







第一部分:人工智能基础环境搭建部署(15分)
注:任务1与任务2任选一题完成即可。
o 任务1:Anaconda 3、scikit-learn、OpenCV 3.X、PyTorch 1.8.X、torchvision 0.9.X库的安装与配置。
要求(1)需使用比赛平台提供的上述各软件安装包进行安装与配置。
(2)在配置完成的环境中运行task1_1.py,将输出结果截图放入答题卡对应位置。
o 任务2:Anaconda 3、scikit-learn、OpenCV 3.X、TensorFlow 2.x库的安装与配置。
要求(1)需使用比赛平台提供的上述各软件安装包进行安装与配置。
(2)在配置完成的环境中运行task1_2.py,将输出结果截图放入答题卡对应位置。
任务一:
代码:
#task1_1.py
import torch
import sys
import sklearn
print(sys.version)
print(torch.__version__)
print("Sklearn verion is {}".format(sklearn.__version__))
x1 = torch.zeros(3, 4)
print("x1 :",x1)
y1 = torch.rand(3, 4)
print("y1 : ", y1)
print("x1 + y1 :", x1 + y1)运行结果:
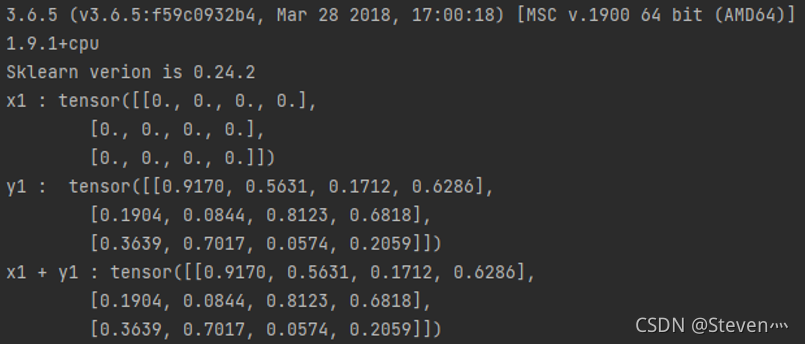
任务二:
代码:
# task1_2.py
import tensorflow as tf
import sys
import sklearn
import cv2
print(sys.version)
print(tf.__version__)
print("Sklearn verion is {}".format(sklearn.__version__))
print(cv2.__version__)
vec_1=tf.constant([1,2,2,1])
vec_2=tf.constant([7,8,9,9])
ver_add=tf.add(vec_1,vec_2)
print(ver_add)运行结果:

第二部分:样本数据预处理(30分)
o 任务:按照要求对给定csv格式数据进行处理。
task2.csv文件为本题的数据文件。利用Python编写代码完成以下任务:
(1)分别求取Max TemperatureF和Min TemperatureF两个特征的均值和方差。
(2)对Mean TemperatureF特征进行标准化,输出标准化之后的Mean TemperatureF特征的均值。
标准化采用计算公式如下:
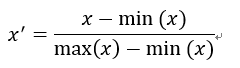
其中,x表示标准化之前的特征,x'表示标准化之后的特征。
说明:将代码源文件与运行结果截图放入答题卡对应位置。
题(1)代码:
import pandas as pd
df = pd.read_csv("task2.csv")
# print(df.head())
res_mean = df[['Max TemperatureF', 'Min TemperatureF']].mean()
print(res_mean)
res_var = df[['Max TemperatureF', 'Min TemperatureF']].var()
print(res_var)运行结果:
均值:
Max TemperatureF 50.988764
Min TemperatureF 42.000000
dtype: float64
方差:
Max TemperatureF 82.625226
Min TemperatureF 83.436620
dtype: float64题(2)代码:
import pandas as pd
df = pd.read_csv("task2.csv")
data = df['Mean TemperatureF']
data2 = (data-data.min())/(data.max()-data.min()) # 即简单实现标准化
print("标准化后的Mean TemperatureF特征的均值为:%s" % data2.mean())运行结果:
![]()
第三部分:传统机器学习算法设计及应用(20分)
o 任务:根据要求补全对应算法代码。
task3.txt为本题的数据文件,其内容为我国部分城市的经纬度坐标。task3.py为本题的代码文件。要求完成以下两个任务:
(1)根据经纬度坐标将所有数据利用Kmeans算法聚为10类;
(2)将聚类结果进行可视化(每一个城市表示为2维坐标平面的一个点,每一类中的点用同一种颜色,不同类的点采用不同颜色)。
说明:将所补充代码源文件与运行结果截图放入答题卡对应位置。
代码:
# 绘制散点图
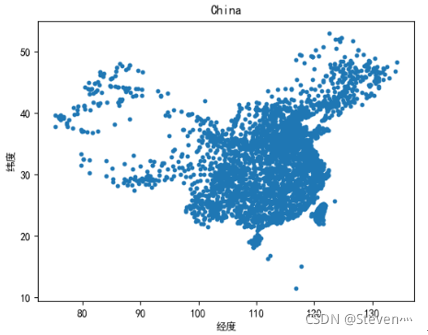
def fig_scatter(exdata, title='China'):
plt.scatter(exdata[:, 0], exdata[:, 1], s=10)
plt.title(title)
plt.xlabel('经度')
plt.ylabel('纬度')
fig_scatter(X)
plt.show()
# 将sklearn输出的结果变为字典形式
def trans(resu):
redict = {}
for ire in range(len(resu)):
