





当为一个特别的任务设计并发代码的时候,你需要事先考虑每个描述的问题的程度将取决于任务。为了演示它们是如何应用的,我们将看看C++标准库中三个函数并行版本的实现。这将给你一个类似的构造基础,提供了考虑问题的平台。作为奖励,我们也有可用的函数实现,可用来帮助并行一个更大的任务。
我选择这些实现主要是用来演示特别的方法而不是成为最高水平的实现。在并行算法学术文献或者在多线程库例如Inter's Threading Building Blocks中可以找到更高程度的实现,它们更好地利用了可获得的硬件并发性。
概念上最简单的并行算法是std::for_each 的并行版本,我们就先从它开始。
8.5.1 std::for_each的并行实现
std::for_each 在概念上很简单,它轮流在范围内的每个元素上调用用户提供的函数。std::for_each 的并行实现和串行实现的最大区别就是函数调用的顺序。std::for_each 用范围内的第一个元素调用函数,然后是第二个,以此类推。然而使用并行实现就不能保证元素被处理的顺序,它们可能(实际上我们希望)被并发处理。
为了实现并行版本,你只需要将这个范围划分为元素集合在每个线程上处理。你事先知道了元素数量,因此你可以在处理开始前划分数据(参见8.1.1节)。我们假设这是唯一在运行的并行任务,那么就可以使用sta::thread::hardware_ concurrency()来决定线程的数量。你也知道元素可以被独立地处理,因此你可以使用临近的块来避免假共享(参见8.2.3节)。
这个算法与8.4.1节中描述的std::accumulate 的并行版本在概念上是类似的,但是不计算每个元素的和,你只要应用具体函数。尽管你可能推测这会大大简化代码,因为它不返回结果。如果你想传递异常给调用者,你仍然需要使用std::packaged_task 和std::future方法在线程间传递异常。一个简单的实现如清单8.7所示。
清单8.7 std::for_each的并行版本

这段代码的基础结构与清单8.4中的代码是一样的。关键的不同之处在于futures向量存储了
std::future 1,因为工作线程不返回值,并且在这个任务上使用一个简单lambda函数激活了从block_start到block_end范围上的函数f 2。这就避免了将范围传递给线程构造函数3。因为工作线程不返回值,调用future[i].get() 。4只提供取回工作线程抛出的异常的方法,如果你不希望传递异常,那么你就可以省略它。
正如你的std::accumulate 的并行实现可以通过使用std:async被简化,因此你的parallel_for_each也可以被简化。它的实现如清单8.8所示。
清单8.8使用std::async的std::for_each的并行版本
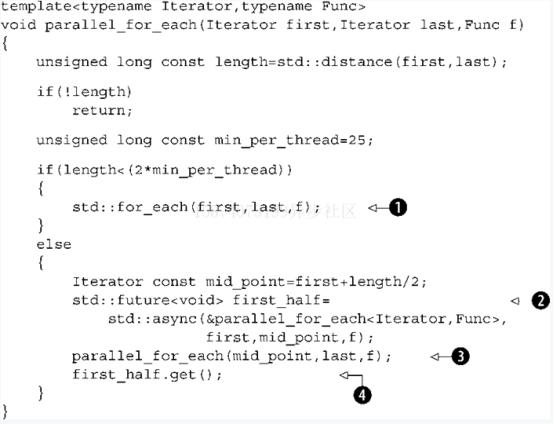
如同清单8.5中基于std::async 的 parallel_accumulat e一样,你递归地划分数据而不是在执行前划分数据,因为你不知道库会使用多少线程。如以前一样,每一步都将数据划分为两部分,异步运行前半部分并且直接运行后半部分直到剩下的数据太小而不值得划分,在这种情况下会调用std::for_each 1。使用std::async 和get()成员函数std::future 4提供了异常传播语义。
让我们从必须在每个元素上执行相同操作的算法转移到稍微复杂的例子std::find。
8.5.2 std::find的并行实现
std::find是下一个考虑的有用的算法,因为它是不用处理完所有元素就可以完成的几个算法之一。例如,如果范围内的第一个元素符合搜索准则,那么就不需要检查别的元素。稍后你将看到,这是性能的一个重要属性,并且对设计并行实现有直接影响。这是数据读取部分可能影响代码设计的一个特殊例子(参见8.3.2节)。这类别的算法包括std::equal和std::any_of。
如果你和你的妻子或者搭档在阁楼的两箱纪念品中寻找一张旧相片,如果你找到了相片就应该让他们也停止寻找。你要让他们知道你已经找到了相片(可以通过呼喊,“找到了") ,这样他们就可以停止寻找并且做别的事情。很多算法的天性是处理每个元素,因此它们没有呼喊找到了"。对于算法例如std::find ,早日完成的能力是一个重要的特性并且不浪费任何事情。因此你需要设计你的代码来使用这个特性-当知道结果的时候用一些方式中断别的任务,因此代码不需要等待别的工作线程处理剩下的元素。
如果你不中断别的线程,电行版本比并行版本的性能更好,因为串行算法一旦找到匹配项就停止搜索并且返回。例如,如果系统可以支持四个并发线程,每个线程将检查范围内四分之一的元素,并且我们的并行算法大约花费单个线程四分之一的时间来检查每个元素。如果匹配的元素位于范围内的前四分之一,串行算法会首先返回,因为它不需要检查剩下的元素。
你可以中断别的线程,一种方法是通过使用一个原子变量作为一个标志,并且在处理完每个元素后检查这个标志。如果设置了标志,就代表有一个线程发现了匹配项,因此就可以终止执行并且返回了。用这种方法中断别的线程,你保持了你不需要处理每个值的特性,因此在更多的情况下与串行版本相比提高了性能。这种方法的缺点是原子载入变成慢动作,这就会妨碍每个线程的前进。
关于如何返回值和如何传递异常你有两个选择。你可以使用future数组,使用sta::packaged_task 来转移值和异常,然后在主线程中处理返回的结果;或者你使用std::promise 来从工作线程中直接设置最终结果。如果你希望在第一个异常处停止(即使你没有处理完所有元素) ,你可以使用std::promise来设置值和异常。另一方面,如果你希望允许别的工作线程继续搜索,你可以使用std::packaged_task ,存储所有的异常,那么没有发现匹配项的时候就重新抛出其中之一。
在这种情况下,我选择使用std::promise ,因为行为更匹配std::find 。这里要注意的一件事情就是要搜索的元素不在提供的范围内。因此在从future得到结果之前你需要等待所有线程结束。如果你在future上阻塞了并且没有这个值的话,你就会永远等待。结果如清单8.9所示。
清单8.9 并行find算法的一种实现



