








(Ps:全篇读完后再回头来看一下封面图)
0.前言
在我们写业务代码的过程中,业务代码与系统内核间的两层内存池往往容易被忽略,尤其是其中的C库内存池。
当代码申请内存时,首先会到达应用层内存池,如果应用层内存池有足够的可用内存,就会直接返回给业务代码,否则,它会向更底层的 C 库内存池申请内存。
PTmalloc, TCMalloc和JEMalloc都属于C库内存池。几乎所有程序都在使用 C 库内存池分配出的内存,比如java使用ptmalloc,golang使用tcmalloc等等。C 库内存池影响着系统下依赖它的所有进程。
对C库内存池的选择与优化虽然看似影响不大,但是随着并发量的增加,优化效果会愈发显著。因此C库内存池的选择常常是一种很好的无需改变代码的系统调优方式。
本文主要就golang借鉴的由google开发,大名鼎鼎的tcmalloc(thread-caching malloc)进行详解。

1.传统malloc的设计
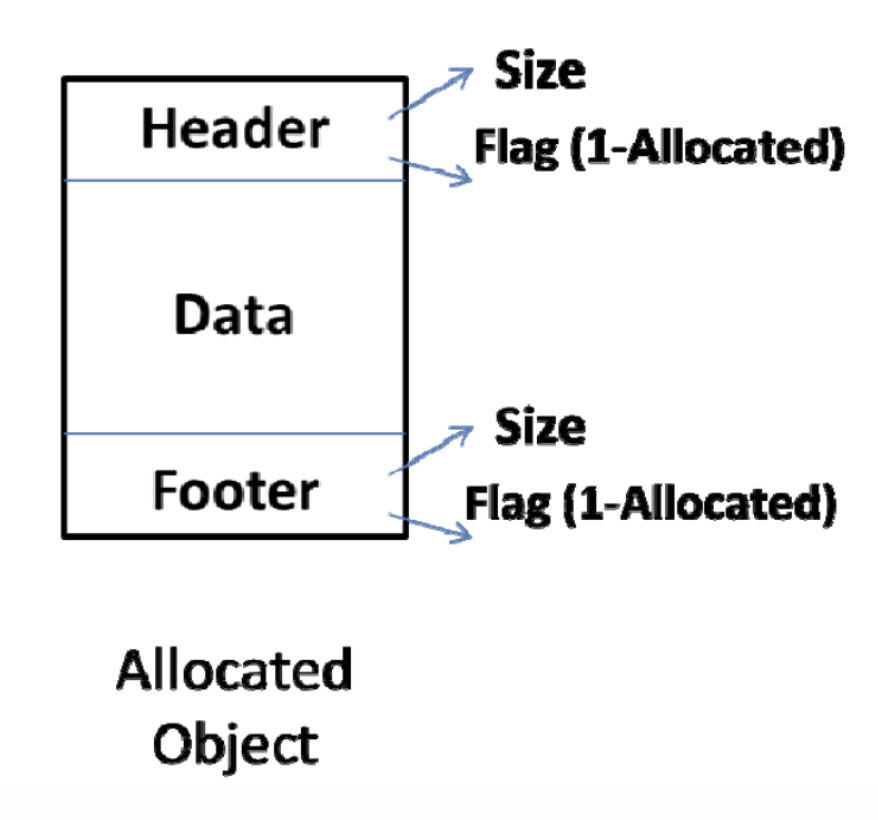
大致来说,就是将内存分成多个不同size的以下的object结构,串成双向链表,放入不同的size bin下。

