






大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2024我们一起变强。
在很多特定使用场景中,AI模型如果想真正发挥作用,通常需要具备相应的背景知识。举个例子,提供客户支持的聊天机器人需要了解它所服务的具体业务,而法律分析类的AI机器人则必须熟悉大量的历史案件。
为了提升AI模型的背景知识,开发者们通常采用一种叫做检索增强生成(RAG)的方法。简单来说,RAG会从知识库中检索相关信息,并将其附加到用户的输入提示中,从而大幅增强模型的回答能力。然而,传统的RAG方案在编码信息时,常常会丢失上下文,这导致系统无法从知识库中检索到最相关的信息。
Anthropic(推出Claude的公司)提出了一种可以显著改善RAG检索质量的方法,称为“上下文检索(Contextual Retrieval)”。这一方法结合了两个子技术:上下文嵌入(Contextual Embeddings)和上下文BM25(Contextual BM25)。通过这些技术,系统的检索失败率可以减少49%,而如果再结合重新排序(reranking),失败率可以进一步降低至67%。这些改进大大提升了检索的准确性,直接促进了后续任务的整体表现。
关于简单地使用更长提示词的一些建议
有时候,最简单的解决方案往往是最好的。如果你的知识库规模较小(少于20万个tokens,约相当于500页的内容),其实你可以直接将整个知识库包含在提示词中,无需使用RAG或类似的方法。这样做反而更加直接、有效。Anthropic这里以20万tokens为例是因为当前Claude模型的上下文窗口均为20万个tokens。

几周前,Anthropic推出了提示缓存(prompt caching)功能,专门为Claude模型优化了这种方法,使其速度更快、成本更低。开发者现在可以在API调用之间缓存经常使用的提示词,延迟减少超过2倍,成本节约高达90%。
但随着知识库规模的增长,简单地使用长提示词就不再适用了,这时你就需要一个更具扩展性的方案,这就到了上下文检索(Contextual Retrieval)的用武之地了。
RAG简介:扩展到更大规模的知识库
当知识库的规模过大,无法完全放入模型的上下文窗口时,检索增强生成(RAG)通常是最合适的解决方案。RAG通过对知识库进行预处理,按照以下步骤来工作:
-
将知识库(即文档集合)分解成较小的文本块,每个块通常不超过几百个token;
-
使用嵌入模型将这些文本块转换为向量嵌入,从而编码这些文本块的语义;
-
将这些嵌入存储在支持语义相似性搜索的向量数据库中。
在实际使用中,当用户输入查询时,系统会通过向量数据库找到与查询语义最相似的文本块。随后,系统会将这些最相关的块添加到生成模型的提示中,来生成最终的回答。