try:
redict[resu[ire]].append(ire)
except KeyError:
redict[resu[ire]] = [ire]
return redict
# 绘制算法后的类别的散点图
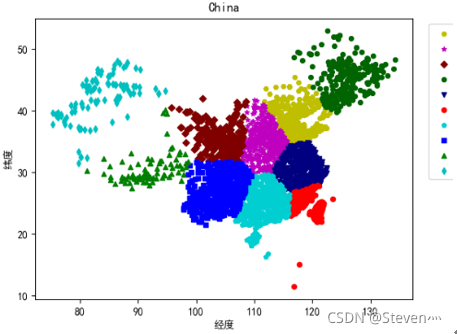
def sca(Xdata, signdict,
co=['r', 'g', 'y', 'b', 'c', 'm', '#000080', '#006400','#00CED1', '#800000', '#800080',
'#CD5C5C', '#DAA520', '#E6E6FA', '#F08080', '#FFE4C4'],
marker=['o', '^', 'H', 's', 'd', '*', 'v', '8', 'p', 'D', 'h', '+', '1', '2', '3', '4'],
title='China'):
for jj in signdict:
xdata = Xdata[signdict[jj]]
plt.scatter(xdata[:, 0], xdata[:, -1], c=co[jj], s=20, marker=marker[jj], label='%d类' % jj) # 绘制样本散点图
plt.legend(bbox_to_anchor=(1.2, 1))
plt.title(title)
plt.xlabel('经度')
plt.ylabel('纬度')
# Sklearn
sk = KMeans(init='k-means++', n_clusters=n_clusters, n_init=10)
train = sk.fit(X)
result = sk.predict(X)
skru = trans(result)
sca(X, skru, title='China')
plt.show()运行结果:
第四部分:深度学习算法设计及应用(15分)
o 任务:图片回归模型训练。
给定数据为一批人脸图片及每一张人脸对应的年龄标签数据。现要求把所有已给的数据当作训练集训练一个基于卷积神经网络的人脸年龄预测模型。
要求与说明:
(1)本体旨在考察参赛者使用深度学习库解决具体计算机视觉问题的完整流程,不以测试集准确率作为评分标准;
(2)输入网络的数据尺寸统一缩放到64*64*3;
(3)使用Adam优化器;
(4)使用均方误差损失函数(MSE);
(5)代码能正常运行,输出每一次迭代的损失值情况;
(6)使用深度学习库PyTorch或Tensorflow均可;
(7)卷积神经网络的结构如下:
| 层名称 | 参数配置 |
| 输入层 | 64*64*3 |
| 卷积层1 | 共8个3*3的卷积核,步长为1,无padding |
| 非线性映射层1 | 非线性映射函数为Relu |
| 池化层1 | 最大值池化,核2*2,步长为2 |
| 卷积层2 | 共16个3*3的卷积核,步长为1,无padding |
| 非线性映射层2 | 非线性映射函数为Relu |
| 池化层2 | 最大值池化,核2*2,步长为2 |
| 卷积层3 | 共32个3*3的卷积核,步长为1,无padding |
| 非线性映射层3 | 非线性映射函数为Relu |
| 池化层3 | 最大值池化,核2*2,步长为2 |
| 全连接层1 | 128个神经元+ Relu非线性映射 |
| Dropout | 激活概率为0.5 |
| 全连接层2 | 1个神经元+ Relu非线性映射 |
(8)需提交所有代码及成功训练运行截图。
import os
import cv2
import numpy as np
import tensorflow as tf
# 设置路径
data_home = 'imgdata/'
# 标签映射字典
image_to_label = {}
with open('label.txt', 'r') as fr:
lines = fr.readlines()
for line in lines:
line = line.strip()
key, value = line.split(' ')
image_to_label[key] = value
# 构造训练集
X_train = []
y_train = []
for jpg in os.listdir(data_home):
image = cv2.imread(data_home + jpg)
x = cv2.resize(image, (64, 64))
X_train.append(x)
y = image_to_label[jpg]
y_train.append(y)
X_train = np.array(X_train).astype('float16')/255.0
print(X_train.shape)
y_train = np.array(y_train).reshape((-1, 1)).astype('float16')
print(y_train.shape)
# print(X_train)
# print(y_train)
model = tf.keras.models.Sequential([
# 卷积层1
tf.keras.layers.Conv2D(8, 3, activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2), 2),
