







Druid简介
- 什么是Druid?
- 基本概念
- 运行原理
什么是Druid?
Druid是一个用于大数据实时查询和分析的高容错、高性能开源分布式时序数据库系统。它主要解决的是对于大量的基于时序的数据进行聚合查询。数据可以实时摄入,进入到Druid后立即可查,同时数据是几乎是不可变。通常是基于时序的事实事件,事实发生后进入Druid,外部系统就可以对该事实进行查询。
基本概念
dataSource:数据源
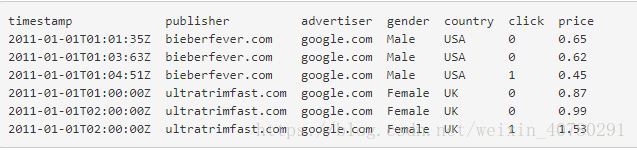
作用:提供Druid摄入的数据,并将数据按照一定的格式组织起来。数据格式如图所示:
分为三部分:时间戳列,维度列,指标列。对应上图中就是:时间戳列(timestamp),维度列(publisher,advertiser,gender,country),指标列(click,price)。其中时间戳列格式应和图中一致,日期使用-作为分隔符,时间使用:为分隔符,T和Z可以不用;维度列作为不同的角度去进行分组的标志;指标列可以进行各种聚合操作,如计数,求和等运算,一般要求为数值型。metadata:元数据
一组描述任务和切片后的数据存放位置以及压缩格式的一组数据。元数据的简单理解就是描述数据的数据。一般存放在mysql数据库中。segment:切片数据
切片数据是将数据源提供的数据按照时间进行切片聚合后的进行压缩的一组数据。时间格式一般可设置为min,hour,day,month,year等;聚合操作可以是计数求和等运算;压缩格式一般是bz4,一般不是自己进行设置,通常为默认值。

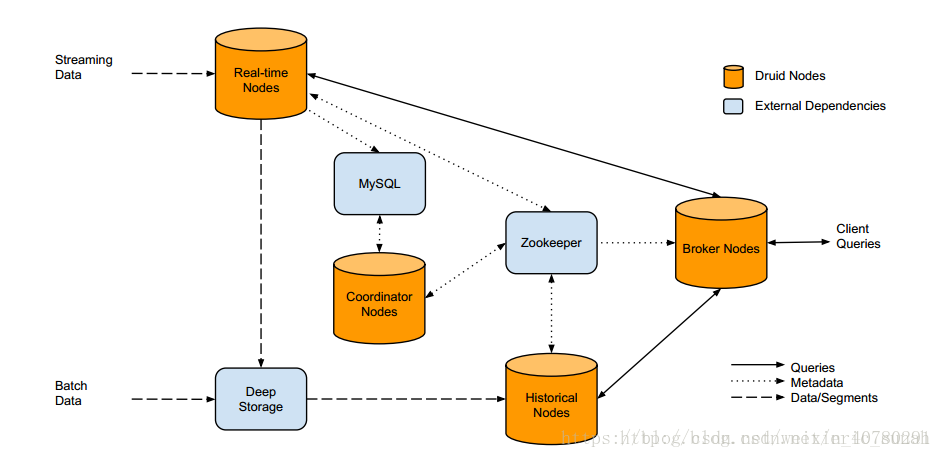
运行原理
- 组成部分:
- historical:历史节点
主要负责segment的下载以及为broker提供查询服务。 - realtime:实时节点
主要进行数据的摄取,存放当前时间窗口内的数据以及为broker提供查询服务。 - coordinate:协调节点
主要沟通协调historical将segment从hdfs中下载下来,将摄入任务分发给realtime,将查询任务分发给broker。 - broker:分发节点
主要提供查询服务。 - indexing service:索引服务
主要是提供批量数据的摄入以及进行聚合操作。
- historical:历史节点
- 摄入:
- 摄入过程
如上图所示,数据分为批量数据和流式数据,批量数据包括json,csv,tsv等,流式数据包括从hadoop,kafka,storm等来的数据。批量数据一般存放在hdfs中,可以下载到historical中;流式数据一般通过realtime进行切片聚合,将metadata存放在mysql中,将segment存放在hdfs中,然后通知historical下载。
- 摄入过程
- 查询:
查询的方式只能是通过HTTP请求发送json文件的方式进行查询,且只支持单表查询不支持链接查询。
如上图所示,当查询任务进入Druid,broker根据查询任务的条件,通知realtime和historical进行查询,然后将查询结果返回到broker,broker将数据合并后返回给用户。














 1343
1343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