虽然嵌入模型在捕捉语义关系上表现出色,但有时会错过一些关键的精确匹配。幸运的是,针对这种情况,有一个传统技术可以帮助我们:BM25。BM25(Best Matching 25)是一种排名函数,依靠词汇匹配来找到精确的词或短语匹配。它对于那些包含唯一标识符或技术术语的查询特别有效。
BM25的原理是基于TF-IDF(词频-逆文档频率)这一概念的。TF-IDF衡量某个词在文档集合中的重要性,而BM25在此基础上进一步优化,考虑了文档的长度,并对词频进行了饱和处理,防止常见词汇主导结果。
举个例子,假设用户在技术支持数据库中查询“错误代码TS-999”,嵌入模型可能会找到一些关于错误代码的内容,但可能会错过“TS-999”这个精确匹配。BM25则会查找该具体的字符串,确保找到最相关的文档。
为了提升检索的准确性,RAG系统通常结合嵌入模型和BM25技术,步骤如下:
-
将知识库分解成较小的文本块,每个块不超过几百个token;
-
为这些块创建TF-IDF编码和语义嵌入;
-
使用BM25根据精确匹配查找最相关的块;
-
使用嵌入模型根据语义相似性查找最相关的块;
-
通过排名融合技术将第3步和第4步的结果结合并去重;
-
将最相关的前K个块添加到提示中,以生成最终响应。
通过同时利用BM25和嵌入模型,传统的RAG系统能够提供更全面、准确的检索结果,在精确术语匹配和广泛语义理解之间取得平衡。
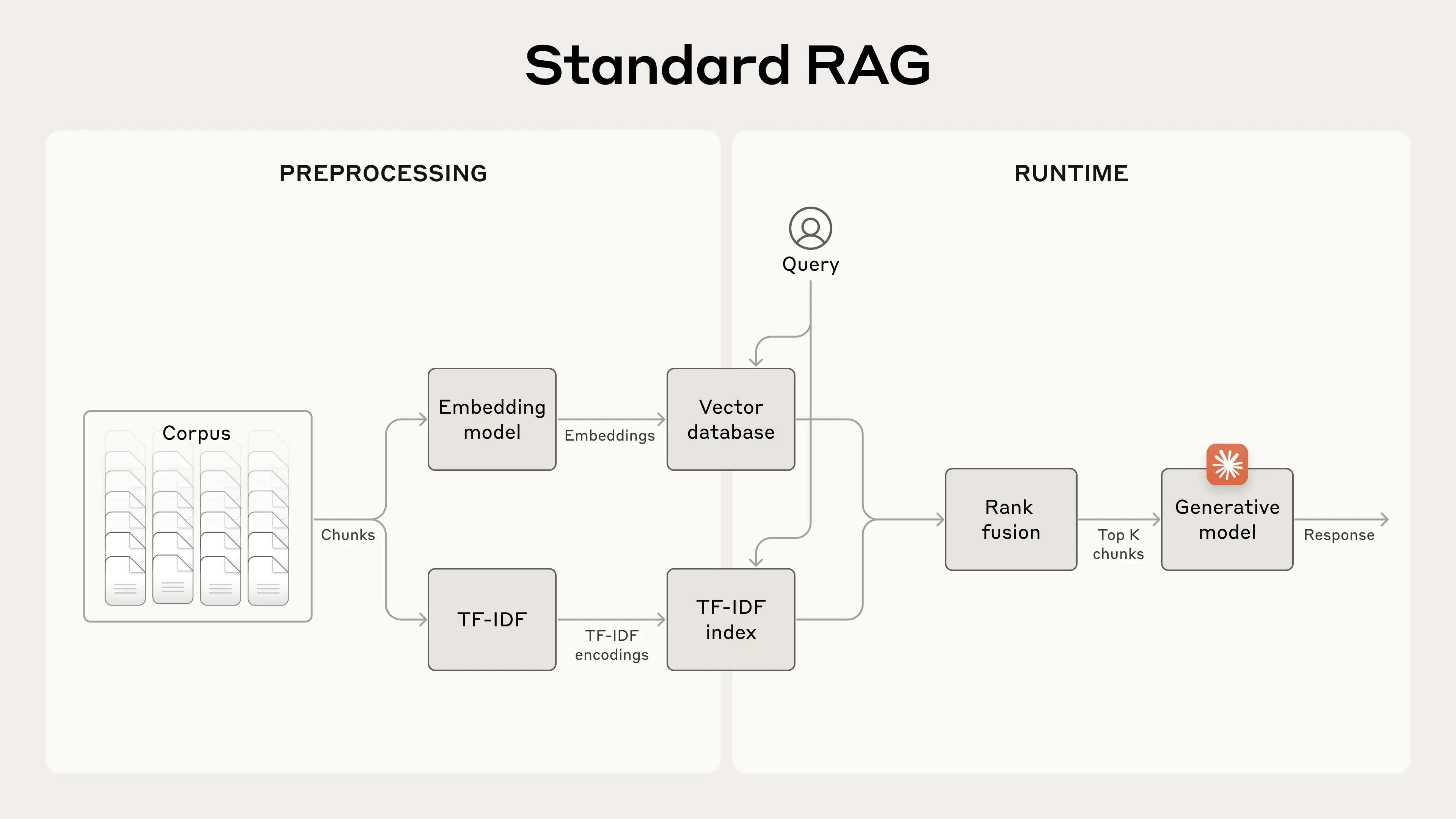
以上这张图展示了标准的RAG(检索增强生成)系统,该系统结合了嵌入模型和BM25(Best Match 25)来进行信息检索。具体流程如下:
-
预处理阶段:将知识库(Corpus)拆分为小的文本块(chunks),并通过两种途径进行处理:
-
使用嵌入模型生成这些文本块的语义嵌入(embeddings),然后将其存储到向量数据库中。
-
同时使用TF-IDF(词频-逆文档频率)为文本块创建词汇权重的编码,并将这些编码存储到TF-IDF索引中。
-
-
运行时阶段:当用户提出查询(query)时,系统会通过向量数据库和TF-IDF索引来找到最相关的文本块。
-
向量数据库基于语义相似性返回相关结果,而TF-IDF则通过词汇匹配找到精确的匹配结果。
-
这些结果通过排名融合(Rank Fusion)技术进行组合和去重,最终选出前K个最相关的文本块。
-
-
生成响应:选出的前K个文本块被传递给生成模型(Generative model),模型根据这些上下文生成最终的响应。
虽然这种方法能够以较低的成本应对庞大的知识库,远远超过单个提示能够容纳的范围,但传统的RAG系统有一个显著的局限性:它们往往会破坏信息的上下文。
传统RAG中的上下文难题
在传统的RAG系统中,文档通常会被拆分成较小的文本块,以提高检索效率。尽管这种做法在许多应用场景中表现良好,但当某些文本块缺乏足够的上下文时,就会产生问题。
举个例子,假设你的知识库中包含了一些财务信息(比如美国SEC的文件),然后你收到了这样一个问题:“ACME公司在2023年第二季度的收入增长是多少?”
