







pandas
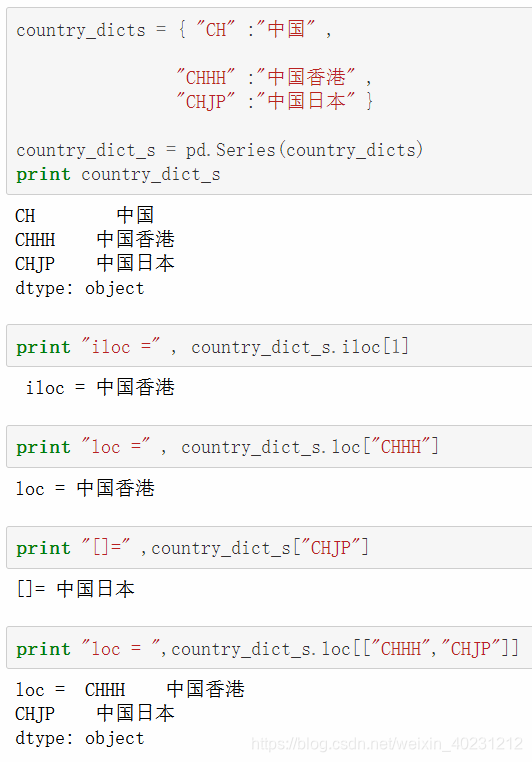
查找技巧。loc、iloc,3rd例子如果是df的话,选中的是某一列,4th例子是说明可以用list查找多个
判空:pd.isna 比 math.isnan和np.isnan 更有普适性
case:找高影响因子的SCI,这里主要复习了pandas的取行、删除(行列、inplace)按条件找index、df的拼接、写文件
import pandas as pd
df1 = pd.read_excel('SSCI目录.xlsx')
tot1 = df1['Unnamed: 1'][1:-2]
df2= pd.read_excel('SCI高影响因子.xlsx')
tot2 = df2['Unnamed: 1']
tot1[tot1.values == 'World Psychiatry'].index[0]output:2
df1.drop([0,1], axis=0)#删行
df = pd.DataFrame()
df.append(df1[tot1[tot1.values == 'World Psychiatry'].index[0]: tot1[tot1.values == 'World Psychiatry'].index[0]+1])
df = pd.DataFrame()
for a in tot1[:]:
for b in tot2:
if a.upper() == b.upper():
t = 1
print(a)
i = tot1[tot1.values == a].index[0]#取值
df = df.append(df1[i:i+1])
break
df.to_excel('high_fac_SSCI.xlsx') over!
openpyxl
这个比较方便的是完全按照i,j来控制,和C++的控制数组的习惯比较相似。初始化等(创建删除sheet):
from openpyxl import Workbook
wb = Workbook()
wb.create_sheet('music_info',0)#创建sheet,就是左下角那个
wb.remove_sheet(wb['Sheet'])#del sheet两种修改sheet方法、保存excel:
ws = wb['music_info']
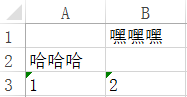
ws['A2']='哈哈哈'#直接方式
# ws.append(['1','2'])
ws.cell(row=1,column=2,value='嘿嘿嘿')#行,列
wb.save('my_excel.xlsx')结果:
h5py
为什么用它呢?
有dataset(类似数组)、groups(类似文件夹)。用法:https://blog.csdn.net/jclian91/article/details/83033834
json、pickle、hdf5区别
json模块和pickle模块都有 dumps、dump、loads、load四种方法,而且用法一样。
json模块序列化出来的是通用格式,其它编程语言都认识,就是普通的字符串;
pickle模块序列化出来的只有python可以认识,其他编程语言不认识的,表现为乱码
一般习惯:
1. HDF5保存 : Model weights
2. H5 保存: Model stucture 和 Model weights
3. JSON 和 YAML 保存: Model stucture














 2815
2815











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









