







角色:
甲:abbaabbaaba
乙:abbaaba
乙对甲说:「帮忙找一下我在你的哪个位置。」
甲从头开始与乙一一比较,发现第 7 个字符不匹配。
要是在往常,甲会回退到自己的第 2 个字符,乙则回退到自己的开头,然后两人开始重新比较。这样的事情在字符串王国中每天都在上演:不匹配,回退,不匹配,回退,……
这里需要使用的就是BF暴力法。这样的时间复杂度是O(n*m),怎么改善呢?
但总有一些妖艳字符串要花出自己不少的时间。
上了年纪的甲想做出一些改变。于是甲把乙叫走了:「你先一边玩去,我自己研究下。」
甲给自己定了个小目标:发生不匹配,自己不回退。
这基于甲发现的一个事实:当在甲的某个字符 c 上发生不匹配时,甲即使回退,最终还是会重新匹配到字符 c 上。

那干脆不回退,岂不美哉!
甲不回退,乙必须回退地尽可能少,并且乙回退位置的前面那段已经和甲匹配,这样甲才能不用回退。
如何找到乙回退的位置?
「不匹配发生时,前面匹配的那一小段 abbaab 于我俩是相同的」,甲想,「这样的话,用 abbaab 的头部去匹配 abbaab 的尾部,最长的那段就是答案。」

具体来说, abbaab 的头部有 a, ab, abb, abba, abbaa(不包含最后一个字符。下文称之为「前缀」) 。
abbaab 的尾部有 b, ab, aab, baab, bbaab(不包含第一个字符。下文称之为「后缀」)。
这样最长匹配是 ab,乙回退到第三个字符和甲继续匹配。
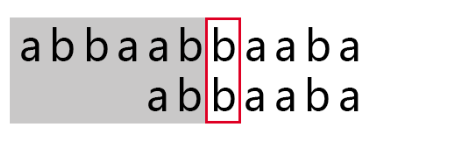
「要计算的内容只和乙有关」,甲想,「那就假设乙在所有位置上都发生了不匹配,乙在和我匹配之前把所有位置的最长匹配都算出来(算个长度就行),生成一张表,之后我俩发生不匹配时直接查这张表(PMT)就行。」
据此,甲总结出了一条甲方规则:
所有要与甲匹配的字符串,必须先自身匹配:对每个子字符串 [0...i],算出其「相匹配的前缀与后缀中,最长的那个字符串的长度」。
甲把乙叫了回来,告诉他新出炉的甲方规则。
「小 case,我对自己还不了解吗」,乙眨了一下眼睛,「那我回退到第三个字符和你继续匹配就行了」。
参考自:https://www.zhihu.com/question/21923021/answer/281346746
附上后面继续不匹配的情况:


已知空格与 D 不匹配时,前面六个字符 "ABCDAB" 是匹配的。根据跳转数组可知,不匹配处 D 的 next 值为 2,因此接下来从模式串下标为 2 的位置开始匹配。

