






对于数据处理的新手来说,你可能听说过:标签编码、特征编码、独热编码 等类似的概念
但是在用的时候却不知道什么时候用哪个,彻底混为一谈
归根结底,还是对概念混淆了,或者你当时看的帖子就是错的,被误导了。
其实这样的错误帖子很多,csdn、博客园,一抓一大把,被误导也很正常
误导了没关系,忘掉错误的,从头开始就行
ok,let's go
首先
需要明确一点,在大多数模型算法中,对于数值型数据,可以直接拿来训练模型。
但是对于类别型特征,算法不能把字符数据像数值数据一样构成数组矩阵,所以模型会直接报错。
这种情况的处理也很容易,使用下面几种方法进行简单的特征转换即可。
这么说你可能不是很理解,举个例子:
现在有一个用户数据集,其中用户字段包括:身高、学历、性别、婚姻状态、等级、收入等,预通过这些用户字段 去预测该用户是否会发生逾期行为
用户字段里面除了身高和收入,其他都是类别型特征,如下:
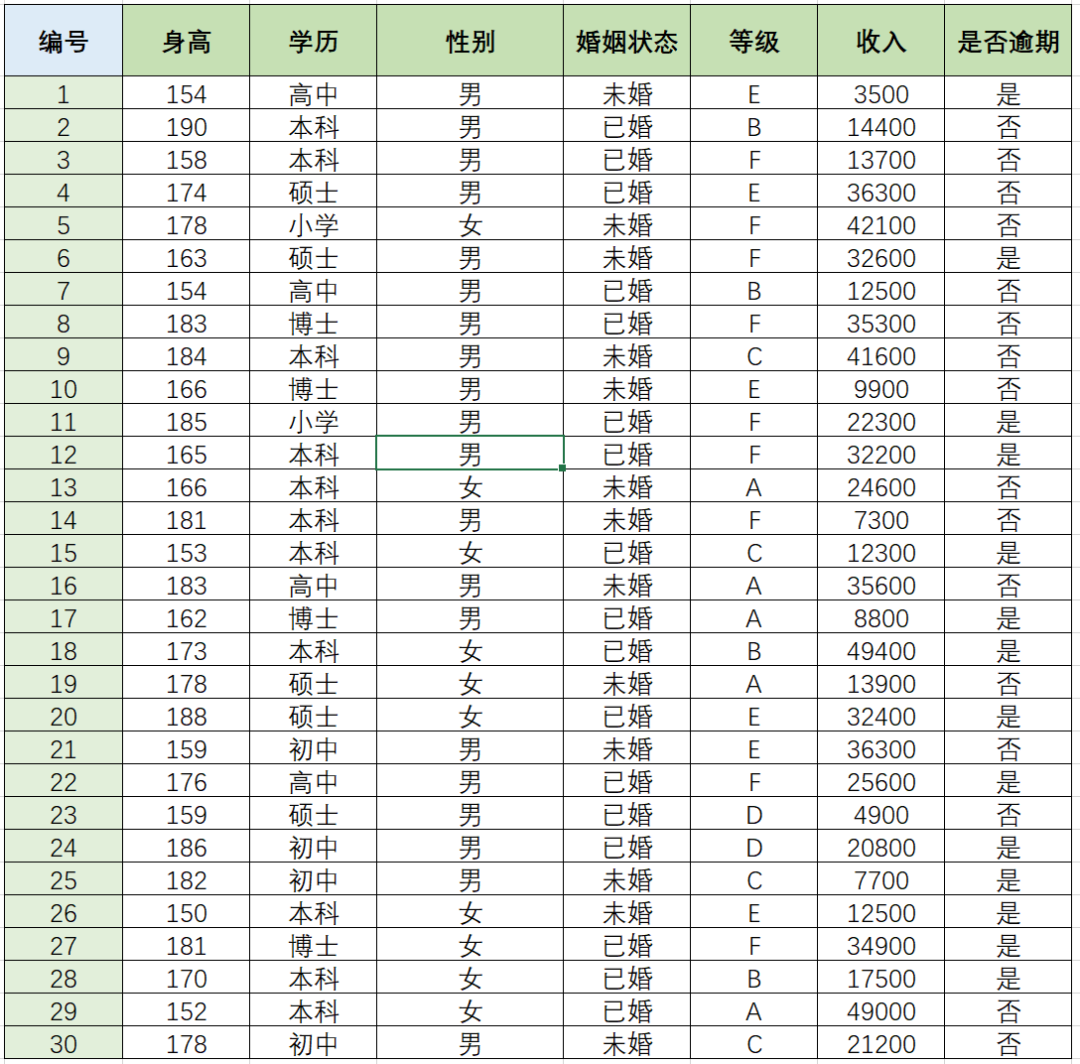
一般情况下,我们是这样转换的:
是否逾期:是 转换为 1、否 转换为 0
性别特征:男 转换为 1、女 转换为 0
....