一个相关的文本块可能包含这样的内容:“该公司收入比上一季度增长了3%。” 然而,这一块内容本身并没有明确提到是哪家公司,也没有提及具体的时间段。因此,即使检索到了这一块信息,由于缺乏完整的上下文,系统很难准确地回答问题或有效利用这些信息。
这种上下文丢失的问题,使得传统RAG在面对复杂问题时,常常无法提供最相关的答案,影响了AI模型的整体表现。
引入“上下文检索”
上下文检索(Contextual Retrieval)通过在每个文本块嵌入前预先添加块特定的解释性上下文,解决了传统RAG中的上下文丢失问题。这种方法包括两个关键技术:上下文嵌入(Contextual Embeddings)和上下文BM25(Contextual BM25)。
让我们回到前面提到的SEC文件的例子。下面是如何通过上下文检索转换一个文本块的示例:
-
原始文本块:
"该公司收入比上一季度增长了3%。"
-
上下文化后的文本块:
"这是来自ACME公司2023年第二季度SEC文件的内容;上一季度的收入为3.14亿美元。该公司收入比上一季度增长了3%。"
在这个例子中,上下文嵌入通过在每个文本块前面添加特定的背景信息,使其更完整、更易于理解。这样,系统可以更好地利用这些信息进行检索和回答问题。
需要注意的是,以前也有一些方法试图通过上下文来改进检索,比如为文本块添加通用的文档摘要、假设性嵌入和基于摘要的索引。但经过Anthropic团队的实验发现,这些方法效果有限,表现远不如上下文检索。
如何实现“上下文检索”