# 卷积层2
tf.keras.layers.Conv2D(16, 3, activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2), 2),
# 卷积层3
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2), 2),
# 全连接层1
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.5),
# 输出层
tf.keras.layers.Dense(1, activation='relu')
])
model.compile(optimizer='adam',
loss='mean_squared_error')
model.fit(X_train, y_train, epochs=5)
运行结果:
第五部分:人工智能技术综合应用(20分)
o任务:根据房源信息,预测房屋价格。(数据为train.CSV, val.CSV, test.CSV)
房源信息包括:电梯情况|楼层|户型|区域|装修情况|面积|建筑时间|。
注:部分信息有缺失。训练集:验证集:测试集=17000:3000:3000
!要求与说明:
(1)根据训练集数据训练一个房屋出租价格预测模型。
(2)按解决问题的顺序详细介绍每一步的目的,并给出相应代码,放入答题卡对应位置。
(3)计算在验证集表现最好的模型在测试集数据的预测结果,将输出结果放入答题卡对应位置(输出结果保存为txt格式并命名为task5result.txt,不能截图)。
输出txt格式的数据每一行是测试集对应房源的预测价格(一定要符合格式要求,否则自动评分程序无法正确执行)
例:
800
120
615
…
(共3000行)
注:最终需要在规定位置提交的文件包括答题卡和task5result.txt。
代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@author:zsw
@file:house_price_forecast.py
@time:2021/10/15
@function:功能介绍
"""
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler # 数据标准化
from sklearn.preprocessing import LabelEncoder # 字符串型数据编码
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
# 公共部分:模型评价体系evaluation
# 构建回归模型的评价体系并存储在evaluation中,方便对比查看,全局变量
# MSE:Mean Squared Error
evaluation = pd.DataFrame({'Model': [],
'R^2 (train)': [],
'R^2 (test)': []})
# 缺失值处理
# 填充elevator数据 根据现实可以估计大概楼层大于六楼有电梯,否则没有电梯进行缺失值得填充(利用apply函数进行操作)
def elevator_process(floor):
if floor > 6:
return "有电梯"
else:
return "无电梯"
def data_preprocess(filename):
# 利用pandas直接读取已有的数据集
df = pd.read_csv(filename, delimiter=',', encoding='gbk')
# 填充缺失值
df["Elevator"] = df["Floor"].apply(elevator_process)
# 数据集中有字符串型数据,使用labelEncoder处理
le = LabelEncoder() # 将标签值统一转换成range(标签值个数-1)范围内
data = [] # 用于存储标签转换后的数据集
if filename == './test.csv':
for i in range(df.shape[1]):
data.append(le.fit_transform(df.iloc[:, i]))
# 数据集标准化
# 为保证快速收敛,所以将数据标准化
stand = StandardScaler() # 标准化,先计算均值与标准差,再进行转化
data_std = stand.fit_transform(np.array(data).T) # 先fit再transform
X = data_std
# print(X[0])
return X, df
else:
for i in range(df.shape[1] - 1):
data.append(le.fit_transform(df.iloc[:, i]))
# print(data)
# 数据集标准化
# 为保证快速收敛,所以将数据标准化
stand = StandardScaler() # 标准化,先计算均值与标准差,再进行转化
data_std = stand.fit_transform(np.array(data).T) # 先fit再transform
X = data_std
# print(X[0])
y = df['Price']
return X, y, df
def train_data(model_select, method_use, X_train, y_train, X_val, y_val):
"""
:param model_select: 选取的带有不同参数模型
:param method_use: 模型求解的方法