因为空格与C不匹配,C 处的 next 值为 0,因此接下来模式串从下标为 0 处开始匹配。

因为空格与 A 不匹配,此处 next 值为 - 1,表示模式串的第一个字符就不匹配,那么直接往后移一位。

逐位比较,直到发现 C 与 D 不匹配。于是,下一步从下标为 2 的地方开始匹配。

逐位比较,直到模式串的最后一位,发现完全匹配,于是搜索完成。
KMP 算法的想法是,设法利用这个已知信息,不要把 "搜索位置" 移回已经比较过的位置,而是继续把它向后移,这样就提高了效率。
其他例子:(可直接跳过)
以上为 KMP 的基本思想,关键在于如何高效地计算甲方规则,这里有个很好的例子:abababzabababa。
列个表计算一下:(最大匹配数为子字符串 [0...i] 的最长匹配的长度)
子字符串 a b a b a b z a b a b a b a
最大匹配数 0 0 1 2 3 4 0 1 2 3 4 5 6 ?
一直算到 6 都很容易。在往下算之前,先回顾下我们所做的工作:
对子字符串 abababzababab 来说,
前缀有 a, ab, aba, abab, ababa, ababab, abababz, ...
后缀有 b, ab, bab, abab, babab, ababab, zababab, ...
所以子字符串 abababzababab 前缀后缀最大匹配了 6 个(ababab),那次大匹配了多少呢?
容易看出次大匹配了 4 个(abab),更仔细地观察可以发现,次大匹配的前缀后缀只可能在 ababab 中,所以次大匹配数就是 ababab 的最大匹配数!
OK,直接查我们先前列出的表,可以得出该值为 4。
第三大的匹配数同理,它既然比 4 要小,那前缀后缀也只能在 abab 中找,即 abab 的最大匹配数,查表可得该值为 2。
再往下就没有更短的匹配了。
回顾完毕,来计算 ? 的值:既然末尾字母不是 z,那么就不能直接 +1 了,我们回退到次大匹配 abab,刚好 abab 之后的 a 与末尾的 a 匹配,所以 ? 处的最大匹配数为 5。
子字符串 a b a b a b z a b a b a b a
最大匹配数 0 0 1 2 3 4 0 1 2 3 4 5 6 5最后总结下这个算法:
- 匹配失败时,总是能够让 pattern 回退到某个位置,使 text 不用回退。
- 在字符串比较时,pattern 提供的信息越多,计算复杂度越低。(有兴趣的可以了解一下 Trie 树,这是 text 提供的信息越多,计算复杂度越低的一个例子。)
算法说明
一般匹配字符串时,我们从目标字符串str(假设长度为n)的第一个下标选取和ptr长度(长度为m)一样的子字符串进行比较,如果一样,就返回开始处的下标值,不一样,选取str下一个下标,同样选取长度为n的字符串进行比较,直到str的末尾(实际比较时,下标移动到n-m)。这样的时间复杂度是O(n*m)。
KMP算法:可以实现复杂度为O(m+n)
考察目标字符串ptr:
ababaca 这里我们要计算一个长度为m的转移函数next。
next数组的含义就是一个固定字符串的最长前缀和最长后缀相同的长度。
注意最长前缀:是说以第一个字符开始,但是不包含最后一个字符。
比如aaaa相同的最长前缀和最长后缀是aaa。
比如:abcjkdabc,那么这个数组的最长前缀和最长后缀相同必然是abc。
cbcbc,最长前缀和最长后缀相同是cbc。
abcbc,最长前缀和最长后缀相同是不存在的。
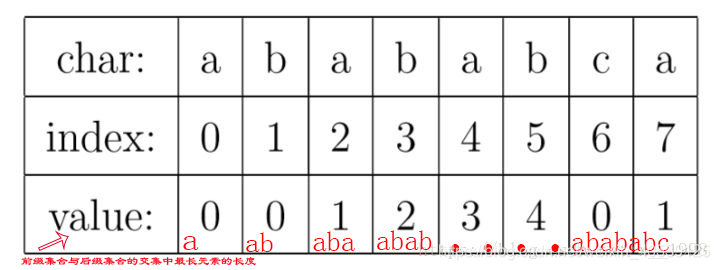
