






论文链接: https:// arxiv.org/abs/2004.0498 9
代码链接: https:// github.com/iduta/iresne t
(10 Apr 2020)
摘要
残差网络(ResNets)是一种功能强大的卷积神经网络(convolutional neural network, CNN)架构,广泛应用于各种任务中。何恺明在2015年的深度残差网络(Deep Residual Network, 简写为 ResNet)可以说是过去几年中计算机视觉和深度学习领域最具开创性的工作。ResNet 使训练数百甚至数千层成为可能,且在这种情况下仍能展现出优越的性能。
在这项工作中,本文提出了一个ResNets的改进版本IResNets。改进了ResNet的三个主要组件:通过网络层的信息流、ResBlock和projection shortcut。IResNet能够在准确性和学习收敛性方面上都超过ResNet。例如,在ImageNet数据集上,使用具有50层的ResNet,对于top-1精度,本文方法可以比ResNet提高1.19%,而另一种配置则提高约2%。重要的是,无需增加模型复杂性即可获得这些改进。我们提出的方法允许我们训练极深的网络,而ResNet却有着严重的优化问题。我们报告了6个数据集上3个任务的结果:图像分类(ImageNet、CIFAR-10和CIFAR-100)、目标检测(COCO)和视频动作识别(Kinetics-400和Something-Something-v2)。IResNet成功地在ImageNet数据集上训练了一个404层的深度CNN,在CIFAR-10和CIFAR-100上训练了一个3002层的网络,而ResNet却不能在如此极端的深度上收敛。
IResNet为CNN的深度建立了一个新的里程碑!
回顾ResNet
以下内容来自我前期对Resnet学习和总结的摘抄,想了解更多有关ResNet的点击下方链接:
[概念]凯明之作Resnet + 心路历程[超详] + 解决退化问题 + 让网络变得更深成为现实自 AlexNet 以来,最先进的CNN 架构已经越来越深。AlexNet 只有 5 个卷积层,而之后的 VGG 网络 和 GoogleNet(代号 Inception_v1) 分别有 19 层和 22 层。但是,网络的深度不断加深,性能会越来越好吗?很显然并不是的,人们发现当模型层数增加到某种程度,模型的效果将会不升反降。也就是说,深度模型发生了退化(degradation)情况。关于退化的原因我比较中意梯度相关性说。
ResNets是由大量构建块(Residual Block,ResBlock)叠加而成的。ResNets的核心思想是,使其构建块具有恒等映射(identity mapping)的能力。所谓恒等映射,简单地来讲就是可以使得这个构建块的输入等于输出。Residual Block这种恒等映射的能力是通过使用shortcut/跳跃连接(skip connection)来实现的,即将块的输入添加到它的学习输出中。
实践证明,ResNet在很大程度上缓解了网络的退化问题,但并没有得到完全解决,IResNet的作者也通过实验彻底验证了。如下图所示,将ImageNet数据集上的深度从152层增加到200层会导致更糟糕的结果,这表明ResNet仍然会影响信息在网络中的传播。
IResNet来了
IResNets改进了ResNet的三个主要组件:通过网络层的信息流、ResBlock和projection shortcut。IResNet能够在准确性和学习收敛性方面上都超过ResNet。
1)通过网络层的信息流
残差网络 (ResNet) 是由许多残差块(ResBlocks)叠加而成的。图1(a)给出了一个残差块的例子。从公式上每个残差块可以定义为:

但从图1(a)和公式可以看出,在主传播路径上存在ReLU激活函数。通过负信号则将归零,这个ReLU可能会对信息的传播产生潜在的负面影响,尤其在训练开始时,会存在很多负权值(虽然一段时间后,网络会开始调整权值,以输出不受影响的正信号来通过ReLU)。关于上述问题在[2]中有研究(见图1(b)),他们提出了一个种新的ResBlock,称为pre-activation,即将最后的BN和ReLU移动到最前面。主传播路径上没有如ReLU非线性激活函数,导致了许多Block之间缺少非线性,又限制了学习能力。其实,就是从一个极端走向了另一个极端,原始的ResNet在主路径上用很多门(例如ReLU)来阻碍信息的传播,而pre-act则让信号直接通过没有加以控制的主路径。此外,原始ResNet和pre-act的主路径上没有BN进行标准化,因此,使得全信号(即+完后的信号,full signal)的一部分没有进行标准化,进而加大了学习的难度。
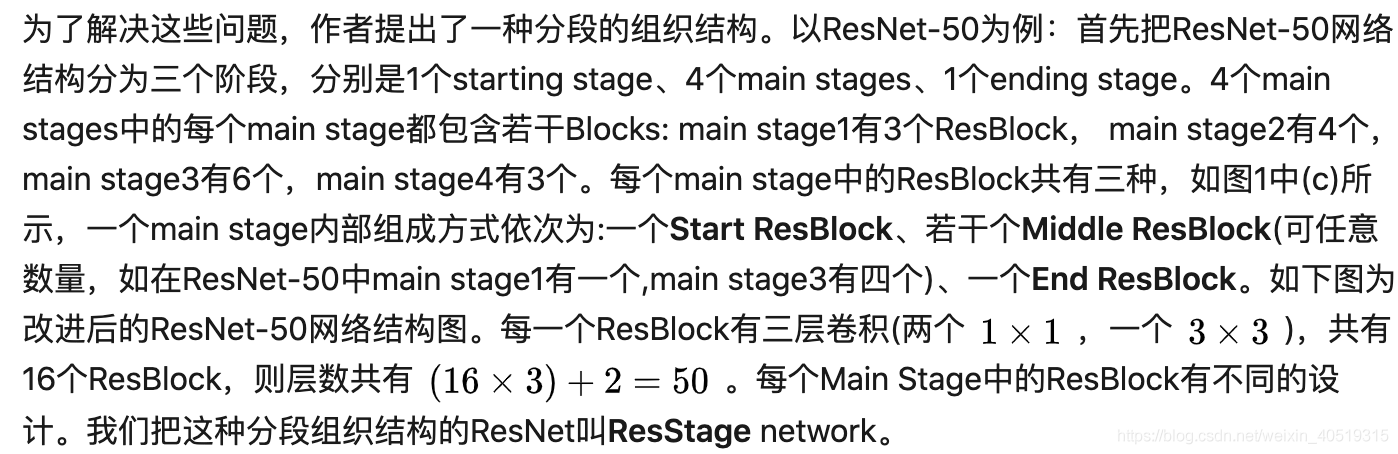
这个改进看着复杂了,但其实并没有增加复杂度。例如,三种方法构建(the original[1], pre-activation[2] and ResStage)的ResNet-50参数量都一样,只是组件的编排方式变了。注意,因为Start ResBlock已经对信号进行标准化了,所以第一个Middle ResBlock就不需要最前面那个BN了(用*号标记)。
ResStage优点1
the original[1]方法中,主路径上的ReLUs数量直接和网络的深度成正比,网络越深,ReLU越多,那么对信息的传播就越影响,这是由ReLU的性质决定的。而在pre-activation[2] 方法中,却直接将主路径上的ReLU移走,这将导致不同ResBlock之间缺乏非线性,同样也增加了学习的难度。两种方法其实就是从一个极端走到了另一个极端,而ResStage因为Main stage只有四个,所以从一开始就决定了它拥有固定数量的ReLUs,即4个。不管网络的深度怎么变化,只要Main stage的数量不变,ReLUs的数量就不会变化。这就使得信号在通过多层网络时减少了很多ReLU带来的坏影响,但同时也得到了ReLU自身的非线性好处。
下表表示随着网络深度的不断增加,ReLUs的数量是不变的。而且有趣地可以发现,作者将main stage1和main stage4一般都设置为3个ResBlock,main stage3一般设置为最多的。也许这是作者实验出来的最好的配置,但我们也要保持质疑和严谨的态度,原文中的Main stage的数量为何为4?为什么不是其它的?等等,这就需要我们大胆地去尝试了,世上没有永恒的真理。
前文提到,原始ResNet和pre-act的主路径上没有BN进行标准化,因此,使得全信号部分没有进行标准化,进而加大了学习的难度。而在ResStage方法中,End ResBlock结束时对全信号进行了标准化(BN层),并将信号转到下一个stage。下一个stage的Start ResBlock中的最后一个卷积后面有个BN进行标准化,并通过shortcut将上一个stage中已经进行标准化的信号进行相加,这样就使得全信号都进行了标准化。
综上两个优点,ResStage比其它两个方法更容易得到优化,而且可以在更深的网络中训练。训练过程中更加容易自动地选择哪个ResBlock有用哪个ResBlock丢掉(将权重训练为0即可丢掉),从而更加充分地利用不同深度的ResBlock对信息的抽象和提取。
2)改进的 projection shortcut
引自[3]
作者认为下图(a)原来架构中步长为2的1*1 conv会丢失75%的重要信息,而留下的25%的信息也没有设计什么有意义的筛选标准,这会引入噪声和造成信息丢失,对主要通道流信息造成负面影响。
改进方法:
如图中(b)所示。对于spacial projection,作者使用stride=2的3×3max pooling层,然后,对于channel projection使用stride=1的1×1 conv,然后再跟BN。
优点:
spacial projection将考虑来自特征映射的所有信息,并在下一步中选择激活度最高的元素,减少了信息的损失,后面的实验结果也证明了这点。这样改进后的projection shortcut,在通道流程上可以看作是“软下采样(conv3*3)”和“硬下采样(3*3max pooling)”两种方式的结合,是两种方式优势的互补。“硬采样”有助于分类(选择激活程度最高的元素),而“软采样”也有助于不丢失所有空间背景(因此,有助于更好的定位,因为元素之间可以进行过渡比较平滑)。同样这个改进并不增加模型复杂度和模型参数量,非常实惠。
作者将ResStage和改进后的projection shortcut用在了ResNet上,并把这个网络成为IResNet。
3)Grouped building blockt
后期更
Reference
1、He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition.In: CVPR (2016)
2、He, K., Zhang, X., Ren, S., Sun, J.: Identity mappings in deep residual networks.In:ECCV (2016)
3、CVer















 1643
1643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











