






目录
一、前言
图像分割任务(医疗方向),往往一幅图像中只有一个或者两个目标,而且目标的像素比例比较小(类别不均衡问题,即正负样本比例严重失衡),使网络训练较为困难,一般可能有三种的解决方式:
(1)选择合适的loss function,对网络进行合理的优化,关注较小的目标。
(2)改变网络结构,使用attention机制(类别判断作为辅助)。
(3)与2的根本原理一致,类属attention,即:先检测目标区域,裁剪之后进行分割训练。
通过使用设计合理的loss function,相比于另两种方式更加简单易行,能够保留图像所有信息的情况下进行网络优化,达到对小目标精确分割的目的。
二、损失函数
2.1 根据像素正确与否设计的loss function
2.1.1 Log Loss
对于二分类而言,对数损失函数如下公式所示:
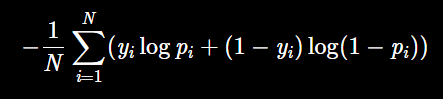

2.1.2 WCE Loss
带权重的交叉熵loss — Weighted cross-entropy (WCE)


缺点是需要人为的调整
困难样本
的权重,增加调参难度。
2.1.3 Focal Loss
能否使网络主动学习困难样本呢?
focal loss的提出是在目标检测领域
,为了解决正负样本比例严重失衡的问题。是由log loss改进而来的,为了于log loss进行对比,公式如下:

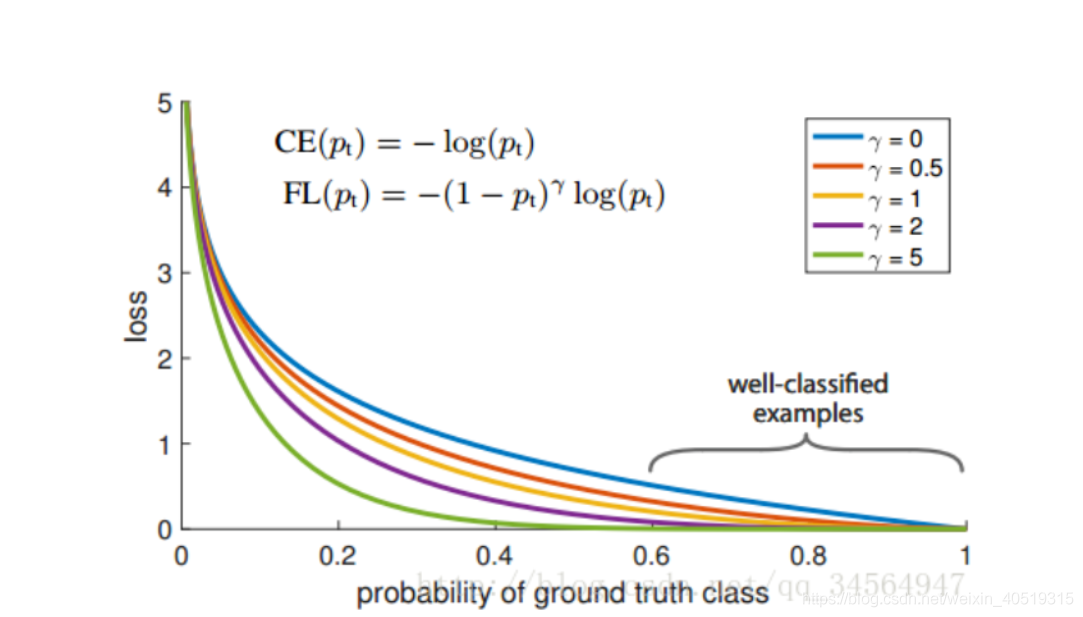

目前在图像分割上
只是适应于二分类
。
如果模型是多通道的输出,每个通道对应一个病态(标签是用0或1,相当于每个通道是二分类),那么,Focalloss 是不是对每一个通道的Focalloss进行相加
???
from keras import backend as K
'''
Compatible with tensorflow backend
'''
def focal_loss(gamma=2., alpha=.25):
def focal_loss_fixed(y_true, y_pred):
pt_1 = tf.where(tf.equal(y_true, 1), y_pred, tf.ones_like(y_pred))
pt_0 = tf.where(tf.equal(y_true, 0), y_pred, tf.zeros_like(y_pred))
return -K.sum(alpha * K.pow(1. - pt_1, gamma) * K.log(pt_1))-K.sum((1-alpha) * K.pow( pt_0, gamma) * K.log(1. - pt_0))
return focal_loss_fixed
特点:
(1)输入和输出都是图!直接使用会导致
loss的值非常的大!
