







 本文详细介绍了ES的GET流程,对比了GET和Search两种读取操作的差异。阐述了GET基本流程,包括客户端请求、协调节点转发和数据节点处理。还对GET流程涉及的协调节点和数据节点进行了详细分析,同时提到实时读取特性及版本变化对写入速度的影响等。
本文详细介绍了ES的GET流程,对比了GET和Search两种读取操作的差异。阐述了GET基本流程,包括客户端请求、协调节点转发和数据节点处理。还对GET流程涉及的协调节点和数据节点进行了详细分析,同时提到实时读取特性及版本变化对写入速度的影响等。
GET流程
ES的读取分为GET和Search两种操作,这两种读取操作有较大的差异,GET/MGET必须指定三元组:_index、_type、_id。也就是说,根据文档id从正排索引中获取内容。而Search不指定_id,根据关键词从倒排索引中获取内容。
一个GET请求的简单例子,如下:
curl -XGET http://127.0.0.1:9200/secisland/_doc/1?pretty
响应:
{
"_index": "secisland",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 5,
"found": true,
"_source": {
"count": 100,
"detail": "HKC/惠科 23.8英寸 IPS面板 高清屏幕 低蓝光不闪屏 广视角",
"id": "10000",
"name": "惠科显示器",
"price": 1099
}
}可选参数

GET基本流程
搜索和读取文档都属于读操作,可以从主分片或副分片中读取数据。读取单个文档的流程(图片来自官网)如下图所示。
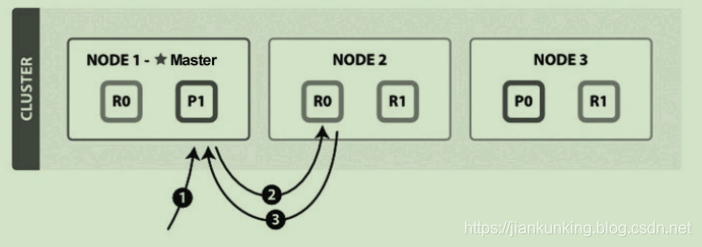
图片中有一个主分片,两个副分片。从主分片或者从副分片中读取时的步骤:
1:客户端向node1发送请求。
2:node1使用文档ID来确定文档属于那个分片0,通过集群状态中的内容路由表信息,获知分片0有3个副本分片,位于三个节点中,
此时它可以将请求发送到任意节点中,这里将请求发送到node2中。
3:node2将文档返回给node1,node1再将文档返回给客户端。node1作为协调节点,会将客户端请求轮询发送到集群的所有副本来实现负载均衡。
在读取时,文档可能存在于主分片中,但是还没有复制到副本分片中。在这种情况下,读请求命中副本分片时可能会报告文档不存在,但是命中主分片可能成功返回文档。一旦请求成功返回给客户端,则意味文档在主分片和副分片都是可用的。
GET详细分析