2.传统malloc的缺点以及解决方法
缺点:
(1)锁竞争(最重要)
以上数据结构是非线程安全的,所以glibc进行内存操作时,会上锁,因此在多线程应用中,需要进行锁的等待,非常浪费时间。(glibc因历史原因,适用于单线程应用。)
(2)浪费空间。
data链表需要加上4byte的header与4byte的footer分别指向前后数据,假设原本有一个对象需要6byte,则本来分配一个8byte给他即可,但是加上8byte的头尾之后,经过对齐处理,需要分配16byte。并且缺少有效的利用内部碎片的方式。
(3)缺少提速手段。
缺少有效的调节措施在一定程度上对空间与时间进行协调。比如选择性的故意增大内存空间的消耗,换取速度的提升。
解决思路:
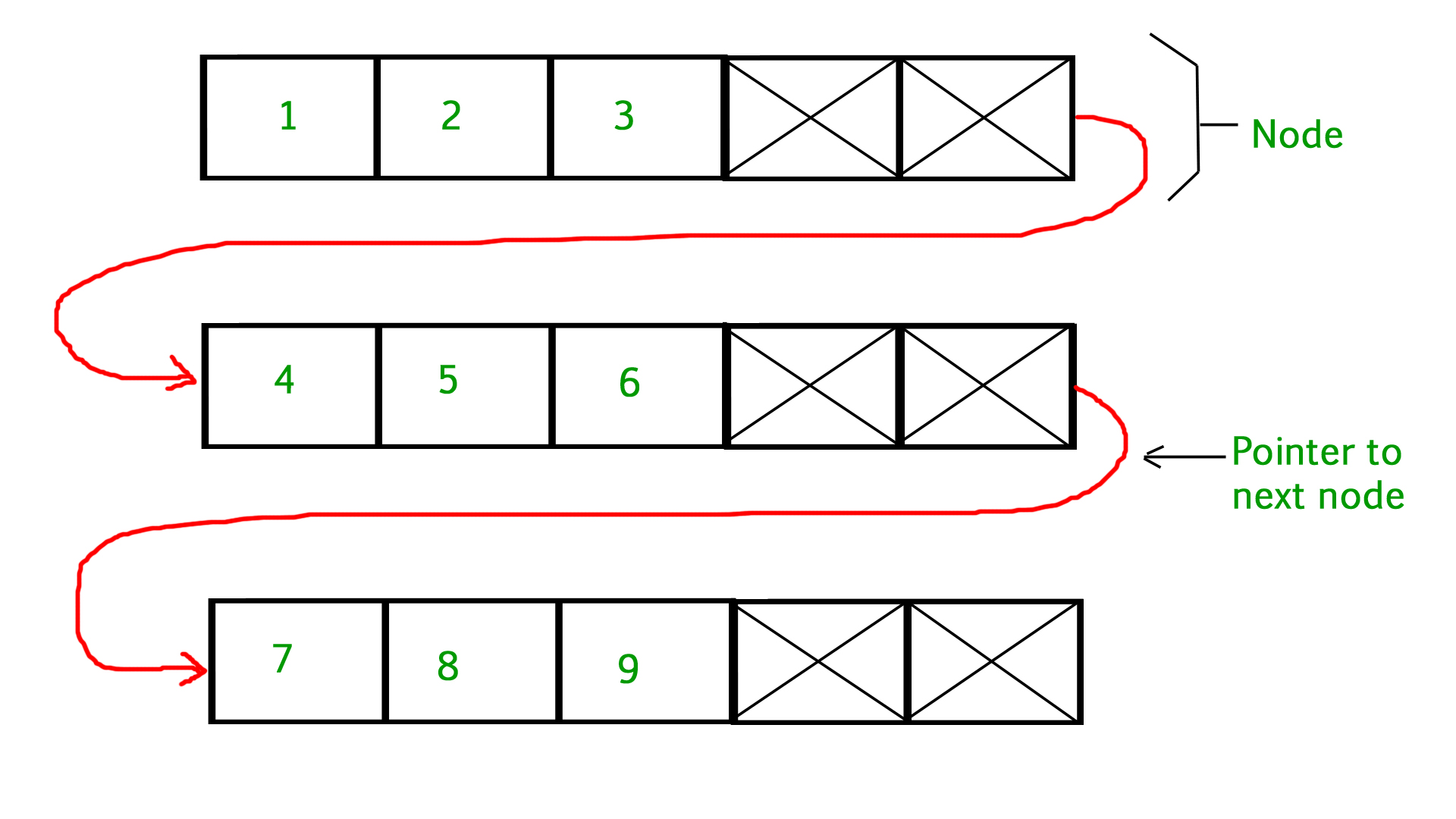
(1)各线程引入自己的缓冲层。
(2)引入更高级的数据类型包含objects,构建松散链表(此处指span而不是page)。原本的数据结构使用的是双向链表结构,每个元素都需要加头加尾浪费空间。使用松散链表之后可以在提高命中率的同时,节省空间的使用。只需要在更高级的数据结构上带上4byte的头与4byte的尾即可,不用在每个元素上带头带尾。
(3)可人为调整增加整个进程持有的内存数(引入Tcmalloc-Page概念)。
(这里有一个设定,一个tcmalloc-page只有所有的object都未被使用或者作为一个object的一部分一起被整个释放,才会被返还给back-end(pageheap),以待之后还给OS或者重新分割成许多另一种size-class的object用以分配。一个tcmalloc-page默认占用占用8KB内存。可以切割成16个512byte的小对象。而如果page的大小人为调整为32KB的话,则可以分割为64个512byte的小对象。64个小对象更不容易被全部同时释放,所以会有更多的内存搁置在middle-end中快速的供各线程使用,所以间接增加了整个进程的内存持有数)
3.tcmalloc的内存分割单位以及pageMap
一句话:一个span由多个page构成,用于分割成多个相同size的object供线程使用
情况1:当object <= page时,对span中的page进行再切分,切分成多个相同size的object
情况2:当object > page时,一个object由同一个span中多个page组成
(1)page:默认8KB
不是TLB中的那种page,是TCmalloc-Page,默认8KB(8KB=2^13B,当对page进行切割时,其中的每一个内存地址,只需要左移13位, 就可以找到其所属的pageId )