(2)
需要额外添加alpha和gamma,对于调参不方便。
以上的方法Log loss,WBE Loss,Focal loss都是从本源上即从像素上来对网络进行优化。针对的都是像素的分类正确与否。有时并不能在评测指标上DICE上得到较好的结果。
2.2 根据评测标准设计的loss function
2.2.1 Dice Loss
dice loss 的
提出是在V-net
中,其中的一段原因描述是在感兴趣的解剖结构仅占据扫描的非常小的区域,从而使学习过程陷入损失函数的局部最小值。所以要加大前景区域的权重。

def dice_coef(y_true, y_pred, smooth=1):
intersection = K.sum(y_true * y_pred, axis=[1,2,3])
union = K.sum(y_true, axis=[1,2,3]) + K.sum(y_pred, axis=[1,2,3])
return K.mean( (2. * intersection + smooth) / (union + smooth), axis=0)
def dice_coef_loss(y_true, y_pred):
1 - dice_coef(y_true, y_pred, smooth=1)
特点:

训练变化剧烈的原因?
p,t过小。
在使用
DICE loss
时,对
小目标
是十分不利的,因为在只有前景和背景的情况下,
小目标一旦有部分像素预测错误,那么就会导致Dice大幅度的变动,从而导致梯度变化剧烈,训练不稳定
。
2.2.2 IOU Loss
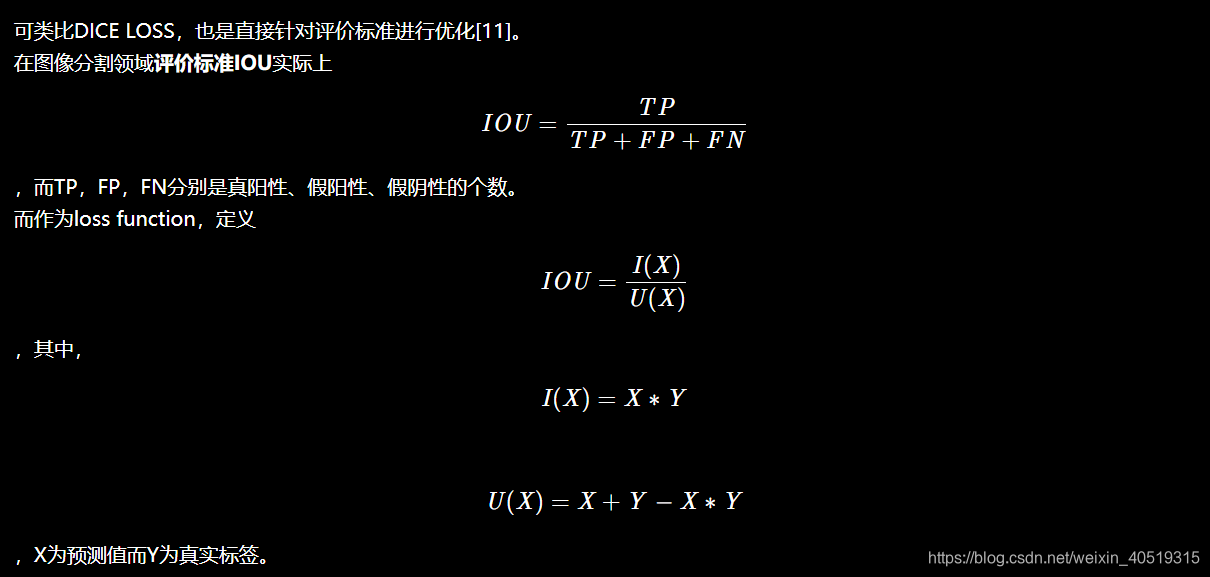
## intersection over union
def IoU(y_true, y_pred, eps=1e-6):
if np.max(y_true) == 0.0:
return IoU(1-y_true, 1-y_pred) ## empty image; calc IoU of zeros
intersection = K.sum(y_true * y_pred, axis=[1,2,3])
union = K.sum(y_true, axis=[1,2,3]) + K.sum(y_pred, axis=[1,2,3]) - intersection
return -K.mean( (intersection + eps) / (union + eps), axis=0)
IOU loss的缺点呢同DICE loss是相类似的,训练曲线可能
并不可信
,
训练的过程也可能并不稳定
,有时不如使用softmax loss等的曲线有直观性,通常而言softmax loss得到的loss下降曲线较为平滑。
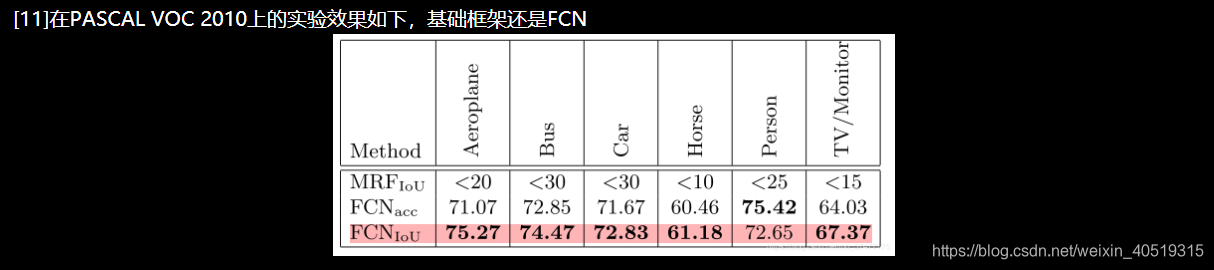