清单8.9的主函数与之前的例子很相似。这次,在本地find_element类的函数调用操作上完成工作1。这个循环访问给定的块的每个元素,每一步都检查标志2。如果找到匹配项,就在promise中设置最后的结果3并且在返回前设置done_flag 4。
如果抛出异常,就可以被捕获5,并且在设置done_flag前在promise 中存储异常6。如果promise已经被设置了,再设置值就有可能抛出异常,因此你捕获并且抛弃发生在这里的异常7。
这就意味着如果一个线程调用find_element ,要么找到匹配项要么抛出异常,此时所有别的线程都会看到done_flag被设置了并且停止执行。如果多个线程同时找到匹配项或者抛出异常,它们就会在设置
promise 值的时候产生竞争。但是这是一个没有危害的竞争条件,无论哪一个线程成功都会成为名义上的“第一个"并且是一个可接受的结果。
回顾主函数parallel_find本身,你用promise 8和flag 9来停止搜索,这两者都传递给在这个范围内搜索的新线程11。主线程也使用find_element来搜索剩下的元素12。我们已经说过,你在检查结果之前需要等待所有线程结束,因为可能没有匹配的元素。你通过在块中附入线程连接的代码来完成10,因此当你检查标志来看看是否发现匹配项的时候,所有线程都被联合起来了13。如果发现匹配项,你就可以通过在std: :future 中调用 get() 得到结果或者抛出存储的异常14。
同样,这个实现假设你将使用所有可获得的硬件线程或者你有别的方法来决定线程数量,用来提前在线程间划分工作。跟以前一样,在使用C++标准库的自动扩展功能的时候,你可以使用std::async和递归数据划分来简化你的实现。使用std::async的parallel_find实现如清单8.10所示。
清单8.10使用std::async的并行查找算法的实现