所以,在 sklearn 中,提供了下面几种方法用来实现这样的转换:
▶第一种:LabelEncoder
LabelEncoder 能够将分类特征转换为分类数值,使用起来也很简单
直接看代码:
from sklearn.preprocessing import LabelEncoder
# 读入数据
df_data = pd.read_csv("数据.csv", encoding='gbk')
df_data_2 = df_data.copy()
# 特征转换
le = LabelEncoder()
df_data_2['是否逾期_fit'] = le.fit_transform(df_data['是否逾期'])
df_data_2['性别_fit'] = le.fit_transform(df_data['性别'])
文中的代码用到了 fit_transform 函数,不清楚用法的点这篇,讲的很透彻了:做数据处理,你连 fit、transform、fit_transform 都分不清?
转换后的效果如下:
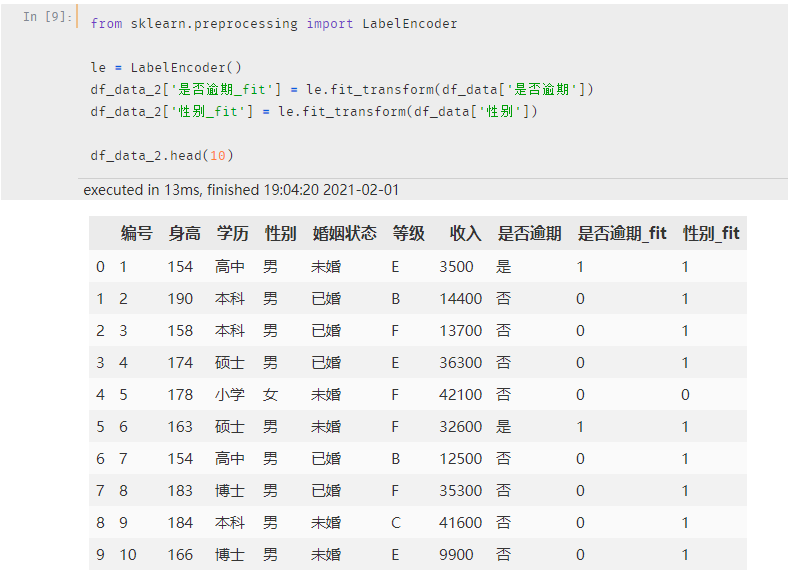
可以看到,此种方法只能一次转换一个特征,这个比较 适合于标签列 进行特征转换
像上面的需要转换的特征比较多的情况,可以用第二种方法
▶第二种:OrdinalEncoder
OrdinalEncoder 可以实现同样的功能,而且可以批量
直接看代码:
from sklearn.preprocessing import LabelEncoder, OrdinalEncoder
df_data_3 = df_data.copy()
# 特征转换
df_data_3['是否逾期'] = le.fit_transform(df_data['是否逾期'])
df_data_3[['学历', '性别', '婚姻状态', '等级']] = OrdinalEncoder().fit_transform(df_data[['学历', '性别', '婚姻状态', '等级']])
转换后的效果如下:
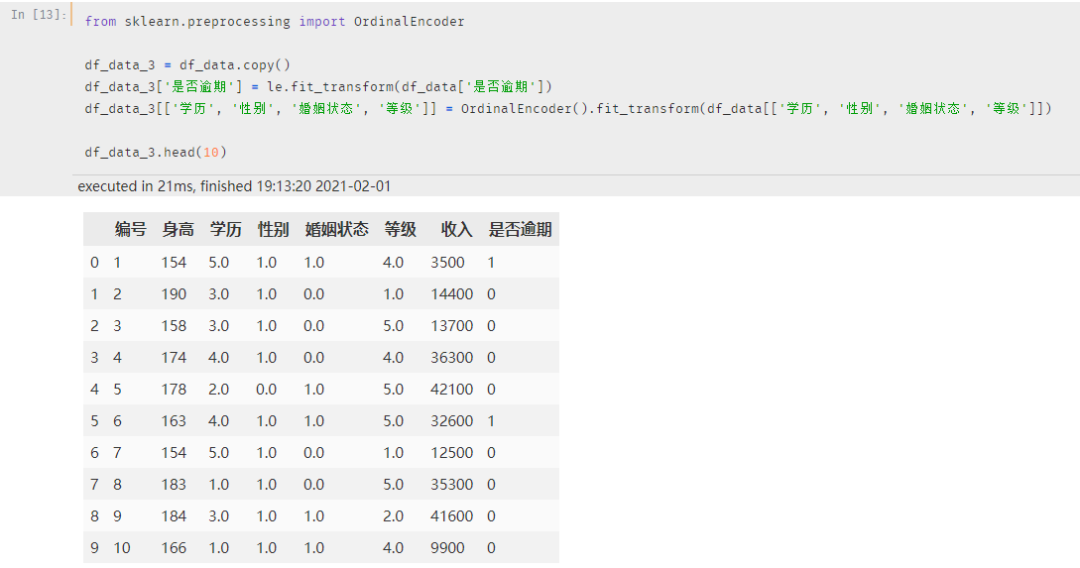
怎么样,是不是觉得上面这种方法转换起来是不是更快一些?
快是快,但是,上面这种方法存在本质上的错误!
首先,我们转换的目的是为了让算法在训练模型的时候,能够将类别型特征量化,然后转换成特征矩阵进行计算等操作
但是,实际上,你将性别转换为 0 和 1,对于算法来说,1 和 0 是可以进行计算的
将学历转换为 1、2、3、4、5,算法会认为 3 对应的学历是 1 的 3倍。
事实上,我们知道,性别男和女是不可达的,本身就互斥的概念不能通过数值算出来,学历你总不能说 5个小学学历=1个硕士学历 吧?
类似的特征还有:颜色、等级、邮编 等,都不可以直接用上面的方式进行转换
正确的方式是这样的:
对了性别特征:用两列表示,男性列+女性列
对于婚姻状态特征:也是两列,已婚列+未婚列
....
