




深度学习数据集的准备
下面介绍一个做了很久的项目,其中最简单的一部分是将该乳腺X线数据集进行有病没病的分类训练,说到训练最基本的就是数据集的准备,在这里先讲讲数据集怎么准备。下图是原始数据集的一部分。数据集在我电脑路径为C:\Users\Administrator.SKY-20180518VHY\Desktop\my
0中的数据
1中的数据
创建***空***的文件夹制作train集和validation set如下图,路径为C:\Users\Administrator.SKY-20180518VHY\Desktop\1
对其进行准备,详细程序及讲解如下:
# -*- coding: utf-8 -*-
"""
Created on Thu Oct 25 10:40:13 2018
@author:dj
"""
#导入一些库之前博客对这些库有所讲解[添加链接描述](https://blog.csdn.net/weixin_40123108/article/details/83340744)
import numpy as np
import os
import random
import shutil
aq='C:\\Users\\Administrator.SKY-20180518VHY\\Desktop\\my'#原数据集包括几类数据
data=os.listdir(aq)
#print(data)#此时data只有0,1两个文件夹
#random.shuffle(data)
#print(data[0][0])#引用的是文件名
root=aq
c=data
train_root='C:\\Users\\Administrator.SKY-20180518VHY\\Desktop\\1\\train'#train与val的路径
val_root='C:\\Users\\Administrator.SKY-20180518VHY\\Desktop\\1\\val'
在train和val文件夹中制作0,1文件夹
for i in range(len(c)):
qqq=os.path.exists(train_root+'/'+c[i])
if (not qqq):
os.mkdir(train_root+'/'+c[i])
qq=os.path.exists(val_root+'/'+c[i])
if (not qq):
os.mkdir(val_root+'/'+c[i])
#将原始数据按照7:3分别复制到train 与val 中
aq='C:\\Users\\Administrator.SKY-20180518VHY\\Desktop\\my\\'
for i in range(len(c)):
a=c[i]
#print(i)
data_0=os.listdir(aq+a)#抓取0,1文件夹内X线照片的内容
#print(data_0)
#print(data_0[5])#索引的为文件夹中的x线图像
random.shuffle(data_0)#打乱数据
for z in range(len(data_0)):#data_0为数据
#print(z)
pic_path=root+'/'+a+'/'+data_0[z]#得到data_0中的数据路径
if z<int(len(data_0)*0.7):
obj_path=train_root+'/'+a+'/'+data_0[z]
else:
obj_path=val_root+'/'+a+'/'+data_0[z]
#print(len(data_0),len(data_0)*0.7)
#if (os.path.exists(pic_path)):
shutil.copyfile(pic_path,obj_path)#将pic_path复制到obj_path中
最终得到的数据集如下图所示:
train文件夹中有:
val文件夹中有:
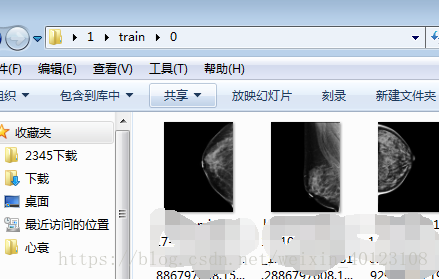
train中的0文件夹中数据:
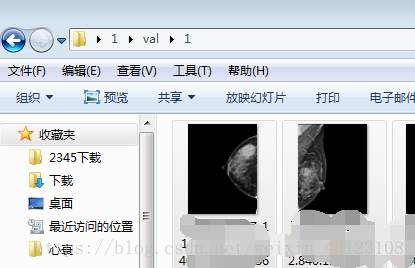
val中1文件夹有:

















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