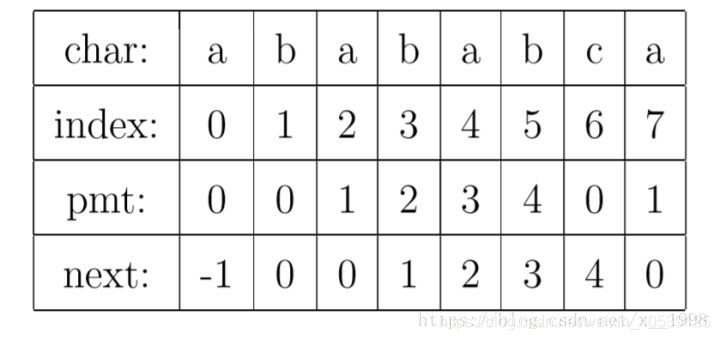
KMP算法的核心,是一个被称为部分匹配表(Partial Match Table)的数组。我觉得理解KMP的最大障碍就是很多人在看了很多关于KMP的文章之后,仍然搞不懂PMT中的值代表了什么意思。这里我们抛开所有的枝枝蔓蔓,先来解释一下这个数据到底是什么。对于字符串“abababca”,它的PMT如下表所示:
PMT中的值是字符串的前缀集合与后缀集合的交集中最长元素的长度。
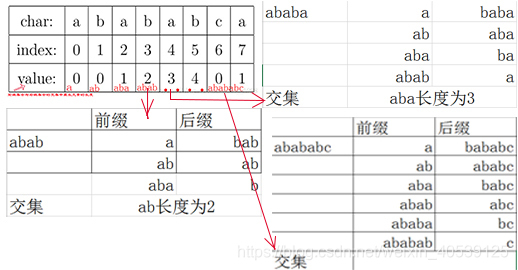
简言之,以图中的例子来说,在 i 处失配,那么主字符串和模式字符串的前边6位就是相同的。又因为模式字符串的前6位,它的前4位前缀和后4位后缀是相同的,所以我们推知主字符串i之前的4位和模式字符串开头的4位是相同的。就是图中的灰色部分。那这部分就不用再比较了。
有了上面的思路,我们就可以使用PMT加速字符串的查找了。我们看到如果是在 j 位 失配,那么影响 j 指针回溯的位置的其实是第 j −1 位的 PMT 值,所以为了编程的方便, 我们不直接使用PMT数组,而是将PMT数组向后偏移一位。我们把新得到的这个数组称为next数组。下面给出根据next数组进行字符串匹配加速的字符串匹配程序。
其中要注意的一个技巧是,在把PMT进行向右偏移时,第0位的值,我们将其设成了-1,这只是为了编程的方便,并没有其他的意义。在本节的例子中,next数组如下表所示。
代码:
int KMP(char * s, char * p)
{
int i = 0;
int j = 0;
while (i < strlen(s) && j < strlen(p))
{
if (j == -1 || s[i] == p[j])
{
i++;
j++;
}
else
j = next[j];
}
if (j == strlen(p))
return i - j;
else
return -1;
}
下面先直接给出KMP的算法流程
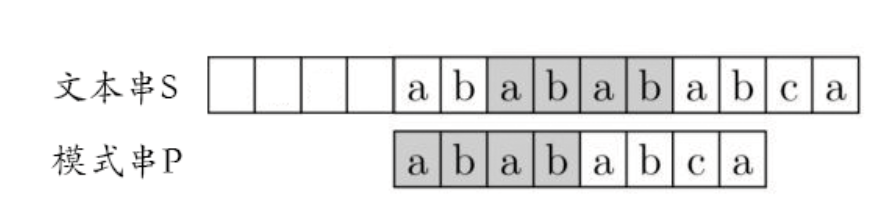
还记得之前的那句话吗?甲不回退,乙必须回退地尽可能少,并且乙回退位置的前面那段已经和甲匹配,这样甲才能不用回退。
i 就对应着甲的位置(文字串s)对比不符合点保持不变,j 用来对比next[ ]中的内容进行回溯。
假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置
如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;
如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j] 位。
换言之,当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值,即移动的实际位数为:j - next[j],且此值大于等于1。
现在,我们再看一下如何编程快速求得next数组。
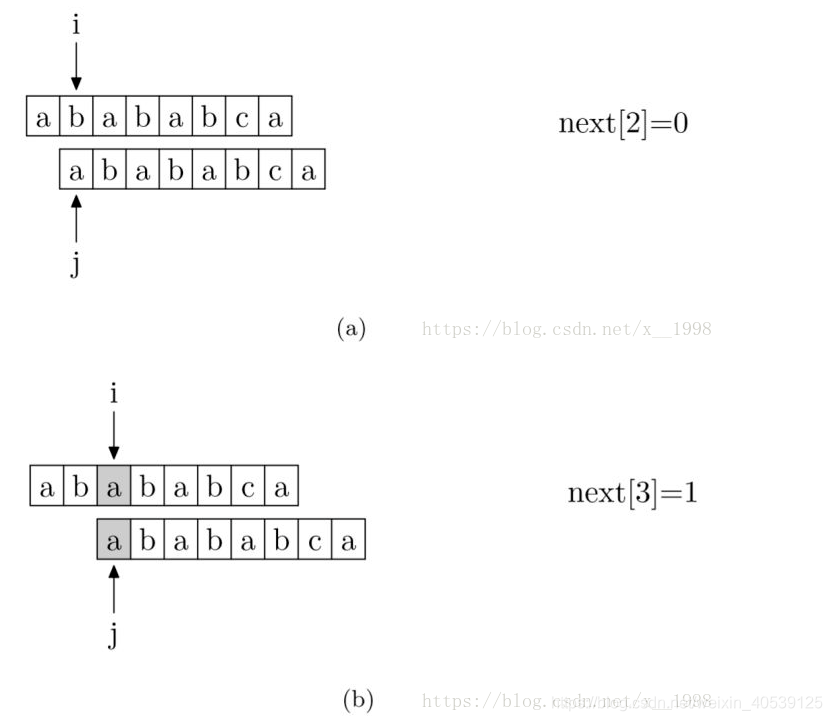
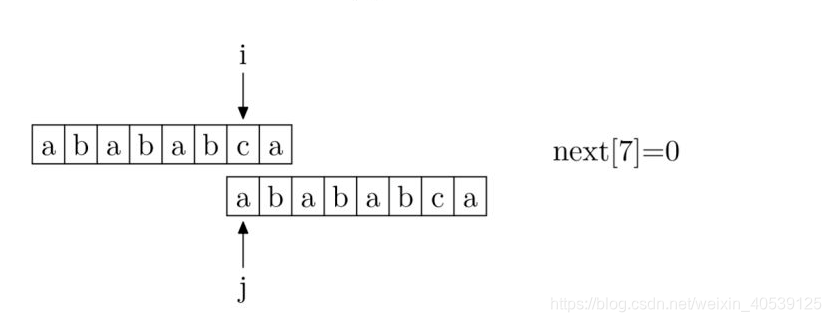
其实,求next数组的过程完全可以看成字符串匹配的过程,即以模式字符串为主字符串,以模式字符串的前缀为目标字符串,一旦字符串匹配成功,那么当前的next值就是匹配成功的字符串的长度。
next[ i ] = j ;
具体来说,就是从模式字符串的第一位(注意,不包括第0位)开始对自身进行匹配运算。 在任一位置,能匹配的最长长度就是当前位置的next值。如下图所示。