对应的处理效果是这样的:

在 sklearn 中,可以用第三种方法实现这样的特征转换
▶第三种:OneHotEncoder
OneHotEncoder:独热编码,可以通过创建哑变量的方式进行特征转换。
代码如下:
from sklearn.preprocessing import OneHotEncoder
df_data_4 = df_data.copy()
# 特征转换-独热编码
df_data_onehot = OneHotEncoder().fit_transform(df_data[['学历', '性别', '婚姻状态']])
df_data_onehot.toarray()
转换后的效果如下:
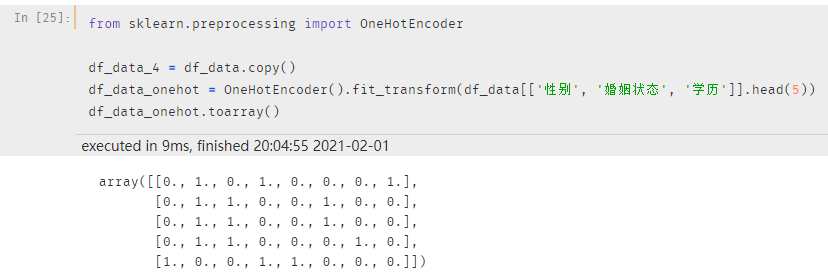
最终是一个二维数组的形式,之后需要进一步的将二维数组转换为 DataFrame,然后和原始的 DataFrame 进行合并,并且删除原特征。
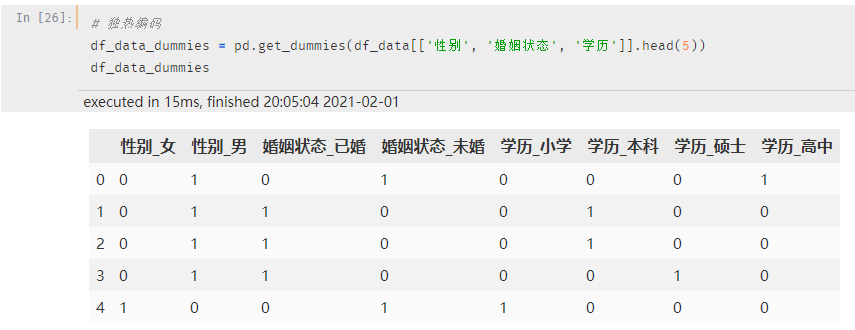
这一步有一个 更简单、高效 的方法:使用 Pandas 的 get_dummies 函数
# 独热编码
df_data_dummies = pd.get_dummies(df_data[['性别', '婚姻状态', '学历']].head(5))
df_data_dummies
转换后的效果是一样的:
▶小技巧
上面三种方法针对的特征转换都是特征 1V1,或者 1V多 的场景。
如果是需要将 多个类别值 转换成 1个 特征 呢?
比如在 泰坦尼克号生还者预测 里面,乘客姓名中的称呼就可以作为乘客的 title 进行转换。
例如:
Miss、Mlle、Ms、Mme 为一个等级
Col、Major、Capt 为一个等级
Master、Don、Dona、Countess、Jonkheer 为一个等级
根据不同称呼将乘客映射为不同的等级,这种处理方式能极大的提高模型预测的正确率。
对应的代码可以这样写:
title_mapping = {'Mr': 1, 'Miss': 2, 'Mlle': 2, 'Ms': 2, 'Mrs': 2, 'Mme': 2,
'Rev': 3, 'Dr': 3, 'Col': 4, 'Major': 4, 'Capt': 4,
'Master': 5, 'Don': 5, 'Dona': 5, 'Lady': 5, 'Countess': 5, 'Jonkheer': 5, 'Sir': 5,
}
# 对 title 信息进行转换
df_data['TitleType'] = df_data['Title'].map(title_mapping)
本文总结
今天的文章比较简单,稍微总结一下:
特征转换一共有三种方式,分别是:LabelEncoder、OrdinalEncoder 和 OneHotEncoder
其中,第一种方式适合标签列,将 是/否、好客户/坏客户 等类别标签进行数值转换
第二种方式适合特征列,将可以量化的特征,如:年龄、重量、长度、温度等特征进行批量数值转换
第三种方式适合特征列,将无法量化、不能用数值代表内在含义的特征进行独热编码。
另外还介绍了如何将 多V1 的数值进行转换操作。
最后,本文中用到的数据集也比较简单,需要的同学可以直接下载练练手
链接:https://pan.baidu.com/s/14wi199hcbnrp5tvO91F5DQ
提取码:1025
推荐阅读














 757
757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