:param X_train: 训练集
:param y_train: 训练集的目标
:param X_val: 验证集
:param y_val: 验证集的目标
:return: 模型的评价指标
"""
# 调用回归模型进行模型训练、预测
model = model_select
model.fit(X_train, y_train) # 模型训练
y_train_predict = model.predict(X_train) # 模型预测
# print(y_train_predict)
y_test_predict = model.predict(X_val)
# print(y_test_predict)
# 计算训练集和测试集的MSE和决定系数R2
# MSE_train = mean_squared_error(y_train, y_train_predict)
# MSE_test = mean_squared_error(y_val, y_test_predict)
R2_score_train = model.score(X_train, y_train)
R2_score_test = model.score(X_val, y_val)
print("模型(%s)的训练集的决定系数R^2: %0.3f" % (method_use, R2_score_train))
print("模型(%s)验证集的决定系数R^2: %0.3f" % (method_use, R2_score_test))
# 将线性回归模型计算的相关评价指标存入evaluation中,便于查看
r = evaluation.shape[0]
evaluation.loc[r] = ['回归模型({})'.format(method_use), R2_score_train, R2_score_test]
return evaluation
def regression_with_diff_methods(model_select, method_use, X_train, y_train, X_test, y_test):
train_data(model_select, method_use, X_train, y_train, X_test, y_test)
def test_data_predict(rf, X_train, y_train, X_test):
model = rf
model.fit(X_train, y_train) # 模型训练
y_test_predict = model.predict(X_test) # 模型预测
print(y_test_predict)
f = open("task5result.txt", "w")
for i in y_test_predict:
f.write(str(i) + '\n')
f.close()
if __name__ == '__main__':
# 数据读取、判断数据集是否有空值,数据集标签数值化、数据标准化
X_train, y_train, df_train = data_preprocess('./train.csv')
X_val, y_val, df_val = data_preprocess('./val.csv')
X_test, df_test = data_preprocess('./test.csv')
lr = LinearRegression()
method_use = '线性回归'
regression_with_diff_methods(lr, method_use, X_train, y_train, X_val, y_val)
print('\n')
dt = DecisionTreeRegressor()
method_use = '决策树回归'
regression_with_diff_methods(dt, method_use, X_train, y_train, X_val, y_val)
print('\n')
rf = RandomForestRegressor()
method_use = '随机森林回归'
regression_with_diff_methods(rf, method_use, X_train, y_train, X_val, y_val)
print('\n')
model_parameters = {
'n_estimators': 500,
'max_depth': 5,
'min_samples_split': 5,
'learning_rate': 0.01,
'loss': 'ls'
}
gbReg = GradientBoostingRegressor(**model_parameters)
method_use = '梯度决策提升树回归'
regression_with_diff_methods(gbReg, method_use, X_train, y_train, X_val, y_val)
# 经过评估对比,选择 梯度随机森林回归 算法进行预测
test_data_predict(rf, X_train, y_train, X_test)
print("代码运行结束!")题5在特征工程部分基本没做什么处理,可再做些处理,预测的结果应该会更好。
想要获取源代码和数据,请从下方链接获取:
















 3240
3240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