如果你找到匹配项就结束查找,意味着你需要引入一个在线程间共享的标志,用来表示已经找到该匹配项。因此这就需要传递给所有递归调用。实现它最简单的方法就是通过在实现函数上1 附加参数——引用done标志,这是从主入口点传递进来的12。
核心实现在类似的代码行里继续执行。与很多实现相同,你在单线程上设置处理项的最小值2。如果你不能将它划分为都至少达到设置的大小的两部分,就在当前线程上运行所有的事情3。实际算法是处理具体范围的简单循环,一直循环直到范围结束或者设置了done标志4。如果你查找到匹配项,就在返回前设置done标志5 。如果你停止查找,要么因为你已经到达范围的未端,要么因为另一个线程设置了done标志。你返回last用来表示在这里没有匹配项6。
如果范围可以被划分,你在使用std::async 前首先发现中点7,以便在范围的后半部分进行查找8,小心使用std::ref来传递done标志的引用。同时,你可以通过直接递归调用在范围的前半部分进行查找9。如果原来的范围太大的话,这个异步调用和直接递归可能导致进一步的划分。
如果直接搜索返回mid_point ,那么就没有找到匹配项,你就需要得到异步搜索的结果。如果那部分没有发现结果,结果就将是last ,这是正确的返回值表明没有查找到这个值10。如果"异步的"调用被延迟而不是真正的异步,它在调用get() 的时候才真正运行,在这种情况下,如果在后半部分查找到了就跳过搜索范围的前半部分。如果异步搜索已经在另一个线程上运行了, async_result变量的析构函数将等待线程完成。这样就不会有任何泄露线程。
如同以前一样,使用std::async提供了异常安全和异常传递特性。如果直接递归抛出异常, future的析构函数将确保运行异步调用的线程在函数返回前就结束了。并且如果异步调用抛出异常,这个异常就通过get()调用传递10。使用一个try/catcn 块是为了在异常上设置done标志并且确保如果抛出异常的话所有线程很快终止11,没有它,实现仍然是正确的,但是会继续检查元素直到每个线程都结束了。
这个算法的两种实现与另一种并行算法共享的主要特点就是不再保证项目按照从std::find得到的顺序来处理。如果你想并行算法这一点是很基础的。如果顺序很重要的话,你就不能并发处理元素。如果元素是独立的,就可以使用parallel_for_each 。但是这意味着你的 parallel_find可能返回范围尾部的元素,即使它与范围头部的元素匹配。
好了,你已经处理了并行化std::find 。正如我在这一节开头说的那样,存在别的类似算法可以在不处理每个数据元素的情况下完成,并且可以使用同样的方法。我们将在第9章中进一步讨论中断线程的问题。
为了完成我们的例子,我们将从不同的方面来考虑并且看看std::partial_sum 。这个算法是一个很有趣的并行算法并且强调了一些附加的设计选择。
8.5.3 std::partial_sum的并行实现
std::partial_sum 计算了一个范围内的总和,因此每个元素都被这个元素与它之前的所有元素的和所代替。所以序列1、2、3、4、5就变成1,(1+2)=3、(1+2+3)=6、(1+2+3+4)=10、(1+2+3+4+5)=15,它的并行化是很有趣的,因为你不能将范围划分为块然后单独计算每个块。例如,第一个元素的原始值需要加到每一个别的元素上。
一种用来决定范围内部分和的方法就是计算独立块的部分和,然后将第一个块中计算得到的最后一个元素的值加到下一个块的元素中,并以此类推。如果你有元素1,2,3,4,5,6,7,8,9并且你将它分成三个块,首先你得到{1,3,6}, {4,9,15}、{7,15,24}。如果你将6加到第二个块的所有元素上,你就得到{1,3.6}、 {10,15,21}、{7, 15,24}。然后你将第二个块的最后一个元素{21}加到第三个块的元素上,这样最后一个块得到最后的值:{1,3,6}、 {10,15,21}、{28,36,55}。
同原始划分成块一样,也可以并行加上前一个块的部分和。如果每个块的最后一个元素首先被更新,那么当第二个线程更新下一个块的时候,第一个线程可以更新这个块中剩下的元素,并且以此类推。当列表中的元素多于处理核的时候,这种方法很有效,因为每个核每一步都要处理大量元素。
如果你有很多处理核(同元素数量一样,或者多于元素数量) ,这种方法就不是很有效了。如果你在处理器间划分工作,第一步以元素对结束工作。这这种条件下,这种进一步传递结果意味着很多处理器会等待,因此你需要给它们分配工作。你可以采用另一种方法对待这个问题。你做部分传递,而不是从一个块到下一个块做全部和的传递。首先像之前一样求和相邻的元素,然后将这些和加到与它相隔两个的元素上,然后再将得到的值加到与它相隔四个的元素上,以此类推。如果你以同样的九个元素开始,第一轮后你得到1,3,5,7,9,11,13,15,17,这就得到前两个元素最后的值。第二轮后你得到1,3,6,10,14,18,22,26,30 ,它的前四个元素是正确的。第三轮后你得到1,3,6,10,15,21,18,36,44,它的前八个元素是正确的。第四轮后你得到1,3,6,10,15,21,18,36,45,这就是最终答案。尽管它比第一种方法的总步骤数要多,但是如果你有很多线程的话,它有更大的余地来并行化,每个处理器每一步都能更新一个入口。
总的说来,第二种方法执行log2(N)个步骤,每一个步骤执行大约N个操作(每个线程处理一个) ,其中N是表中的元素数量。第一种算法中,每个线程为分配给它的块的最初分段求和执行N/K个操作,然后为进一步的传递执行个操作N/K,k是线程数量。因此从总的操作数来说,第一种方法是O(N) ,第二种方法是O(N log(N))。尽管如此,如果你的处理器与列表中的元素一样多,那么第二种方法中每个处理器只需要log(N个操作。而当K很大时,第一种方法本质上是串行操作,因为需要进一步传递值。对于拥有很少处理单元的系统,第一种方法可以更快结束,而对于大规模并行系统,第二种方法可以更快结束。8.2.1节讨论了这个问题的一个极端的例子。
无论如何,先不考虑效率问题,我们来看一些代码。清单8.11所示的是第一种方法。
清单8.11 通过划分问题来并行计算分段的和