上下文检索是一种预处理技术,它能够显著提高检索的准确性。但是,手动为知识库中的成千上万甚至上百万个文本块添加上下文信息是一个巨大的工作量。为了更高效地实现上下文检索,Anthropic借助了Claude模型。Anthropic团队编写了一个提示,指示模型为每个文本块生成简洁的块特定上下文,并结合整个文档的背景进行解释。以下是Anthropic团队为Claude 3 Haiku设计的提示:
<document>
{{WHOLE_DOCUMENT}}
</document>
这里是希望在整个文档中定位的文本块
<chunk>
{{CHUNK_CONTENT}}
</chunk>
请为该文本块提供简短且简洁的上下文,以帮助提升该文本块的检索准确性。只回答简短的上下文,其他内容不必回答。
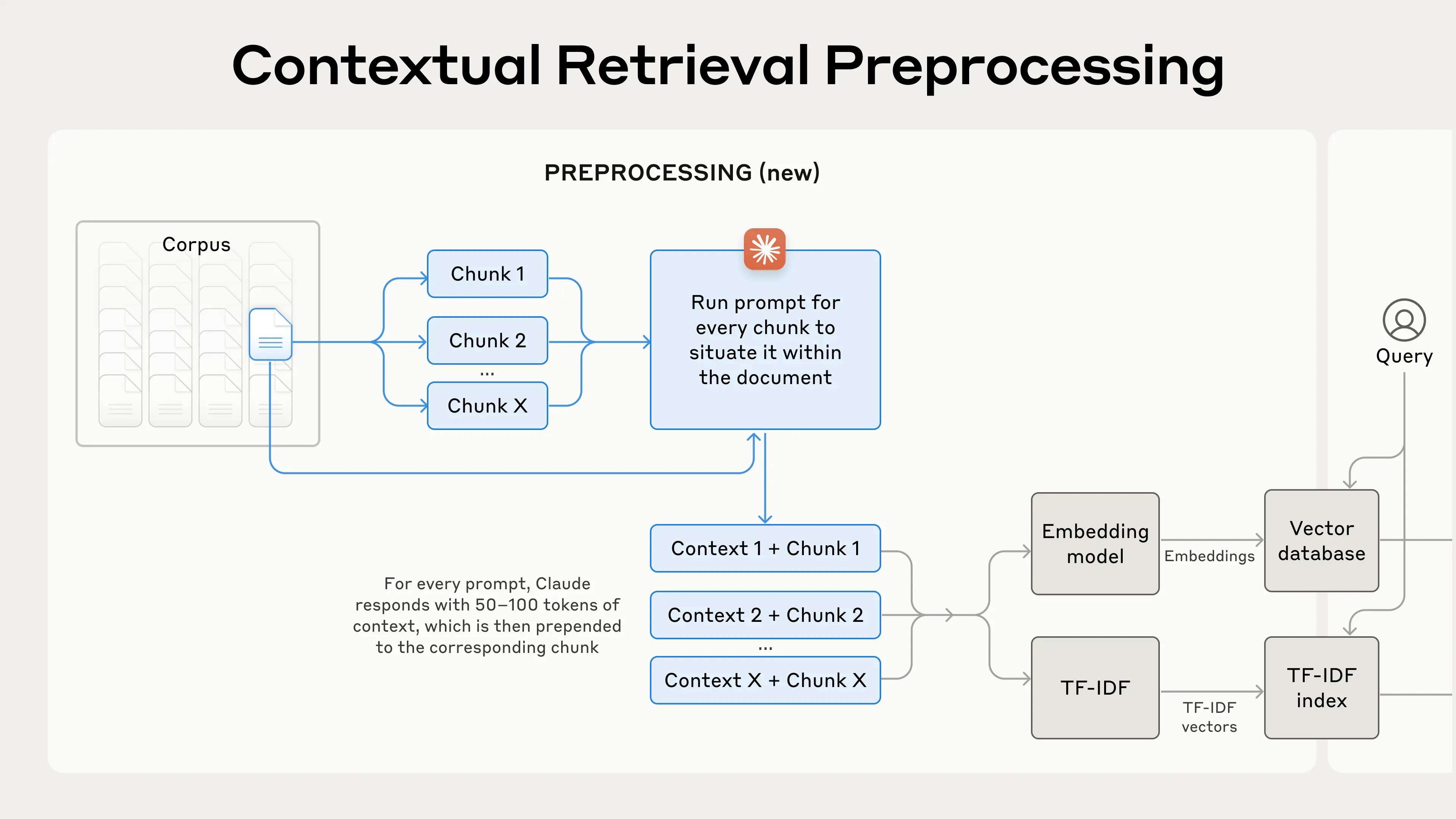
Claude生成的上下文通常包含50到100个token,在将文本块进行嵌入和创建BM25索引之前,这些上下文会被预先添加到每个文本块的前面。通过这种方式,每个文本块都带有其专属的上下文信息,从而使模型在检索时能够更准确地理解和使用这些信息。
以下是预处理流程的实际操作示例:
使用提示缓存技术降低上下文检索的成本
得益于Claude的提示缓存(Prompt Caching)功能,可以在较低的成本下实现上下文检索。提示缓存的优势在于,你不需要为每个文本块重复传入整个参考文档。只需将文档一次性加载到缓存中,之后可以直接引用缓存中的内容。