







Flink的容错机制
概述
Flink容错的核心机制就是持续地创建分布式数据流及其状态的一致性快照,。当系统遇到故障时,比如(机器,网络,软件等),重启所有的算子,回退到checkpoint(检查点),确保程序的每一条记录只会作用准确一次(exactly-once )的语义,也可以选择配置成至少一次(at-least-once )
注意: 为了容错机制生效,数据源(例如 queue 或者 broker)需要能重放数据流。比如说Apache Kafka, Flink 中 Kafka 的 connector 利用了这个功能。
简单来说: Flink的容错机制就是 检查点机制+可部分重发的数据源
异步屏障快照
异步屏障快照是一种轻量级的快照技术,能以低成本备份 DAG(有向无环图)或 DCG(有向有环图)计算作业的状态,这使得计算作业可以频繁进行快照并且不会对性能产生明显影响。异步屏障快照核心思想是通过屏障消息(barrier)来标记触发快照的时间点和对应的数据,从而将数据流和快照时间解耦以实现异步快照操作,同时也大大降低了对管道数据的依赖,减小了随之而来的快照大小。
Flink的checkpoint机制实现了标准的 Chandy-Lamport 算法,并且用来实现分布式快照。
Barrier是啥
Barrier的中文释义叫做数据栅栏或者屏障,顾名思义,是用来分隔数据的。
- 在source中被插入到数据流中,作为数据流的一部分,随着数据向下流动。barrier并不会干扰数据的正常顺序,严格保证数据流的顺序。
- 每一个barrier把数据流分成两部分:一部分进入当前快照;另一部分进入下一快照。
- 每一个barrier都携带着快照的id,并且 barrier 之前的数据都进入了此快照 。
- barrier不会干扰数据流的处理,所以非常轻量,多个不同快照的多个 barrier 会在流中同时出现,即多个快照可能同时创建。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iqgfCjDz-1577256469103)(https://s2.ax1x.com/2019/12/24/lCcmc9.png)]
Barrier对齐
上面说的是单个流的barrier,那如果有多个输入流呢,就需要进行barrier对齐
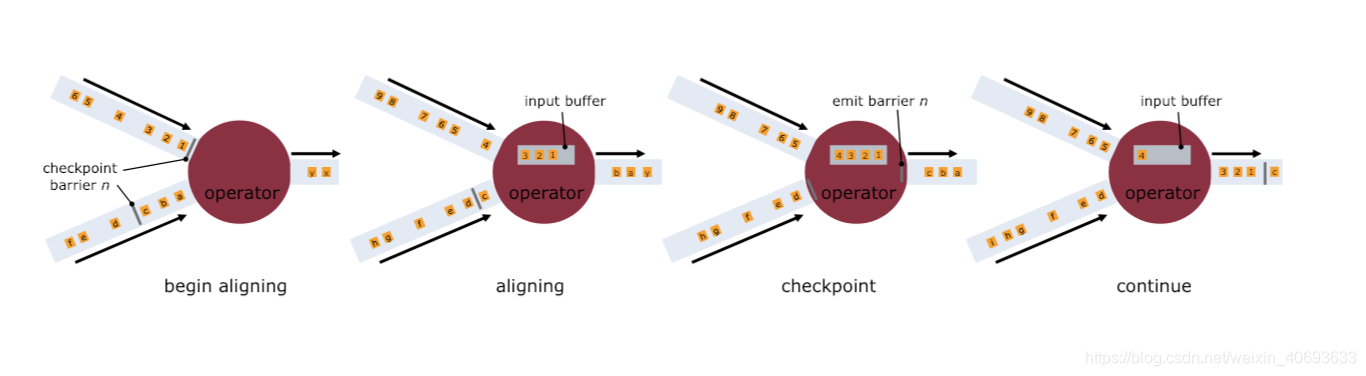
- 算子只要接收到某个输入流的barrier n,他就不能继续处理此数据流后续的数据,直到该算子接收到其余所有输入流的barrier n 。否则会将快照n的数据和快照n+1的数据搞混。
- barrier n所属的数据流先不处理,从这些数据流中接收到的数据先放入一个缓冲区
- 当从最后一个输入流获取到barrier n时,该算子才会发送所有等待向后发送的数据,然后发送快照 n 对应的barrier n
- 经过以上步骤,算子恢复所有输入流数据的处理,优先处理输入缓存中的数据
checkpoint的执行步骤
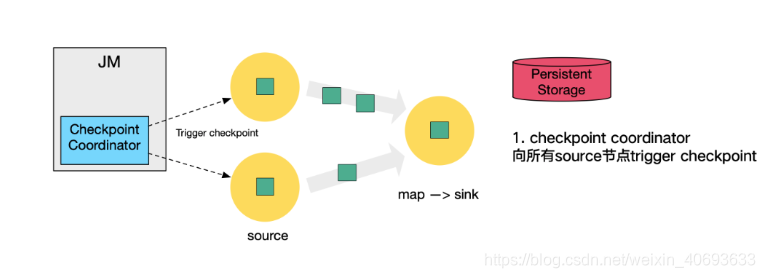
下图是执行保存检查点的第一步,左侧代表一个检查点协调者,中间是由两个source和一个sink组成的flink作业,最后侧是持久化存储(HDFS)