求next数组值的程序如下所示:
void getNext(char * p, int * next) // char *p 是指 查找字符
{
next[0] = -1;
int i = 0, j = -1;
while (i < strlen(p))
{
if (j == -1 || p[i] == p[j])
{
++i;
++j;
next[i] = j;
}
else
j = next[j];
}
}
一脸懵逼,是不是。。。上述代码就是用来求解模式串中每个位置的next[]值。
下面具体分析,我把代码分为两部分来讲:
(1)i 和 j 的作用是什么?
i 和 j 就像是两个” 指针 “,一前一后,通过移动它们来找到最长的相同真前后缀。
(2)if...else... 语句里做了什么?
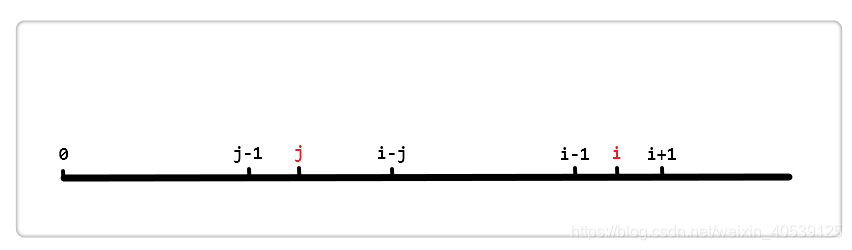
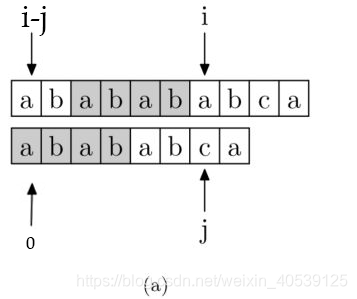
假设 i 和 j 的位置如上图,由next[i] = j得,也就是对于位置 i 来说,区段 [0, i - 1] 的最长相同真前后缀分别是 [0, j - 1] 和 [i - j, i - 1],即这两区段内容相同。
按照算法流程,if (P[i] == P[j]),则i++; j++; next[i] = j;;若不等,则j = next[j],见下图:
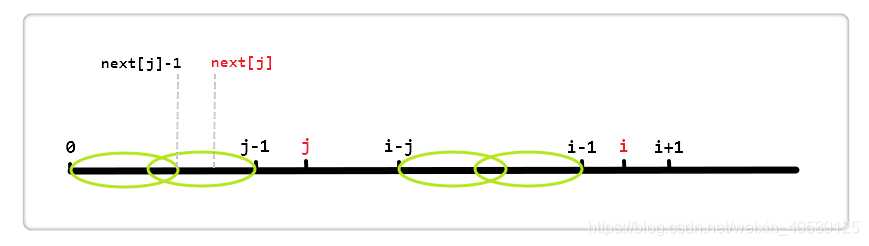
next[j]代表 [0, j - 1] 区段中最长相同真前后缀的长度。
如图,用左侧两个椭圆来表示这个最长相同真前后缀,即这两个椭圆代表的区段内容相同;同理,右侧也有相同的两个椭圆。所以 else 语句就是利用第一个椭圆和第四个椭圆内容相同来加快得到 [0, i - 1] 区段的相同真前后缀的长度。
细心的朋友会问 if 语句中j == -1存在的意义是何?
第一,程序刚运行时,j 是被初始为 - 1,直接进行P[i] == P[j]判断无疑会边界溢出; 第二,else 语句中j = next[j],j 是不断后退的,若 j 在后退中被赋值为 - 1(也就是j = next[0]),在P[i] == P[j]判断也会边界溢出。综上两点,其意义就是为了特殊边界判断。
完整代码
#include <iostream>
#include <string>
using namespace std;
/* P 为模式串,下标从 0 开始 */
void GetNext(string P, int next[])
{
int p_len = P.size();
int i = 0; // P 的下标
int j = -1;
next[0] = -1;
while (i < p_len - 1)
{
if (j == -1 || P[i] == P[j])
{
i++;
j++;
next[i] = j;
}
else
j = next[j];
}
}
/* 在 S 中找到 P 第一次出现的位置 */
int KMP(string S, string P, int next[])
{
GetNext(P, next);
int i = 0; // S 的下标
int j = 0; // P 的下标
int s_len = S.size();
int p_len = P.size();
while (i < s_len && j < p_len)
{
if (j == -1 || S[i] == P[j]) // P 的第一个字符不匹配或 S[i] == P[j]
{
i++;
j++;
}
else
j = next[j]; // 当前字符匹配失败,进行跳转
}
if (j == p_len) // 匹配成功
return i - j;
return -1;
}
int main()
{
int next[100] = { 0 };
cout << KMP("bbc abcdab abcdabcdabde", "abcdabd", next) << endl; // 15
return 0;
}KMP 优化