2.2.3 Tversky Loss

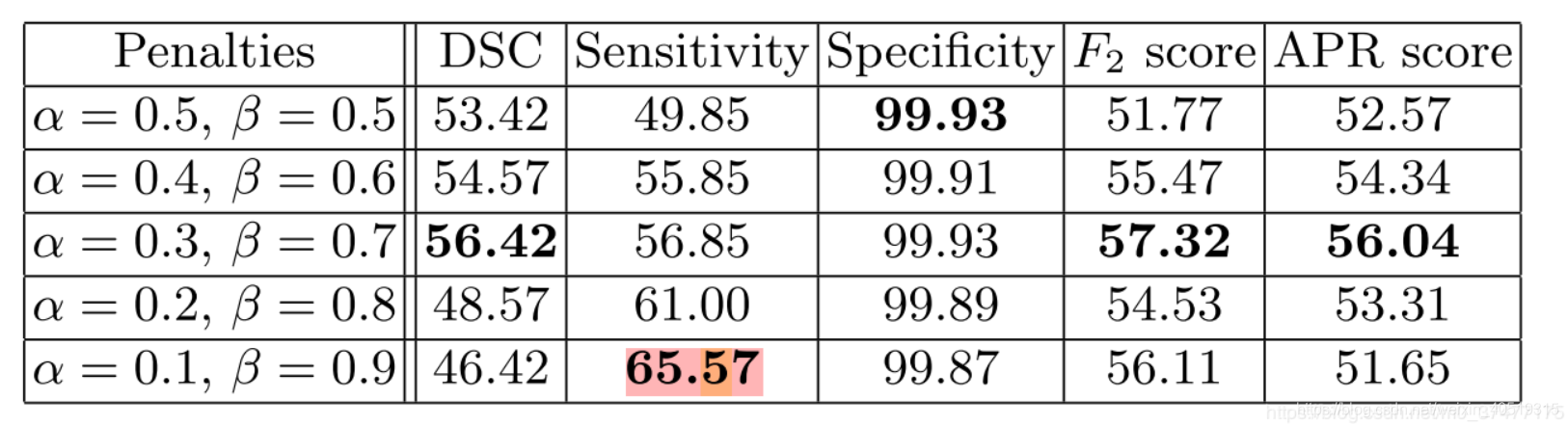
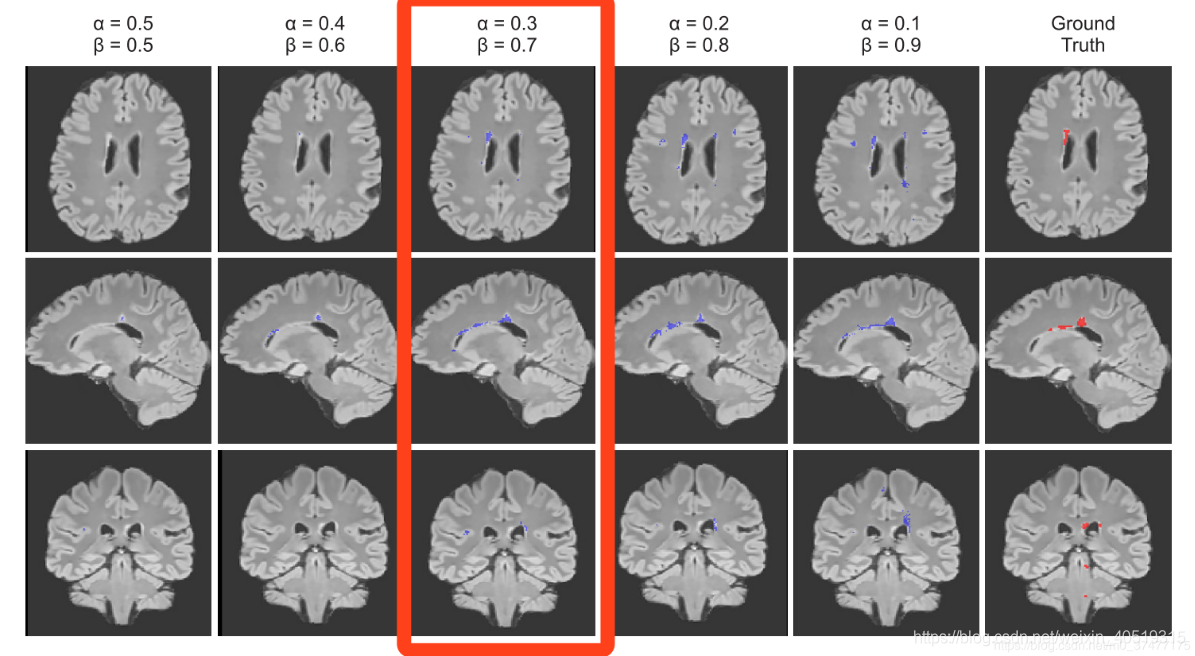
在极小的病灶下的分割效果图如下:
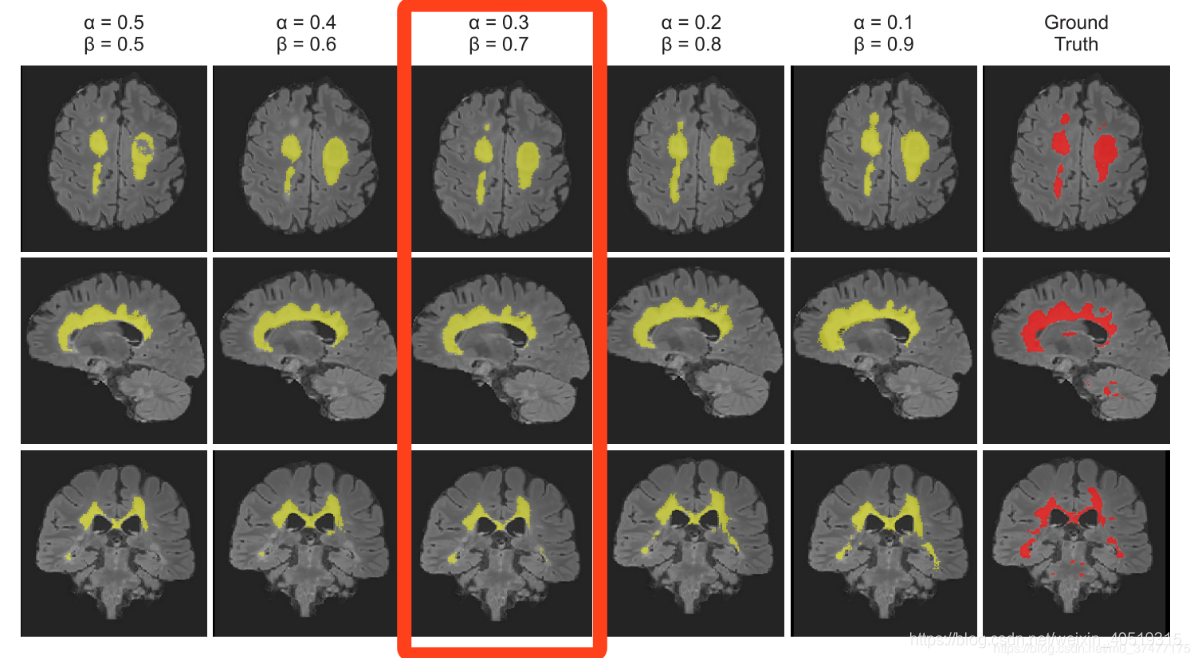
在较大病灶下的分割结果:
def tversky(y_true, y_pred):
y_true_pos = K.flatten(y_true)
y_pred_pos = K.flatten(y_pred)
true_pos = K.sum(y_true_pos * y_pred_pos)
false_neg = K.sum(y_true_pos * (1-y_pred_pos))
false_pos = K.sum((1-y_true_pos)*y_pred_pos)
alpha = 0.7
return (true_pos + smooth)/(true_pos + alpha*false_neg + (1-alpha)*false_pos + smooth)
def tversky_loss(y_true, y_pred):
return 1 - tversky(y_true,y_pred)
def focal_tversky(y_true,y_pred):
pt_1 = tversky(y_true, y_pred)