假设每个文本块为800个token,一个文档为8000个token,加上50个token的上下文指令和每块100个token的上下文,生成上下文化文本块的一次性成本仅为1.02美元每百万个文档tokens。
方法论(Methodology)
Anthropic团队在多个知识领域(如代码库、小说、ArXiv论文、科学论文)进行了实验,测试了不同的嵌入模型、检索策略和评估指标。
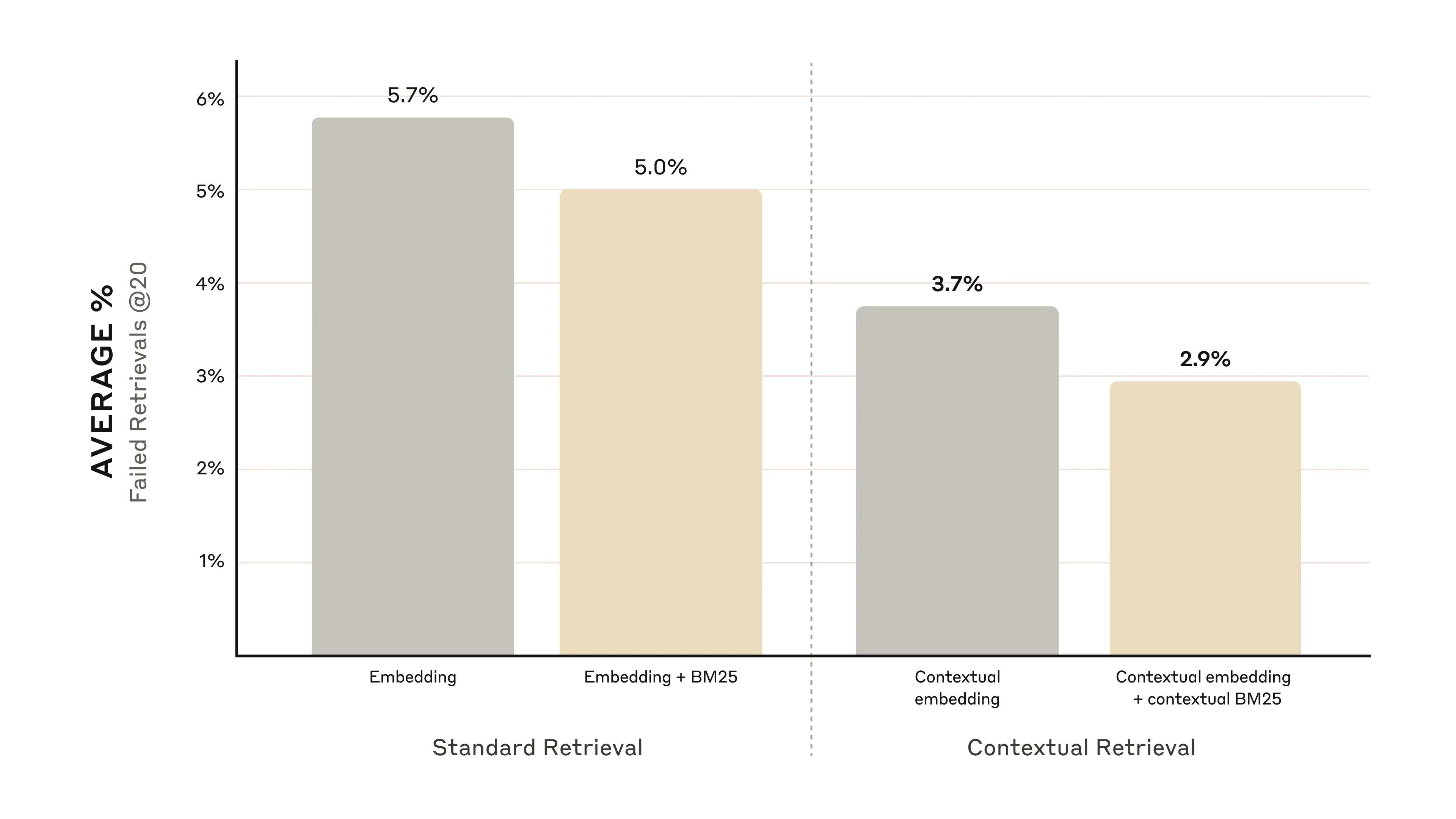
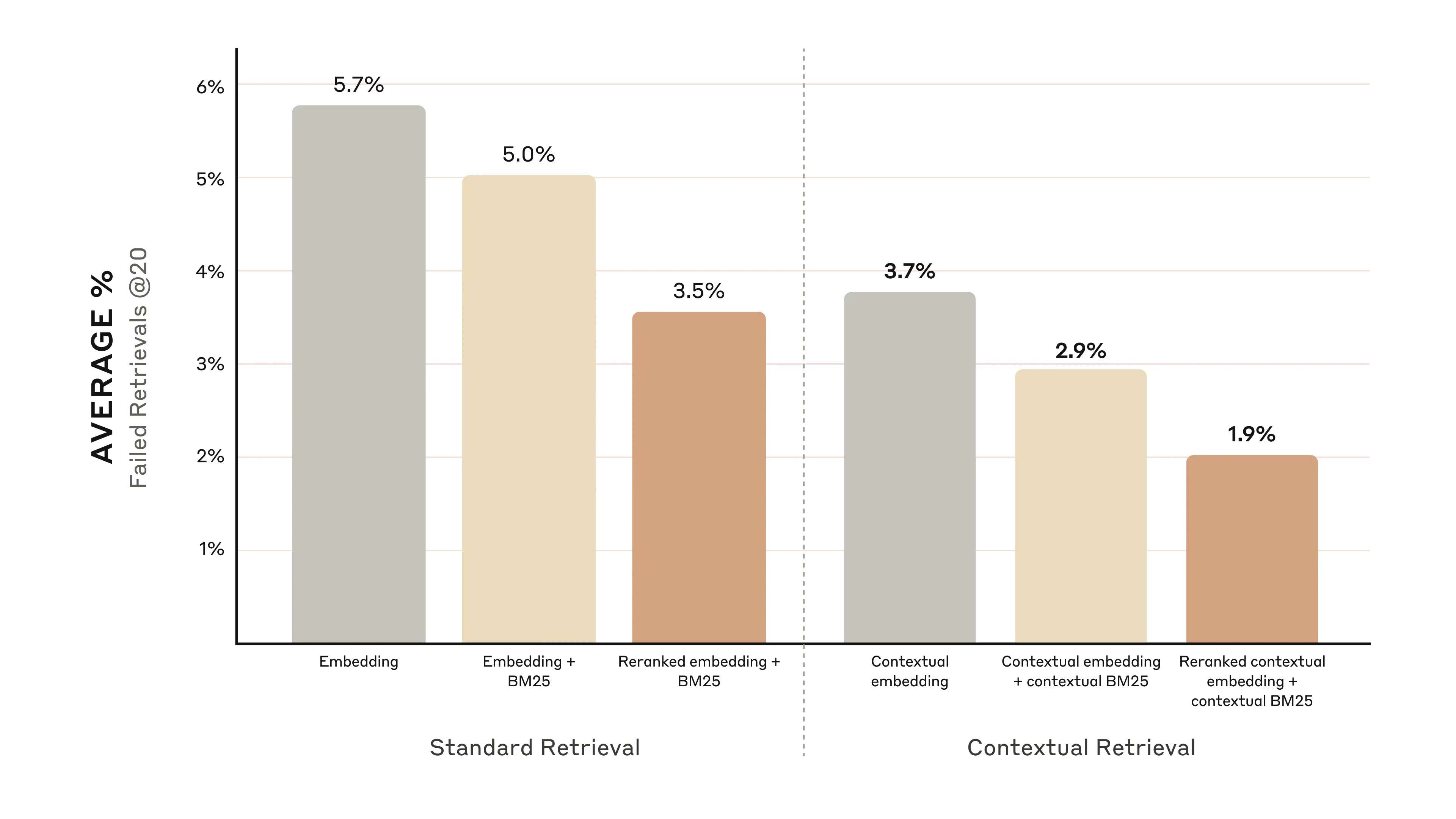
下图展示了在所有知识领域中,使用表现最优的嵌入配置(Gemini Text 004)并检索前20个文本块的平均表现。使用1 minus Recall@20作为评估指标,衡量在前20个文本块中未能检索到相关文档的比例。完整的实验结果请见附录——上下文化处理在评估的所有嵌入源组合中都提升了性能。
性能提升
实验表明:
-
上下文嵌入将前20个文本块的检索失败率降低了**35%**(从5.7%降至3.7%)。
-
上下文嵌入与上下文BM25结合,将前20个文本块的检索失败率降低了**49%**(从5.7%降至2.9%)。
实施注意事项
-
文本块边界:如何拆分文档的块会影响检索性能。块的大小、边界和重叠区间的选择都很重要。
-
嵌入模型:虽然上下文检索在Anthropic测试的所有嵌入模型上都提升了性能,但某些模型受益更多。Anthropic团队发现Gemini和Voyage嵌入特别有效。