以 3.2 的表格为例(已复制在上方),若在i = 5时匹配失败,按照 3.2 的代码,此时应该把i = 1处的字符拿过来继续比较,但是这两个位置的字符是一样的,都是B,既然一样,拿过来比较不就是无用功了么?这我在 3.2 已经解释过,之所以会这样是因为 KMP 不够完美。那怎么改写代码就可以解决这个问题呢?很简单。
/* P 为模式串,下标从 0 开始 */
void GetNextval(string P, int nextval[])
{
int p_len = P.size();
int i = 0; // P 的下标
int j = -1;
nextval[0] = -1;
while (i < p_len - 1)
{
if (j == -1 || P[i] == P[j])
{
i++;
j++;
if (P[i] != P[j])
nextval[i] = j;
else
nextval[i] = nextval[j]; // 既然相同就继续往前找真前缀
}
else
j = nextval[j];
}
}
如果纠结于KMP算法,这里推荐另外一个有趣的算法,叫Rabin-Karp算法,理解起来相对容易。
参考文档:
https://subetter.com/algorithm/kmp-algorithm.html
http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
https://blog.csdn.net/x__1998/article/details/79951598
https://blog.csdn.net/v_july_v/article/details/7041827
https://blog.csdn.net/starstar1992/article/details/54913261
https://www.zhihu.com/question/21923021/answer/281346746- 严蔚敏. 数据结构(C 语言版)














 219
219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