gamma = 0.75
return K.pow((1-pt_1), gamma)
2.2.4 敏感性-特异性 Loss
首先
敏感性就是召回率
,
检测出确实有病的能力
:
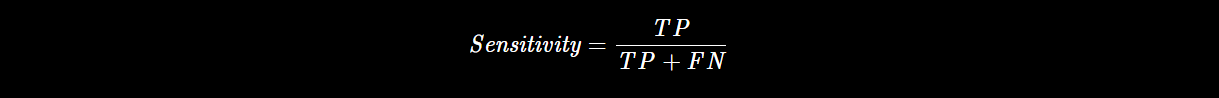
特异性
,
检测出确实没病的能力
:

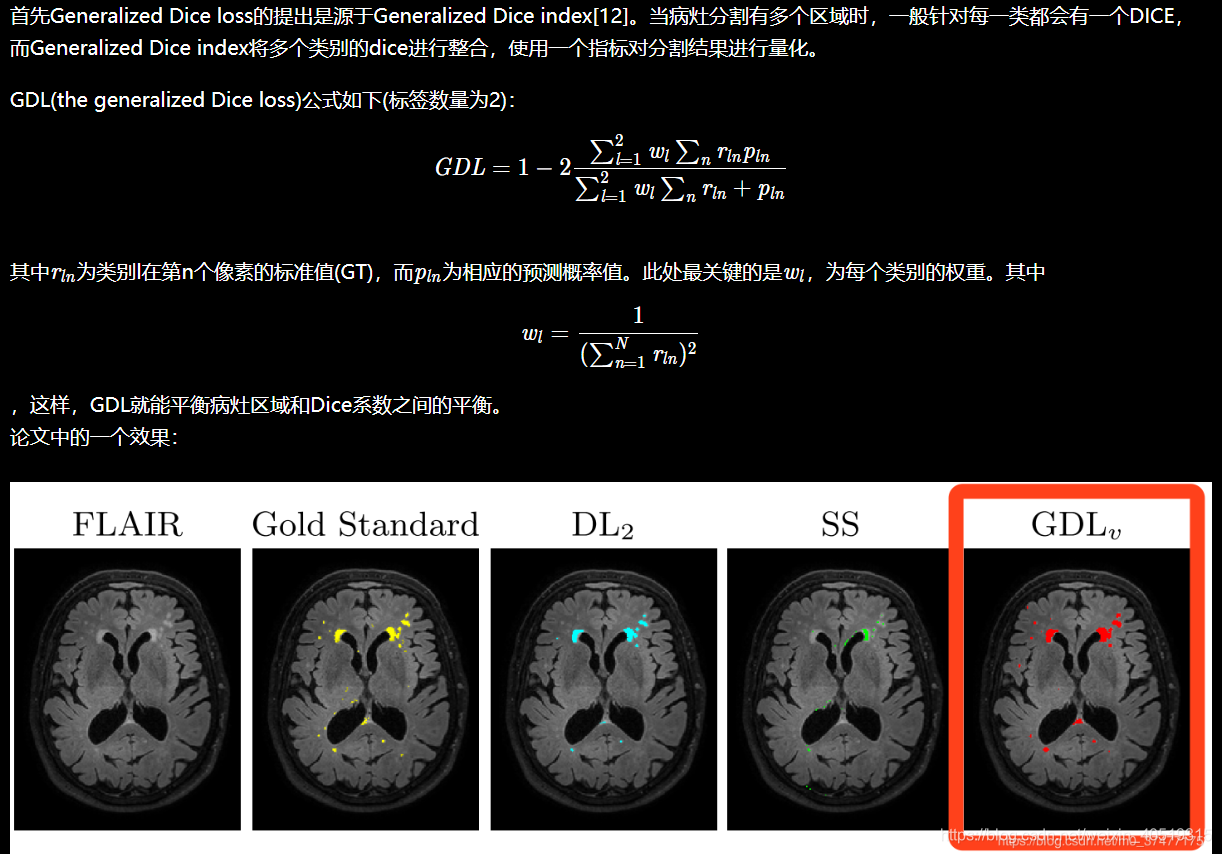
2.2.5 Generalized Dice Loss
区域大小和Dice分数之间的相关性:
在使用
DICE loss
时,对
小目标
是十分不利的,因为在只有前景和背景的情况下,小目标一旦有部分像素预测错误,那么就会导致Dice大幅度的变动,从而导致梯度变化剧烈,训练不稳定。
 但是在AnatomyNet中提到GDL面对极度不均衡的情况下,
训练的稳定性仍然不能保证
。
但是在AnatomyNet中提到GDL面对极度不均衡的情况下,
训练的稳定性仍然不能保证
。
def generalized_dice_coeff(y_true, y_pred):
Ncl = y_pred.shape[-1]
w = K.zeros(shape=(Ncl,))
w = K.sum(y_true, axis=(0,1,2))
w = 1/(w**2+0.000001)
# Compute gen dice coef:
numerator = y_true*y_pred
numerator = w*K.sum(numerator,(0,1,2,3))
numerator = K.sum(numerator)
denominator = y_true+y_pred
denominator = w*K.sum(denominator,(0,1,2,3))
denominator = K.sum(denominator)
gen_dice_coef = 2*numerator/denominator
return gen_dice_coef
def generalized_dice_loss(y_true, y_pred):
return 1 - generalized_dice_coeff(y_true, y_pred)以上本质上都是根据评测标准设计的loss function,有时候普遍会受到目标太小的影响,导致训练的不稳定;对比可知,直接使用log loss等的loss曲线一般都是相比较光滑的。
reference
1、从loss处理图像分割中类别极度不均衡的状况:https://blog.csdn.net/m0_37477175/article/details/83004746














 3026
3026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