在这个例子中,总体结构与之前的代码是一样的,划分问题为块,每个线程拥有最小化的块尺寸12。在这种情况下,与线程向量一样13,你有一个promise向量14用来存储块中最后一个元素的值,并且还有一个future向量15,用来得到前一个块的最后一个值。你可以保留future的空间16来避免在生成线程的时候再分配,因为你知道将有多少线程。
主循环与以前的一样,只是这次你希望迭代器指向每个块中的最后一个元素本身,而不是通常情况下那样指向最后元素的后继17,因此在每个范围你都可以传递最后一个元素。真正的处理是在process_chunk 函数对象中完成的,我们稍后再分析。需要给的参数包括这个块的开始和结束的迭代器,先前范围的终值(如果存在的话) ,这个范围的终值存放的位置18。
产生线程后,你就可以更新这个块的起点,记住将它的值加一使它位于最后一个元素之后19,并且将当前块的最后一个值的future存储到future向量中,这样下一次循环的时候就可以得到它20。
在你处理最后一个块之前,你需要得到最后一个元素的迭代器21 ,这样你就可以传递到process_chunk 中22, std::partial_sum不返回值,因此一旦最后一个块被处理了,你不需要做任何操作。当所有线程结束的时候这个操作就完成了。
现在我们来看看 process_chunk 函数对象在整个工作中所起的作用1。首先在整个块上调用
sta::partial_sum ,包括最后一个元素2,但是然后就需要知道这是否为第一个块3 。如果这不是第一个块,那么在先前块中就有previous_end_value ,因此你就需要等待这个值
在这个实现中,你构造了一个 barrier ,它具有一定数量“座位"1,存储在count变量中。最初,屏障中spaces的数量与count相等。当每个线程等待的时候, spaces的数量就会减1 3。当它的值为零的时候,spaces的值就会重置为count 4 ,并且generation 的值增一来给别的线程发信号表示它们可以继续执行5。如果空闲spaces 的数量没有达到零,你就必须等待。这个实现使用一种简单旋转锁6,检查在wait()开始的时候得到的值。因为当所有线程到达屏障的时候才会更新generation 的值5,等待的时候调用yield() 7,因此在一个繁忙的等待中,等待的线程不会独占CPU。
当我说这个实现是简单的,我的意思是它使用一个旋转锁,因此它不适合线程可能等待很长时间的情况。并目如果在任何一个时间有多于 count 数量的线程可能调用wait() ,那么它就不起作用了。如果你想处理这些情况中的任何一种,你就必须使用一个更健壮性(但是更复杂)的实现来代替。我遵循了在原子变量上的顺序连续操作,因为这使得事情更容易解释,但是你可以放松一些顺序约束。在大规模并发结构上,这样的全局同步是代价很高的,因为缓存线持有屏障的状态必须在所有涉及到的线程间穿梭(参见8.2.2节) ,因此你必须注意确保在这里这是最好的选择。
无论如何,在这里这就是你所需要的,你有固定数量的线程在循规蹈矩的循环中运行。当然,这只是几乎固定数量的线程。你可能记得,在一些步骤后,列表开始的项获得它的最终值。这就意味着要么你保持这些线程循环直到处理完整个范围,要么你需要允许屏障处理线程退出并且减少count 。我倾向于后面一种选择,因为它避免了使线程只是循环而不做任何有用的工作直到最后一步完成。
这就意味着你需要将count变成一个原子变量,因此你可以从多个线程更新它而不需要额外的同步。
std: ;atomic count;
它的初始化是一样的,但是现在当你重置spaces的值的时候就必须明确在count 中1oad()。
spaces=count.load();
这些都是在wait() 上所做的改变;现在你需要一个新的成员函数来减少count 。我们称之为
done_waiting() ,因为一个线程声称在等待的时候完成它。