- 检查点协调者向所有的source触发检查点
-
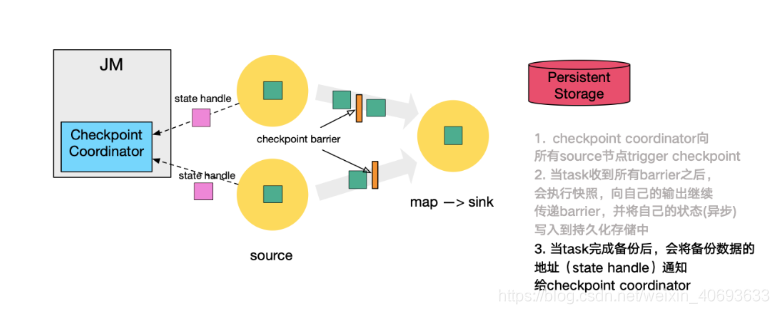
source在数据流中插入了barrier后,数据流向下游流动,同时把自己的状态异步的写入持久化存储中
-
当task完成state的备份之后,会将备份数据的地址(state handle)通知给检查点协调者
-
当些有的sink节点收集齐上游的两个输入流的barrier之后,执行本地快照,以RocksDB 增量式的Checkpoint 为例,首先 RocksDB 会全量刷数据到磁盘上(红色大三角表示),然后 Flink 框架会从中选择没有上传的文件进行持久化备份(紫色小三角)。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WFmnlQYJ-1577256469110)(https://s2.ax1x.com/2019/12/25/lia5y6.png)]](https://img-blog.csdnimg.cn/20191225145018913.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDY5MzYzMw==,size_16,color_FFFFFF,t_70)
-
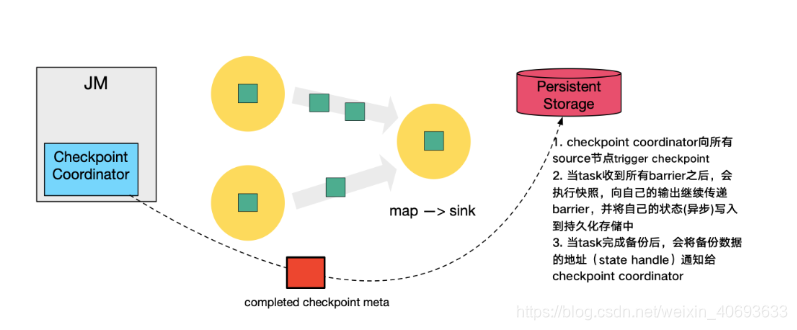
sink节点完成自己的Checkpoint 之后,也会返回state handle 给检查点协调者
-
当检查点协调者收集齐所有的state handle之后,就认为本次Checkpoint 全局完成了,向持久化存储中再备份一个 Checkpoint meta 文件。
两种类型的检查点
检查点有两种类型,分别为
-
Savepoint
-
Checkpoint
Savepoint Externalized Checkpoint 用户通过命令触发,由用户管理其创建与删除 Checkpoint 完成时,在用户给定的外部持久化存储保存 标准化格式存储,允许作业升级或者配置变更 当作业 FAILED(或者 CANCELED)时,外部存储的 Checkpoint 会保留下来 用户在恢复时需要提供用于恢复作业状态的 savepoint 路径 用户在恢复时需要提供用于恢复的作业状态的 Checkpoint 路径
如何容错恢复
所谓容错,就是在作业任务挂掉之后,重新执行时,能够恢复到作业挂掉之前的状态,并且为了保证准确一次(exactly once )的语义,要求作业从失败恢复后的状态要和失败时一致,而恢复时就是根据检查点的快照进行恢复。
- Flink 选择最近一个完成的 checkpoint k (k表示为为快照)
- 系统重新部署整个分布式数据流,重置所有 operator 的状态到 checkpoint k
- 数据源被置为从 Sk 位置读取。例如在 Apache Kafka 中,意味着让消费者从 Sk 处的偏移量开始读取。
注意: 如果是RockDB的增量快照,operator 需要从最新的全量快照回复,然后对此状态进行一系列增量更新。














 429
429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









