







迭代器的意义:
是为了遍历;迭代器和集合是组合关系,使得遍历的职责单一。
迭代器模式的意义:
对于类似数组和链表这样的数据结构,遍历方式比较简单,直接使用 for 循环来遍历就足够了。但是,对于复杂的数据结构(比如树、图)来说,有各种复杂的遍历方式。比如,树有前中后序、按层遍历,图有深度优先、广度优先遍历等等。如果由客户端代码来实现这些遍历算法,势必增加开发成本,而且容易写错。如果将这部分遍历的逻辑写到容器类中,也会导致容器类代码的复杂性。
应用:
针对图的遍历,我们就可以定义 DFSIterator、BFSIterator 两个迭代器类,让它们分别来实现深度优先遍历和广度优先遍历。
好处:
封装复制的遍历过程;
将遍历操作从容器类中拆分出来,放到迭代器类中,让两者的职责更加单一;
替换新的遍历算法更加容易,更符合开闭原则。
遍历过程中增删:
容器维护count,增删时候count++,创建迭代器的时间记录expertCount = count;
遍历过程中对比 expertCount 和 count ,如果不同抛出异常。
有安全的remove方法,但是不灵活。
list链表,增删不会改变迭代器游标位子,所以不会异常。但是他可能会影响,整体遍历的结束条件,要看实现。
实现快照:
1.深拷贝
2.用元素时间戳和快照时间戳对比,用来标记增删。但是需要考虑容量拓展,以及反问元素较慢的问题。
ps:
一个完整的迭代器模式,一般会涉及容器和容器迭代器两部分内容。
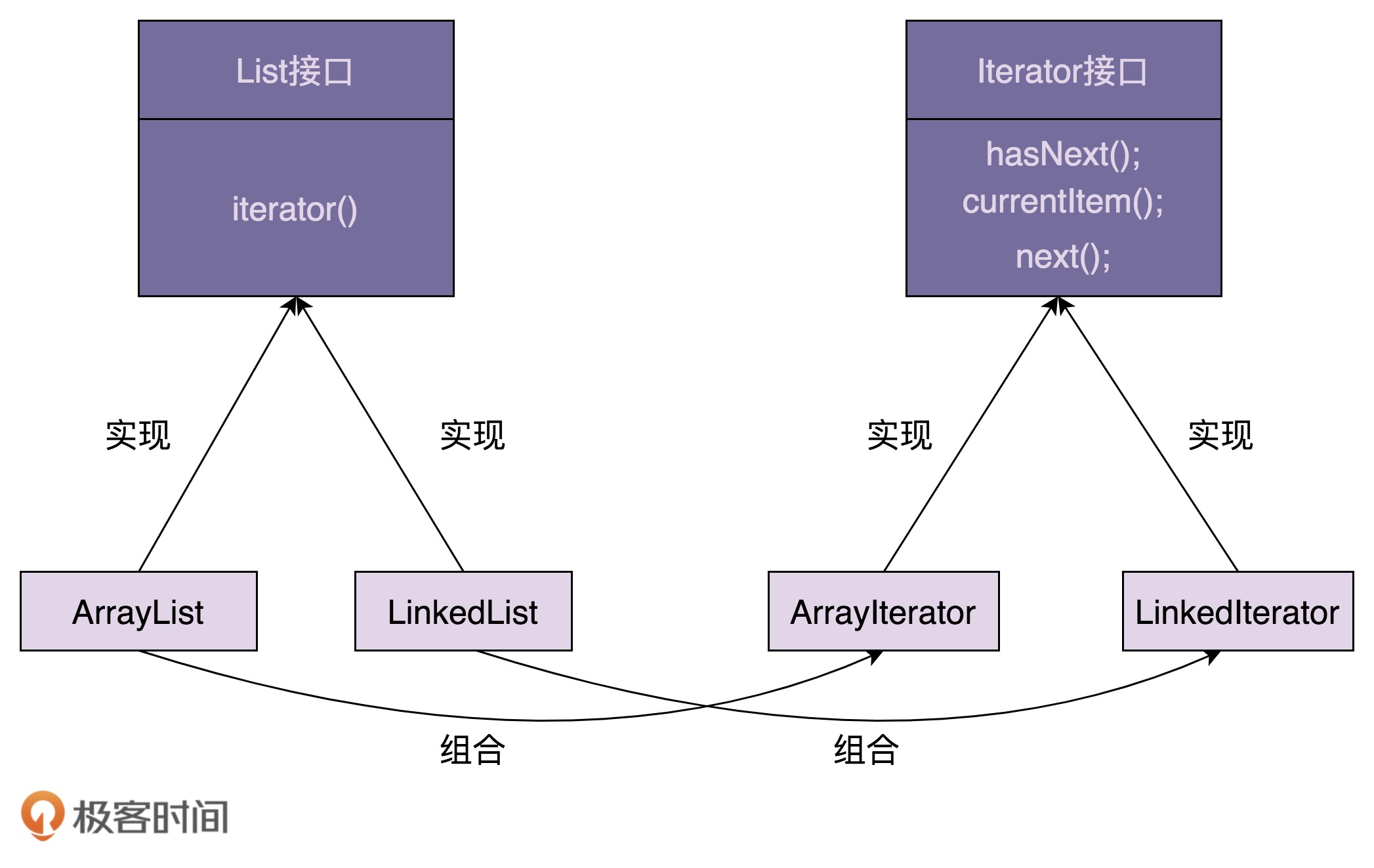
// 接口定义方式一
public interface Iterator<E> {
boolean hasNext();
void next();
E currentItem();
}














 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









