








进行异常处理我们经常使用try....except语句,在try中执行主要代码,在except中捕获异常信息,并进行相应的异常处理。
一、爬虫中异常主要有两大类:
(1)URLError类
(2)HTTPError类
def error_process():
try:
import urllib.request
import urllib.error
urllib.request.urlopen("http://blog.csdn.net")
print ("OK")
except urllib.error.URLError as e:
print (e.code) #异常状态
print (e.reason) #异常原因一般产生Error的原因有如下几种可能:
- 链接不上服务器
- 远程URL不存在
- 无网络
- 触发了HTTPError
注意:HTTPError无法处理以上前三种错误,要用URLError!
比如我们现在构造一个不存在的网址,引发远程URL不存在的异常,此时不能通过HTTPError处理,要用URLError
def error_process():
try:
import urllib.request
import urllib.error
urllib.request.urlopen("http://blog.baiducsdn.net")
print ("OK")
except urllib.error.URLError as e:
#用HTTPError会报错的
#print (e.code)
print (e.reason)
if __name__ =='__main__':
error_process()输出异常原因:

但素!!!在实际处理异常过程中,我们并不知道HTTPError是不是能处理,我们可以先让其用HTTPError子类进行处理,若无法处理,再让其用URLError进行处理,代码如下:
def error_process():
try:
import urllib.request
import urllib.error
urllib.request.urlopen("http://blog.baiducsdn.net")
print ("OK")
except urllib.error.HTTPError as e:
print (e.code)
print (e.reaoson)
except urllib.error.URLError as e:
print (e.reason)
if __name__ =='__main__':
error_process()在上述代码中,我们先用子类进行异常处理,若无法处理,再用父类进行异常处理,此时,不管发生的是哪种异常,都能够进行完美处理。
def error_process():
try:
import urllib.request
import urllib.error
urllib.request.urlopen("http://www.baiducsdn.net")
print ("OK")
except urllib.error.URLError as e:
print (e.code)
print (e.reason)
if __name__ =='__main__':
error_process()e.code会报错,因为e.code这时候不存在

处理方法:可以用hasattr()函数来判断是非具有这些属性,这样就不会出错,也就是,有e.code 就输出,没有就自动忽略;e.reason同理。
修改后代码:
def error_process():
try:
import urllib.request
import urllib.error
urllib.request.urlopen("http://www.baiducsdn.net")
print ("OK")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print (e.code)
if hasattr(e, "reason"):
print (e.reason)
if __name__ =='__main__':
error_process()运行结果:
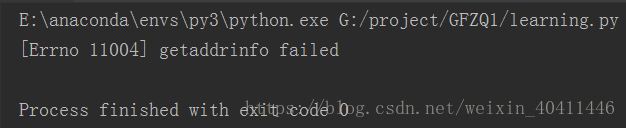
二、常见的状态码及含义
200 OK 一切正常
301 Moved Permanently 重定向到心的URL,永久性
303 Found 重新定向到新的URL,非永久性(临时的)
304 Not Modified 请求的资源未更新
400 Bad Request 非法请求
总结:
(1)如果是引发了HTTPError异常,则判断出有e.code ,就会既输出状态码也输出错误原因
(2)若引发异常的原因是“连接不上服务器”、“远程URL不存在”、“无网络”等异常中的一个,则判断没有e.code。所以只会输出e.rason .不管是何种原因。都能得到解决。
(3)学会使用try....except语句进行异常处理,在try 中执行主要代码,在except中捕获异常信息,并进行相应的处理。














 1700
1700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