(2)span:由1个或多个连续的的page(1~128个)组成,默认8KB~1024KB
记录了起始page的pageId以及包含page数量,是一个链表结构,包含前后指针。(span中直接包含所含的page信息,可以找到page,而通过page则需要经过pageMap才能找到其归属的span)
一个span要么被拆分成多个相同size class的小对象用于小对象分配,要么作为一个整体用于中对象或大对象分配。当作用作小对象分配时,span的sizeclass成员变量记录了其对应的size
(3)object:由span切割成,有88种大小(size-class),8B~256KB
(4)PageMap:
给定一个page,如何确定这个page属于哪个span?
PageMap缓存了PageID到Span的对应关系

pageMap的优势:利用了radix-tree,即前缀树。如图不用一开始生成root中512个元素所指向的1024个数组,可以按需生成使用。相较于所有pageId存放在一个数组的情况极大的节省了内存空间。(当然真实情况是3层radix-tree,和图中所示有点区别)
4.tcmalloc(thread-caching malloc)介绍


3.1 front-end(线程安全)
分为Per-CPU模式以及Per-thread模式。
(1)Per-thread模式

在线程模式下,每一个线程都有自己的缓存(最小512KB)。
组成(1个freelist):
1.一个递增数组,放各种size-class(88种,8B~256KB)
2.每个数组元素下挂一串固定size的单向链表
使用:
在数组中,找到满足需求的size-class,查看是否有空object,有则使用,没有的话则找下一个size-class(数组全找完都没空的,就去middle-end拿一批过来)
(2)Per-CPU模式

在CPU模式下,给每一个逻辑CPU分配缓存。数据结构与线程模式相同。然而在每一个逻辑CPU中,可能出现各个线程来回抢占的情况,可能造成线程不安全的情况,因此使用了restartable sequences技术实现线程安全。
restartable sequences有点像一个函数,可以由一系列CPU指令构成。如果该线程被抢占,下次这一串指令得从头再来。此处省略详细介绍。
3.2 middle-end(非线程安全,需要spin-lock)

组成(1个freeList+1个transfer-cache):
1.Transfer Cache(或者叫CentralCache) 中间层的缓存。 (transfer cache是一个数组,负责暂存指向暂时不用的objects的指针)
2.Free-List (即和front-end中一摸一样,一个递增size-class数组+下面挂的单向链表)
使用:
整个middle-end和front-end非常相似,可以看作是给所有线程再增加了一个全局共享的free-list。如果线程自己的free-list中的空闲object数量不够了,就来middle-end中的freelist来取。剩余得多也先还给middle-end。
在这里得注意middle-end的free-list是非线程安全的,所以需要上一个自旋锁(注意不是mutex),可能会影响性能,因此作者在middle-end中增加了一层transfer-cache,数据结构是一个数组,用于存放objects,线程归还多余的object或者拿object都先看一下transfer-cache中有没有。因此能做到线程之间快速交换objects。
3.3 back-end

组成(一个基本单位为page的free-list加一个span set):
1.一个存放不同page大小(1~128个page)的数组,每个数组指向一个含有对应page数量的span双向链表。
2.一个递增数组,存放含有>128 page的span
使用:
优先查找free-list,如果没有适合的,就查找large span set。再找不到的话就去向系统申请内存空间
5. tcmalloc与ptmalloc的对比
http://goog-perftools.sourceforge.net/doc/tcmalloc.html














 1148
1148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