GET/MGET流程涉及两个节点:协调节点和数据节点,流程如下图所示:
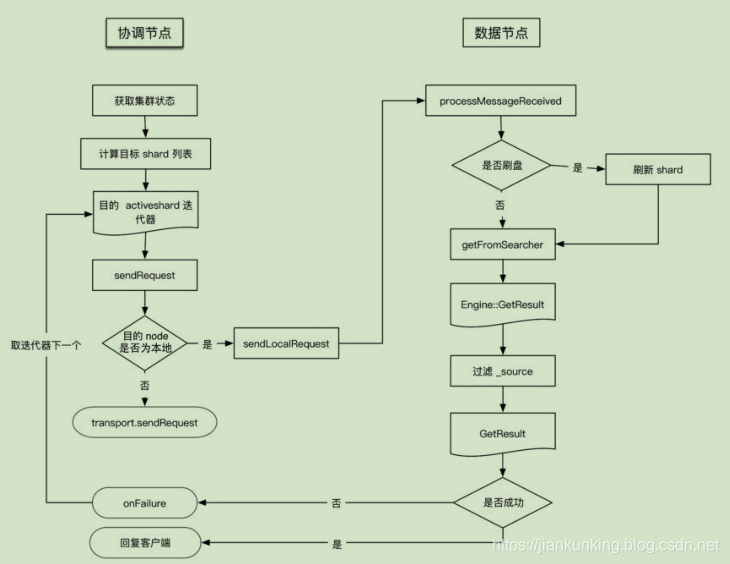
协调节点
执行本流程的线程池:http_server_worker。
TransportSingleShardAction 类用来处理存在于一个单个(主或副)分片上的读请求。将请求转发到目标节点,如果请求执行失败,则尝试转发到其他节点读取。在收到读请求后,处理过程如下。
内容路由
(1)在TransportSingleShardAction.AsyncSingleAction构造函数中,准备集群状态、节点列表等信息。
(2)根据内容路由算法计算目标shardid,也就是文档应该落在哪个分片上。
(3)计算出目标shardid后,结合请求参数中指定的优先级和集群状态确定目标节点,由于分片可能存在多个副本,因此计算出的是一个列表。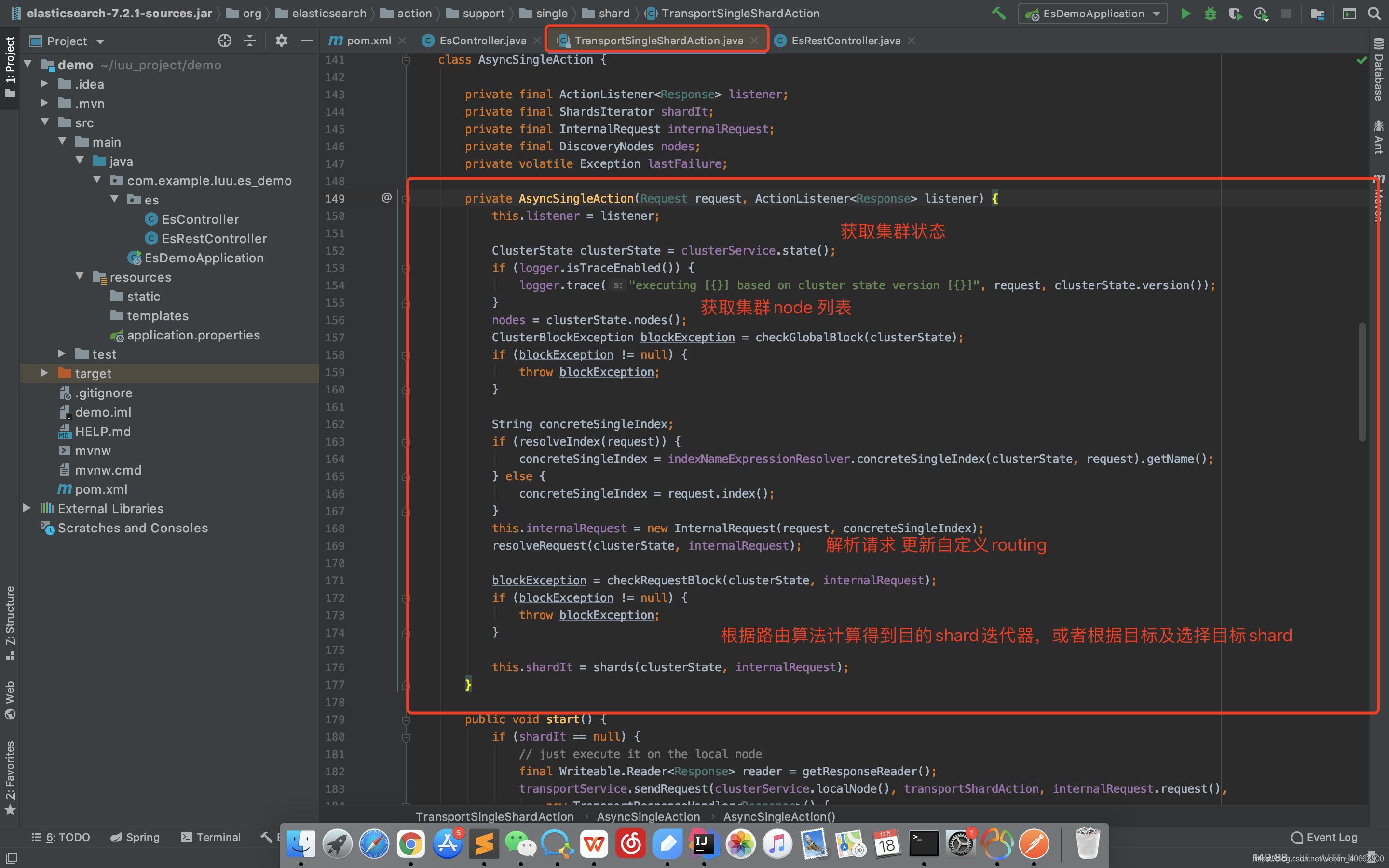
转发请求
作为协调节点,向目标节点转发请求,或者目标是本地节点,直接读取数据。发送函数声明了如何对Response进行处理:AsyncSingleAction类中声明对Response进行处理的函数。无论请求在本节点处理还是发送到其他节点,均对Response执行相同的处理逻辑:
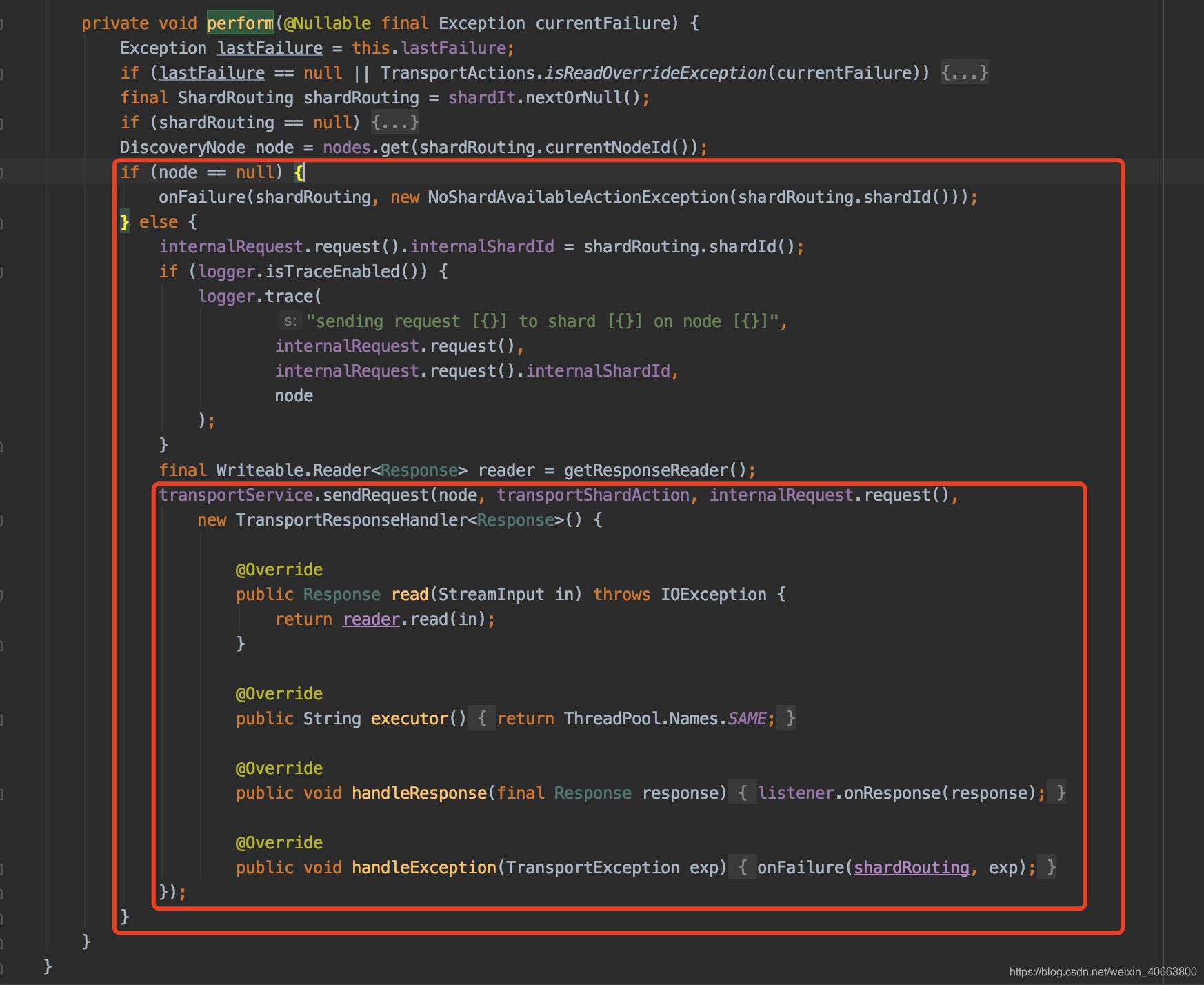
发送的具体过程:
(1)在TransportService::sendRequest中检查目标是否是本地node。
(2)如果是本地node,则进入TransportService#sendLocalRequest流程,sendLocalRequest不发送到网络,直接根据action获取注册的reg,执行processMessageReceived:
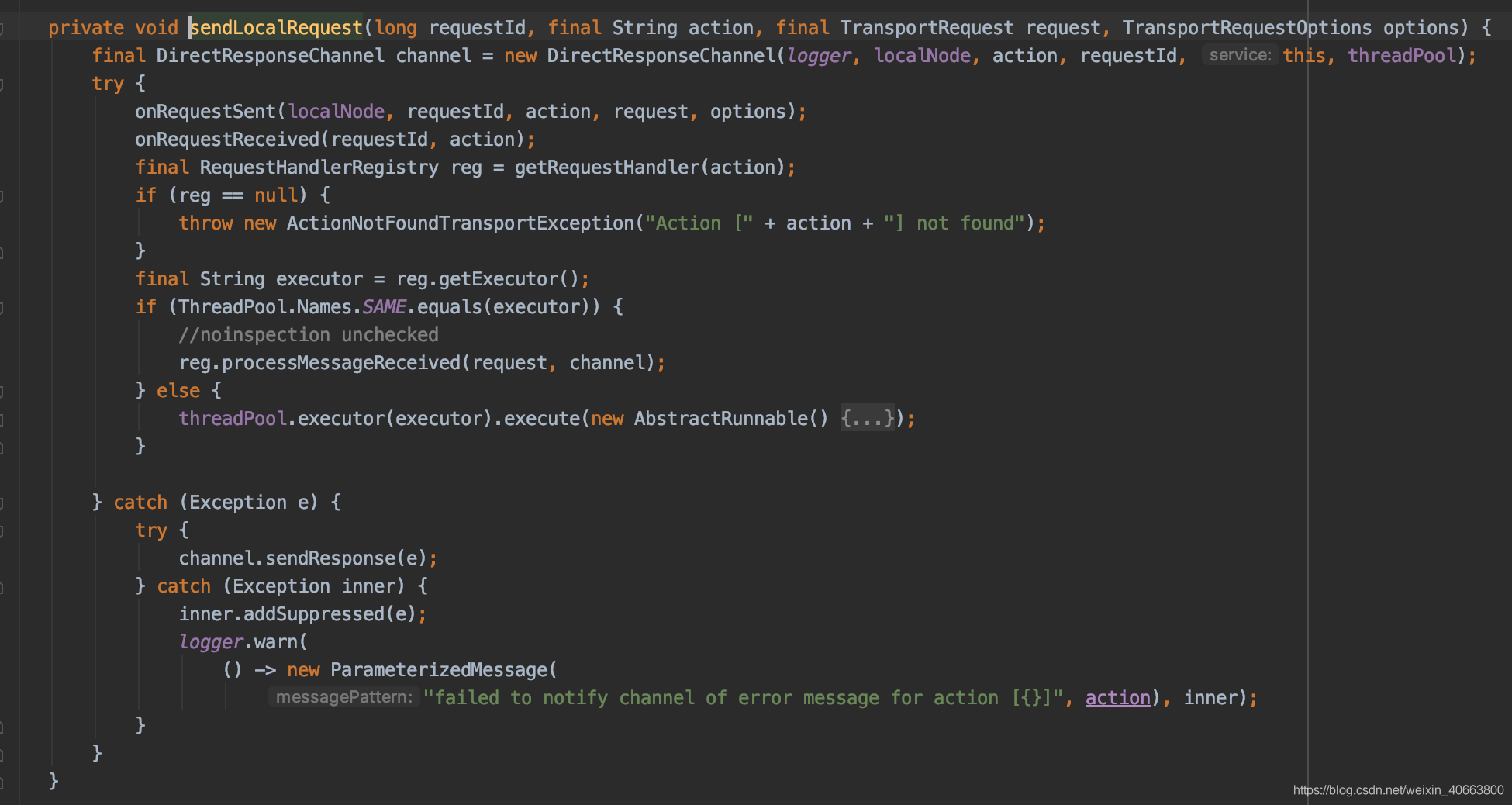
(3)如果发送到网络,则请求被异步发送,“sendRequest”的时候注册 handle,等待处理Response,直到超时。
(4)等待数据节点的回复,如果数据节点处理成功,则返回给客户端;如果数据节点处理失败,则进行重试:

数据节点
执行本流程的线程池:get
数据节点接收协调节点请求的入口为:TransportSingleShardAction.ShardTransportHandler# messageReceived。读取数据并组织成Response,给客户端channel返回:

shardOperation先检查是否需要refresh,然后调用indexShard.getService().get()读取数据并存储到GetResult中。
