






训练稀疏模型
所有刚刚提出的优化算法都会产生密集的模型,这意味着大多数参数都是非零的。 如果你在运行时需要一个非常快速的模型,或者如果你需要它占用较少的内存,你可能更喜欢用一个稀疏模型来代替。
实现这一点的一个微不足道的方法是像平常一样训练模型,然后摆脱微小的权重(将它们设置为 0)。
另一个选择是在训练过程中应用强 l1 正则化,因为它会推动优化器尽可能多地消除权重(如第 4 章关于 Lasso 回归的讨论)。
但是,在某些情况下,这些技术可能仍然不足。 最后一个选择是应用双重平均,通常称为遵循正则化领导者(FTRL),一种由尤里·涅斯捷罗夫(Yurii Nesterov)提出的技术。 当与 l1 正则化一起使用时,这种技术通常导致非常稀疏的模型。 TensorFlow 在FTRLOptimizer类中实现称为 FTRL-Proximal 的 FTRL 变体。
学习率调整
找到一个好的学习速度可能会非常棘手。 如果设置太高,训练实际上可能偏离(如我们在第 4 章)。 如果设置得太低,训练最终会收敛到最佳状态,但这需要很长时间。 如果将其设置得太高,开始的进度会非常快,但最终会在最优解周围跳动,永远不会安顿下来(除非您使用自适应学习率优化算法,如 AdaGrad,RMSProp 或 Adam,但是 即使这样可能需要时间来解决)。 如果您的计算预算有限,那么您可能必须在正确收敛之前中断训练,产生次优解决方案(参见图 11-8)。
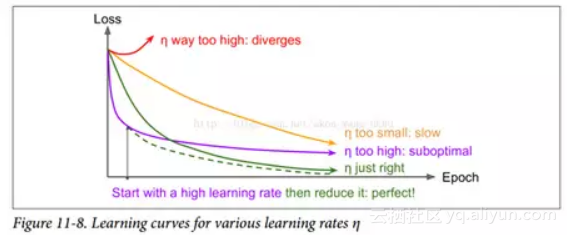
通过使用各种学习率和比较学习曲线,在几个迭代内对您的网络进行多次训练,您也许能够找到相当好的学习率。 理想的学习率将会快速学习并收敛到良好的解决方案。
然而,你可以做得比不断的学习率更好:如果你从一个高的学习率开始,然后一旦它停止快速的进步就减少它,你可以比最佳的恒定学习率更快地达到一个好的解决方案。 有许多不同的策略,以减少训练期间的学习率。 这些策略被称为学习率调整(我们在第 4 章中简要介绍了这个概念),其中最常见的是:
预定的分段恒定学习率:

Andrew Senior 等2013年的论文。 比较了使用动量优化训练深度神经网络进行语音识别时一些最流行的学习率调整的性能。 作者得出结论:在这种情况下,性能调度和指数调度都表现良好,但他们更喜欢指数调度,因为它实现起来比较简单,容易调整,收敛速度略快于最佳解决方案。
使用 TensorFlow 实现学习率调整非常简单:
initial_learning_rate = 0.1
decay_steps = 10000
global_step = tf.Variable(0, trainable=False, name="global_step")
decay_rate = 1/10
learning_rate = tf.train.exponential_decay(initial_learning_rate, global_step,
decay_steps, decay_rate) optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.9)
training_op = optimizer.minimize(loss, global_step=global_step)
设置超参数值后,我们创建一个不可训练的变量global_step(初始化为 0)以跟踪当前的训练迭代次数。 然后我们使用 TensorFlow 的exponential_decay()函数来定义指数衰减的学习率(η0= 0.1和r = 10,000)。 接下来,我们使用这个衰减的学习率创建一个优化器(在这个例子中是一个MomentumOptimizer)。 最后,我们通过调用优化器的minimize()方法来创建训练操作;因为我们将global_step变量传递给它,所以请注意增加它。 就是这样!














 803
803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