-
自定义上下文化提示:虽然Anthropic提供的通用提示效果不错,但根据你的特定领域或用例定制提示,可能会取得更好的效果。例如,针对某些领域,可以在提示中包含关键术语的词汇表,这些术语可能只在知识库的其他文档中定义。
-
文本块数量:在上下文窗口中增加更多文本块,可以提高包含相关信息的概率。然而,信息过多可能会对模型造成干扰,因此有一个合理的上限。Anthropic团队尝试了传递5、10和20个文本块,结果显示传递20个文本块效果最好(具体比较见附录),但你也可以根据自己的用例进行实验。
建议始终进行评估:通过传递上下文化后的文本块,并区分上下文与文本块本身,可以改进生成的响应质量。
通过重新排序进一步提升性能
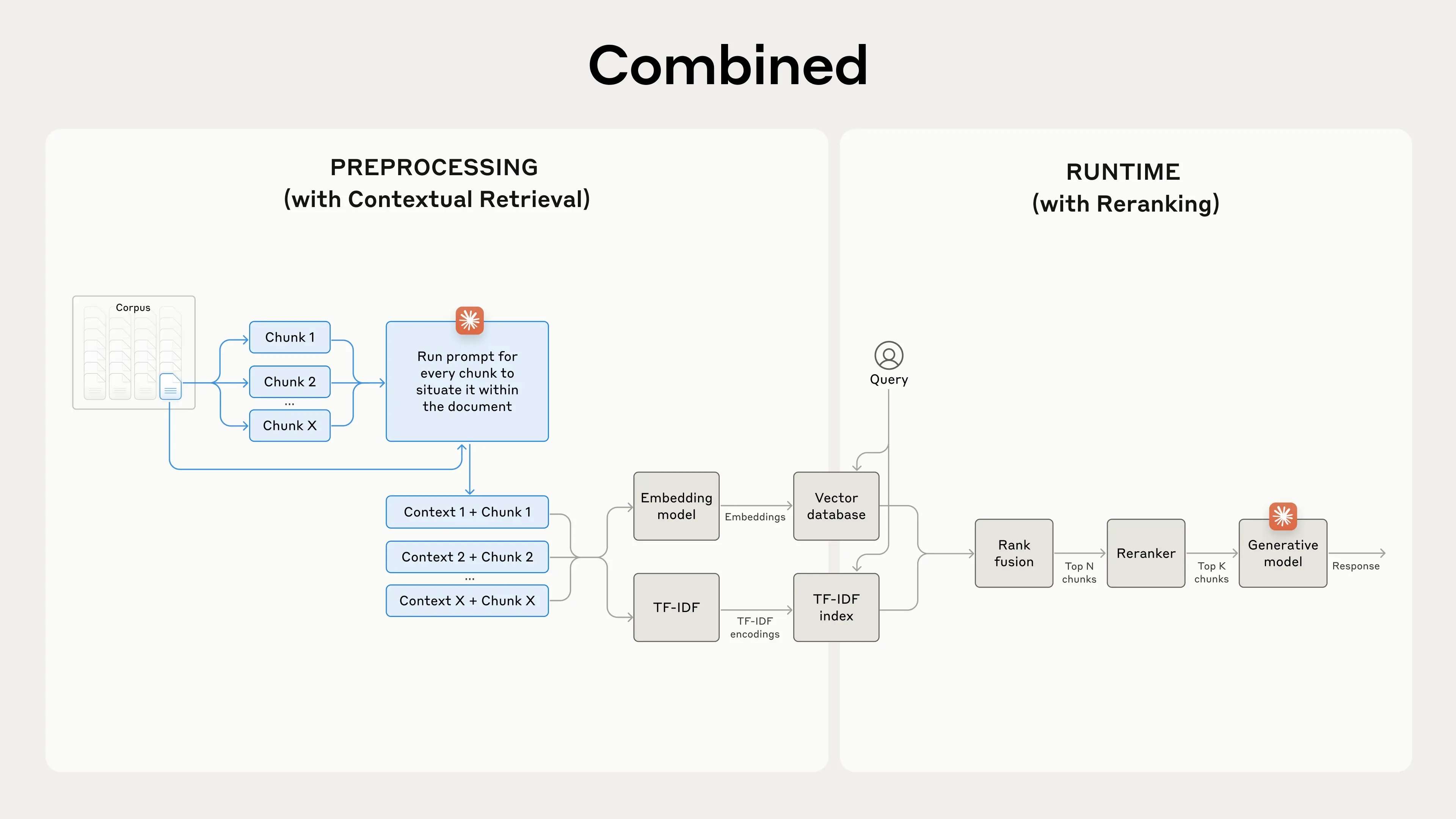
在最后一步中,Anthropic将上下文检索与另一项技术结合起来,进一步提升系统性能。在传统的RAG系统中,AI会在知识库中检索潜在相关的文本块。对于较大的知识库,这一初步检索常常会返回大量块——有时多达数百个,它们的相关性和重要性各不相同。
重新排序(Reranking)是一种常用的过滤技术,旨在确保只有最相关的文本块被传递给模型。重新排序不仅能提高响应的质量,还能减少处理成本和延迟,因为模型需要处理的信息量减少了。关键步骤如下:
-
进行初步检索,获取潜在相关的文本块(Anthropic使用了前150个);
-
将前N个文本块连同用户的查询一起传递给重新排序模型;