你做的第一件事是递减count 的值1,这样下一次重置spaces就反映新的等待线程的数量。然后你需要将空闲spaces 的数目递减2。如果不这么做,别的线程就会永远等待,因为spaces被初始化为旧的,更大的值。如果这是分支上的最后一个线程,你就需要重置counter并且增加generation 3,就如你在wait()中所做的那样。在完成所有的等待后就结束了。
现在你准备好写部分和的第二种实现了。在每一步,每个线程在屏障上调用wait()来保证线程步骤一起,并且一旦每个线程都完成了,就在屏障上调用done_waiting()来减少 count 。如果你在初始范围内使用第二个缓冲器,屏障提供你所需要的所有同步。在每一步中,线程从原先的范围或者缓冲器中读取,并且将新值写入相关元素中。如果线程在一个步骤中读取了原先的范围,它们在下一个步骤中读取缓冲器,反之亦然。这就确保了在不同线程的读取和写操作中没有竞争条件。一旦一个线程结束循环,它必须确保正确的最终值被写入最初的范围中。清单8.13给出了所有的操作。
清单8.13通过成对更新的partial_sum的并行实现



现在你已经很熟悉这段代码的总体结构了。你用一个拥有函数调用操作的类( process_element )来做这个工作1,你在存储在向量中8的一些线程9上运行它并且在主线程调用它10。这次的主要不同之处在于线程数量取决于列表中项的数量而不是取决于std::thread::hardware_concurrency 。正如我所说,除非你是在一个线程很便宜的大量并行机器上运行,这不是一个好方法,但是它显示了总体结构。也可以用较少的线程,每个线程处理源范围的多个值。但是这也会出现一个问题,那就是有足够少的线程使得它比向前传输算法的效率还要低。
无论如何,在process_element 函数调用操作中完成了关键工作。每一步你要么从原先的范围得到第个元素要么从缓冲器得到第i个元素2,并且将它添加到stride元素的值中3,如果从原先的范围开始就将它存储在缓冲器中,或者如果从缓冲器开始就存储在原先的范围中4。然后在开始下一步之前你在屏障上等待5。当stride 使你离开范围的起点时你就完成操作了。在这种情况下,如果你的最终结果存储在缓冲器中的话,就更新原先范围里的元素6。最后,你告诉屏障你正在done_waiting()7。
注意这种情况不是异常安全的。如果一个工作线程在 process_element 上抛出异常,就会终止此引用。你可以使用sta::promise 存储异常来处理这种情况,正如你在清单8.9的 parallel_find实现中所做的一样,或者使用互斥元保护的std::exception_ptr。
这总结了我们的三个例子,希望它们有助于具体化8.1 , 8.2和8.3中强调的设计考虑,并且证明在真实代码中可以使用这些方法。
本文节选自《C++并发编程实战》

本书介绍如何编写或者设计、调试、维护、研究多线程C++程序,并提供了技术模式和工具,可以用来分析并发编程以及降低封装并发交互的复杂性。书中还提供了大量的实例、练习、可重用的代码以及用于网络通信程序的简化库。















 2482
2482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









