )
看到这里也许就有人产生疑问,为什么是k+=2。
这块有一个优化,文章前面说过
偶数d的端点在偶数k线,奇数类似。
解释:移动奇数步长(前进或者后退都行)最终位置一定在奇数的k线上,偶数步长的最终位置一定在偶数的k线上。
PS:这里让我纠结了好长时间,最后一下几点思考让我想的更加清楚:
从
零开始一步一步在k线上进行移动,一定是从零开始。这里的计算不是偶数加偶数得到的还是偶数,奇数加奇数得到的数是奇数或者偶数(这里是计算多个
+1或-1)。无论偶数还是奇数
+1或-1之后都会改变自己的奇偶性,所以d次操作之后的奇偶性由d的奇偶进行决定。由因为起点为偶数零,所以说偶数d的端点在偶数k线,奇数类似。
举例说明(d=3)
从d = 3的示例进行研究,这意味着k的取值范围是[-3,-1,1,3]。为了帮助您,我将示例中的snake的端点转录到下表中:
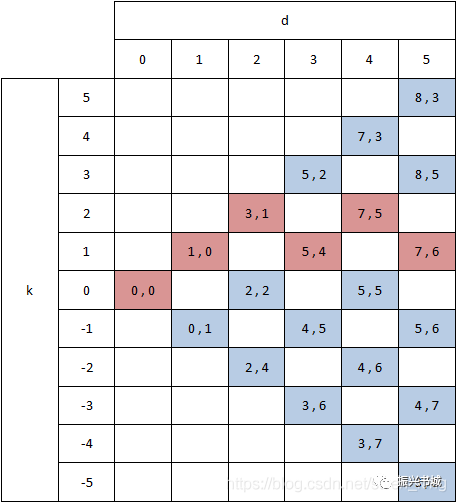
k = -3:这种情况下,只有当k = -2,d = 2时,向下移动一步(k = -4, d = 2这种情况不存在)。所以,我们可以这么来走,从(2,4)点开始向下走到(2,5),由于(2,5)和(3,6)之间存在一个对角线,可以走到(3,6)。所以整个snake是:(2,4) -> (2,5) -> (3,6)。
k = -1:当k = -1时,有两种情况需要来讨论:分别是k = 0,d = 2向下走;k = -2 ,d = 2向右走。
当k = 0,d = 2时,是(2,2)点。所以当从(2,2)点向下走一步,到达(2,3),由于(2,3)没有对角线连接,所以整个snake是:(2,2) -> (2,3)。
当k = -2 ,d = 2时,是(2,4)点。所以当从(2,4)点向右走一步,到达(3,4),由于(3,4)与(4,5)存在对角线,所以整个snake是:(2,4) -> (3,4) -> (4,5)。
在整个过程中,存在两条snake,我们选择是沿着k line走的最远的snake,所以选择第二条snake。
k = 1:当k = 1时,存在两种可能性,分别是从k = 0向右走一步,或者k = 2向下走一步,我们分别来讨论一下。
当k = 0,d = 2时,是(2,2)点。所以当从(2,2)向右走一步,到达(3,2),由于(3,2)与(5,4)存在对角线,所以整个snake是:(2,2) ->(3,2) ->(5,4)。
当k = 2,d = 2时,是(3,1)点。所以当从(3,1)向下走一步,到达(3,2)。所以这个snake是:(3,1) ->(3,2) ->(5,4)。
在整个过程中,存在两条snake,我们选择起点x值较大的snake,所以是:(3,1) ->(3,2) ->(5,4)。
k = 3:这种情况下,(k = 4, d = 2)是不可能的,所以我们必须在(k = 2,d = 2)时向右移动一步。当k = 2, d = 2时, 是(3,1)点。所以从(3,1)点向右移动一步是(4,1)点。所以整个snake是:(3,1) -> (4,1) -> (5,2).
算法实现
我们有两个循环,我们需要一个数据结构。
请注意,d(n)的解仅取决于d(n-1)的解。还请记住,对于d的偶数值,我们在偶数k行上找到端点,而这些端点仅取决于全部在奇数k行上的先前端点。对于d的奇数值也是如此。
我们使用称为V的数组,其中k为索引,终点的x位置为值。我们不需要存储y位置,因为我们可以根据x和k来计算它:y = x-k。同样,对于给定的d,k在[-d .. d]范围内。
bool down = ( k == -d || ( k != d && V[ k - 1 ] < V[ k + 1 ] ) );
如果k = -d,我们一定是向下移动了;如果k = d,我们一定是向右移动了。
对于正常的中间情况,我们选择从x值较大的任何相邻行开始。这保证了我们到达k线上尽可能远的点。
1V[ 1 ] = 0;
2for ( int d = 0 ; d <= N + M ; d++ )//外循环,进行多少次代表有多少个snake和V数组
3{
4 for ( int k = -d ; k <= d ; k += 2 )//内循环
5 {
6 // down or right?
7 bool down = ( k == -d || ( k != d && V[ k - 1 ] 1 ] ) );
8 int kPrev = down ? k + 1 : k - 1;//如果向下,那么上一步应该是k+1
9 // start point,上一个点
10 int xStart = V[ kPrev ];//v[k]=x
11 int yStart = xStart - kPrev;//y=x-k
12 // mid point,下一个点
13 int xMid = down ? xStart : xStart + 1;
14 int yMid = xMid - k;
15 // end point
16 int xEnd = xMid;
17 int yEnd = yMid;
18 // follow diagonal
19 int snake = 0;//是否有对角线继续往重点走
20 while ( xEnd 21 {
22 xEnd++; yEnd++; snake++;
23 }
24 // save end point
25 V[ k ] = xEnd;
26 // check for solution
27 if ( xEnd >= N && yEnd >= M ) /* solution has been found */
28 }
29}
上面的代码寻找一条到达终点的snake。因为V数组里面存储的是在k line最新端点的坐标,所以为了寻找到所有的snake,我们在d的每次循环完毕之后,从d(Solution)遍历到0。如下:
1IList Vs; // saved V's indexed on d 2IList snakes; // list to hold solution 3//从后往前推,最后一条snake是到达终点必须经过的路线。 4POINT p = new POINT( N, M ); // start at the end 5for ( int d = vs.Count - 1 ; p.X > 0 || p.Y > 0 ; d-- ) 6{ 7 var V = Vs[ d ];//内循环产生的数据 8 int k = p.X - p.Y;//本次循环的起点的k线 9 // end point is in V10 int xEnd = V[ k ];11 int yEnd = x - k;12 // down or right?13 bool down = ( k == -d || ( k != d && V[ k - 1 ] 1 ] ) );14 int kPrev = down ? k + 1 : k - 1;//上一个snake的k线15 // start point16 int xStart = V[ kPrev ];17 int yStart = xStart - kPrev;18 // mid point19 int xMid = down ? xStart : xStart + 1;//中间点20 int yMid = xMid - k;21 snakes.Insert( 0, new Snake( /* start, mid and end points */ ) );22 p.X = xStart;23 p.Y = yStart;24}时间复杂度: 期望为O(M+N+D^2),最坏情况为为O((M+N)D) 。
有兴趣的可以继续阅读下一篇文章 Myers‘Diff之线性空间细化 。
算法实践:DiffUtil和它的差量算法
参考链接:
代码:diff-match-patch
diff2论文
Myers diff alogrithm:part 1
Myers diff alogrithm:part 2
文章到这里就全部讲述完啦,若有其他需要交流的可以留言哦~!~!
想阅读作者的更多文章,可以查看我 个人博客 和公共号:















 4490
4490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