读取及过滤
在ShardGetService#get()函数中,调用:GetResult getResult = innerGet();获取结果。GetResult 类用于存储读取的真实数据内容。核心的数据读取实现在ShardGetService#innerGet()函数中:
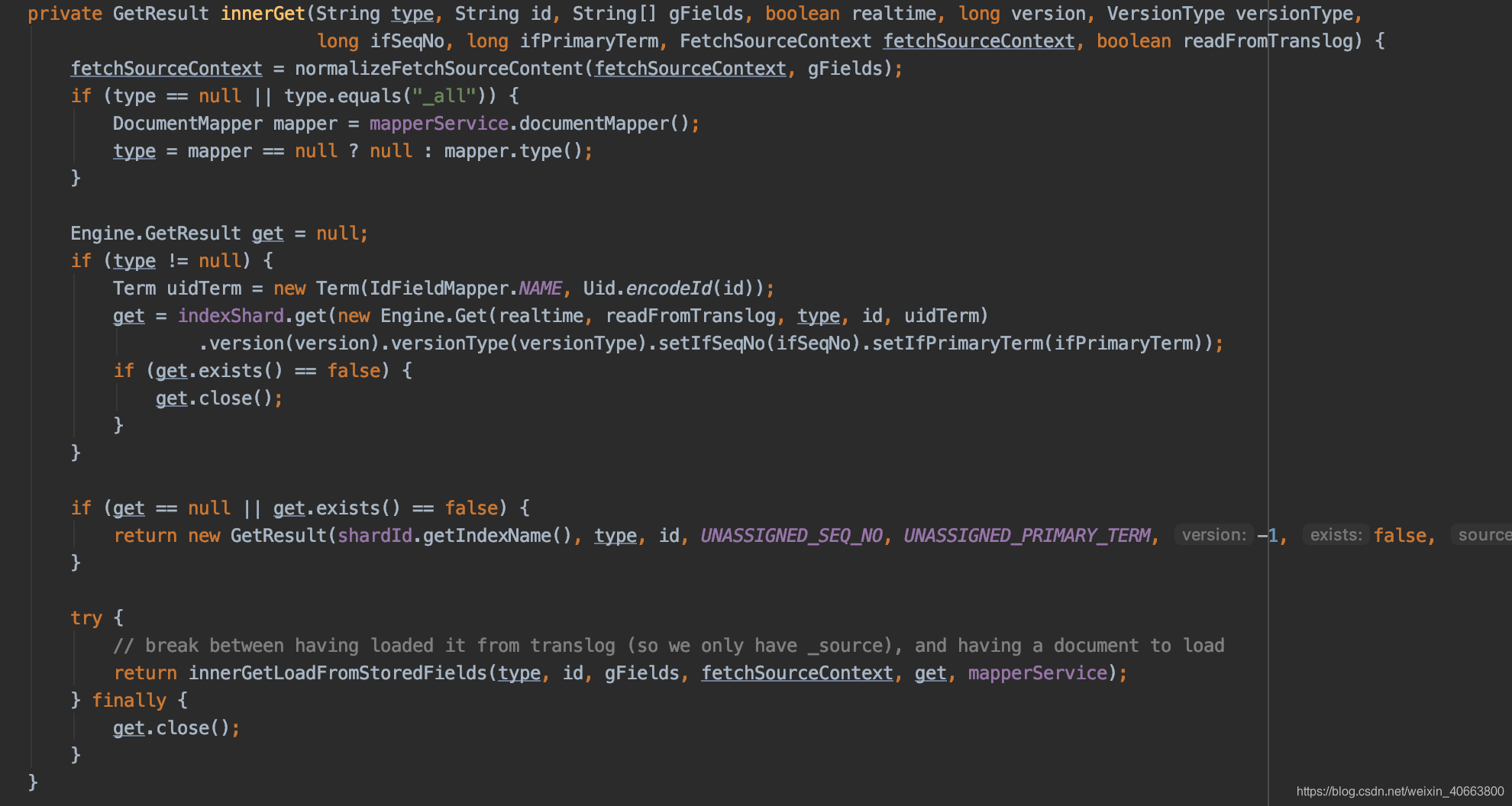
(1)通过 indexShard.get()获取 Engine.GetResult。Engine.GetResult 类与innerGet 返回的GetResult是同名的类,但实现不同。indexShard.get()最终调用InternalEngine#get读取数据。
(2)调用ShardGetService#innerGetLoadFromStoredFields(),根据type、id、DocumentMapper等信息从刚刚获取的信息中获取数据,对指定的 field、source 进行过滤(source 过滤只支持对字段),把结果存于GetResult对象中。InternalEngine的读取过程InternalEngine#get过程会加读锁。处理realtime选项,如果为true,则先判断是否有数据可以刷盘,然后调用Searcher进行读取。Searcher是对IndexSearcher的封装。在早期的 ES 版本中,如果开启(默认)realtime,则会尝试从 translog 中读取,刚写入不久的数据可以从translog中读取;从ES 5.x开始不会从translog中读取,只从Lucene中读。realtime的实现机制变成依靠 refresh 实现。
我们需要警惕实时读取特性,GET API默认是实时的,实时的意思是写完了可以立刻读取,但仅限于GET、MGET操作,不包括搜索。
在5.x版本之前,GET/MGET的实时读取依赖于从translog中读取实现,5.x版本之后的版本改为refresh,因此系统对实时读取的支持会对写入速度有负面影响。
由此引出另一个较深层次的问题是,update操作需要先GET再写,为了保证一致性,update调用GET时将realtime选项设置为true,并且不可配置。因此update操作可能会导致refresh生成新的Lucene分段。读失败是怎么处理的? 尝试从别的分片副本读取。优先级 优先级策略只是将匹配到优先级的节点放到了目标节点列表的前面。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









