





0 背景
在我们使用pandas进行数据处理的时候,有时候发现文件在本地明明不大,但是用pandas以DataFrame形式加载内存中的时候会占用非常高的内存,本文即解决这样的问题。
1 原因
如果是计算机相关专业的同学,你应该知道int8,int16,int64的区别。如果你忘记了,那我们可以举一个例子。内存相当于仓库,数字相当于货物,数字需要装到箱子里才能堆到仓库。现在有小,中,大三种箱子,我们一个个数字用小箱子就可以装好,然后堆到仓库去,而现在pandas的处理逻辑是,如果你不告诉用哪个箱子,我都会用最大的箱子去装,这样仓库很快就满了。OK,这就是有时候DataFrame内存占用过高的原因。
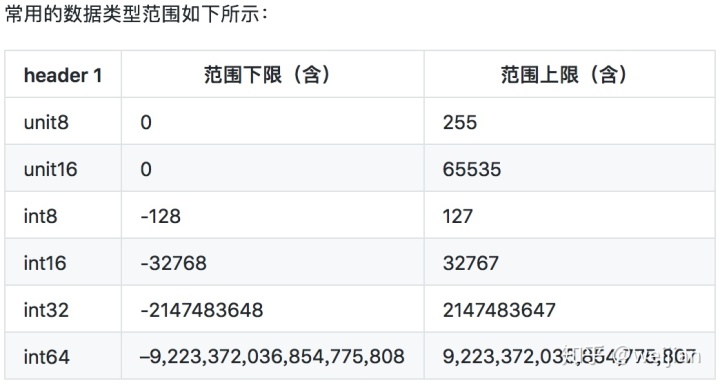
其他信息可以通过numpy中的函数来查看范围
import numpy as np
# 查看int16的范围
ii16 = np.iinfo(np.int16)
ii16.min
-32768
# 与iinfo相应,finfo可以查看float类型的范围
fi16 = np.finfo(np.float16)
fin16.min
-3.4028235e+382 解决方法
第一种
当我们明确知道要加载数据的范围,使用pd.read_table读取数据时,可以用其中的dtype参数来手动指定类型。比如某一列的数据范围肯定在0~255之中,那么我们可以指定为np.uint8类型,如果不手动指定的话默认为np.int64类型,这之间的差距巨大。
第二种
如果数据列数太多,或者不清楚数据具体范围的话这里提供一个脚本,可以自动判断类型,并根据类型修改数据范围。虽然我认为这个脚本已经可以cover大部分的情况,但是仍然强烈建议你在读懂这个脚本的基础上,根据你的数据修改成更适合你数据的形式。
注意:代码最初源于这里Reducing DataFrame memory size by ~65%,在Apache 2.0协议下,我对其中不太合理的地方做了些修改。
# @from: https://www.kaggle.com/arjanso/reducing-dataframe-memory-size-by-65/code
# @liscense: Apache 2.0
# @author: weijian
def reduce_mem_usage(props):
# 计算当前内存
start_mem_usg = props.memory_usage().sum() / 1024 ** 2
print("Memory usage of the dataframe is :", start_mem_usg, "MB")
# 哪些列包含空值,空值用-999填充。why:因为np.nan当做float处理
NAlist = []
for col in props.columns:
# 这里只过滤了object格式,如果你的代码中还包含其他类型,请一并过滤
if (props[col].dtypes != object):
print("**************************")
print("columns: ", col)
print("dtype before", props[col].dtype)
# Integer does not support NA, therefore Na needs to be filled
if not np.isfinite(props[col]).all():
NAlist.append(col)
props[col].fillna(-999, inplace=True) # 用-999填充
# 判断是否是int类型
isInt = False
mmax = props[col].max()
mmin = props[col].min()
# test if column can be converted to an integer
asint = props[col].fillna(0).astype(np.int64)
result = np.fabs(props[col] - asint)
result = result.sum()
if result < 0.01: # 绝对误差和小于0.01认为可以转换的,要根据task修改
isInt = True
# make interger / unsigned Integer datatypes
if isInt:
if mmin >= 0: # 最小值大于0,转换成无符号整型
if mmax <= np.iinfo(np.uint8).max:
props[col] = props[col].astype(np.uint8)
elif mmax <= np.iinfo(np.uint16).max:
props[col] = props[col].astype(np.uint16)
elif mmax <= np.iinfo(np.uint32).max:
props[col] = props[col].astype(np.uint32)
else:
props[col] = props[col].astype(np.uint64)
else: # 转换成有符号整型
if mmin > np.iinfo(np.int8).min and mmax < np.iinfo(np.int8).max:
props[col] = props[col].astype(np.int8)
elif mmin > np.iinfo(np.int16).min and mmax < np.iinfo(np.int16).max:
props[col] = props[col].astype(np.int16)
elif mmin > np.iinfo(np.int32).min and mmax < np.iinfo(np.int32).max:
props[col] = props[col].astype(np.int32)
elif mmin > np.iinfo(np.int64).min and mmax < np.iinfo(np.int64).max:
props[col] = props[col].astype(np.int64)
else:
# 注意:这里对于float都转换成float64,需要根据你的情况自己更改
props[col] = props[col].astype(np.float64)
print("dtype after", props[col].dtype)
print(props.describe())
print("********************************")
print("___MEMORY USAGE AFTER COMPLETION:___")
mem_usg = props.memory_usage().sum() / 1024**2
print("Memory usage is: ",mem_usg," MB")
print("This is ",100*mem_usg/start_mem_usg,"% of the initial size")
return props, NAlist其中NAlist表明是含有空值的列表。经试验,效果明显,对于数值型特征非常多的数据,至少可以减少50%以上的内存占用。
Reference
1 https://www.kaggle.com/arjanso/reducing-dataframe-memory-size-by-65/code














 951
951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