-
使用重新排序模型为每个文本块打分,依据它们与提示的相关性和重要性,选择前K个文本块(Anthropic选择了前20个);
-
将这前K个文本块作为上下文传递给模型,生成最终的响应。
通过结合上下文检索与重新排序,可以最大化检索的准确性。
性能提升
目前市场上有多个重新排序模型可供选择。Anthropic使用了Cohere的重新排序器进行了测试。Voyage也提供了类似的重新排序器,但Anthropic没有测试。实验表明,在各种领域中,添加重新排序步骤可以进一步优化检索效果。
具体而言,Anthropic研究团队发现重新排序后的上下文嵌入和上下文BM25将前20个文本块的检索失败率降低了**67%**(从5.7%降至1.9%)。
延迟和成本考虑
在使用重新排序时,必须考虑其对延迟和成本的影响,特别是在需要重新排序大量文本块的情况下。由于重新排序在运行时增加了一个额外的步骤,即使重新排序器可以并行处理所有文本块,仍会不可避免地增加少量延迟。因此,在重新排序更多文本块以提升性能和减少文本块以降低延迟和成本之间存在一个权衡点。Anthropic建议根据具体的使用场景,调整设置以找到合适的平衡点。
结论
Anthropic团队进行了大量测试,对各种技术组合进行了比较,包括嵌入模型、BM25的使用、上下文检索的应用、重新排序的效果,以及检索的前K个结果的数量。这些测试覆盖了不同类型的数据集,总结如下:
-
嵌入+BM25的组合优于仅使用嵌入;
-
在测试的所有嵌入模型中,Voyage和Gemini的表现最佳;
-
向模型传递前20个文本块的效果优于仅传递前10个或前5个;
-
为文本块添加上下文可以大幅提升检索准确性;
-
重新排序的表现明显优于没有重新排序的情况。
这些优势可以叠加。要最大化性能提升,可以结合Voyage或Gemini的上下文嵌入,搭配上下文BM25,再加上重新排序步骤,并传递前20个文本块作为提示。
附录 I
以下是不同数据集上的测试结果分解,涵盖了嵌入提供商的表现、BM25与嵌入结合的效果、上下文检索的使用以及重新排序对前20个检索结果的影响。

更多关于前10个和前5个检索结果的表现分析,以及每个数据集的示例问题和答案,请参考附录 II。
参考资料
-
Introducing Contextual Retrieval - Anthropic:https://www.anthropic.com/news/contextual-retrieval
-
Appendix II:https://assets.anthropic.com/m/1632cded0a125333/original/Contextual-Retrieval-Appendix-2.pdf
都读到这里了,点个赞鼓励一下吧,小手一赞,年薪百万!😊👍👍👍。关注我,AI之路不迷路,原创技术文章第一时间推送🤖。















 474
474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









