






本文来自J哥的好友小屁孩i,他目前因为知识需求入坑大数据分析。在学习过程中,整理了这篇文章,如果内容有出错的地方希望大家在评论区加以指正,不胜感激!
01
数据分类
正所谓物以类聚人与群分,生活里很多东西都存在着分类,当你进入超市的时候有着“日常生活用品”,“零食区”,“衣服类”等等的分类,一个分类里有不同的商品。
02
分类方法
那么问题来了,怎么分类呢?按照什么分类呢?我们仍然用超市的分类来说明,在超市的分类中,我们可以看到在同一个类中的商品用途是差不多的。也有的分类是按照商品的性质来分的。如果是按照商品的用途这一单一的规则来分类的话,我们通常叫这种分类方式为OneR算法(One Rule一个规律算法),这也是今天我们要说的分类方法。
03
OneR算法
那么什么是OneR算法呢?简单的来说是,根据现有的数据集,具有相同的特征值的个体最可能属于哪个类别,然后进行分类。当然这边的分类依据只是根据一种规则来进行分类的。在数据分类部分还有一些分类算法,这些算法跟OneR算法比较起来复杂了许多,而且也更加的准确。既然这样的话,也许你会问,既然还有更好用的算法为什么要用这个比较”low“的算法呢?这样说起来也对,但是这个OneR算法在很多真实数据上的应用算是很常见的了!
上面的热身结束,重头戏来了!!!
04
代码实现
1、准备数据集
要进行数据分类怎么能缺少数据集呢?这边我们将使用著名的Iris植物分类数据集,这个数据集里有150条植物信息。下面我们来导入这个数据集,根据下面的代码以及图片的展示我们可以发现这个植物分类数据集有4个特征值,分别为:sepal length、sepal width、petal length、petal width(分别表示的萼片和花瓣的长宽)
from sklearn.datasets import load_iris
import numpy as np
dataset = load_iris()
x = dataset.data
y = dataset.target
print(dataset.DESCR)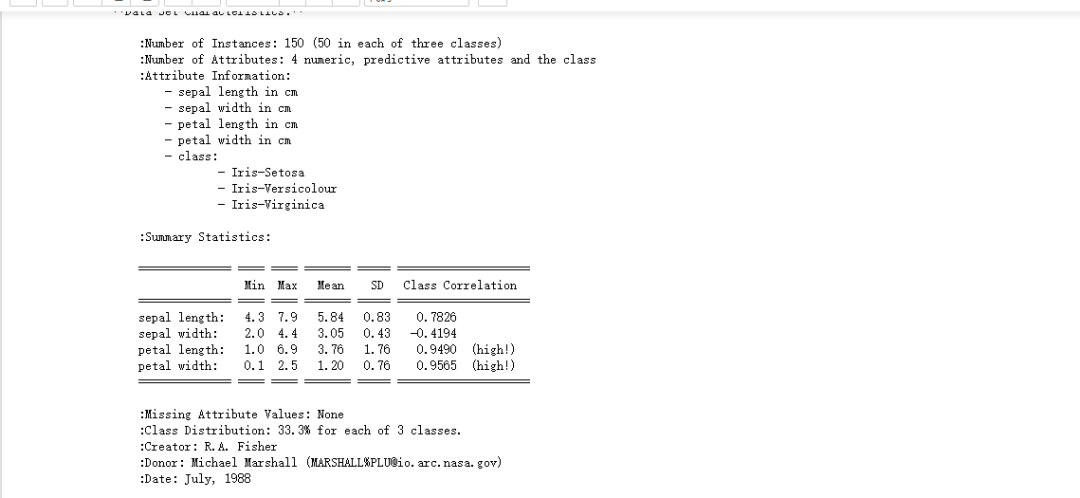
数据准备:
import numpy as np
# data 为特征值
data = dataset.data
# target为分类类别
target = dataset.target
average_num = data.mean(axis = 0)
data = np.array(data > average_num,dtype = "int")
#print(dataset) # 可以自己尝试打印看看数据内容
from sklearn.model_selection import train_test_split
# 随机获得训练和测试集
def get_train_and_predict_set():
#对应的参数意义 data(待划分样本数据) target(样本数据的结果) random_state(设置随机种子,默认值为0 如果为0则的话每次随机结果都不一样,反之是一样的)
return train_test_split(data,target, random_state=14)
data_train,data_predict,target_train,target_predict = get_train_and_predict_set()2、实现算法
我们之前就说到,我们是根据一个规则来实现分类的。首先我们先遍历每个特征的取值,对每个特征的取值,统计它在不同的类别出现的次数,然后找到最大值,并记录它在其他类别中出现的次数(为了统计错误率)。
from collections import defaultdict
from operator import itemgetter
#定义函数训练特征
def train_feature(data_train,target_train,index,value):
"""
data_train:训练集特征
target_train:训练集类别
index:特征值的索引
value :特征值
"""
count = defaultdict(int)
for sample,class_name in zip(data_train,target_train):
if(sample[index] ==value):
count[class_name] += 1
# 进行排序
sort_class = sorted(count.items(),key=itemgetter(1),reverse = True)
# 拥有该特征最多的类别
max_class = sort_class[0][0]
max_num = sort_class[0][1]
all_num = 0
for class_name,class_num in sort_class:
all_num += class_num
# print("{}特征,值为{},错误数量为{}".format(index,value,all_num-max_num))
# 错误率
error = 1 - (max_num / all_num)
#最后返回使用给定特征值得到的待预测个体的类别和错误率
return max_class,error对于某个特征,遍历其每一个特征值,每次调用train_feature这个函数的时候,我们就可以得到预测的结果以及这个特征的最大错误率,也可以得到最好的特征以及类型,下面我们进行函数的编写:
def train():
errors = defaultdict(int)
class_names = defaultdict(list)
# 遍历特征
for i in range(data_train.shape[1]):
# 遍历特征值
for j in range(0,2):
class_name,error = train_feature(data_train,target_train,i,j)
errors[i] += error
class_names[i].append(class_name)
return errors,class_names
errors,class_names = train()
# 进行排序
sort_errors = sorted(errors.items(),key=itemgetter(1))
best_error = sort_errors[0]
best_feature = best_error[0]
best_class = class_names[best_feature]
print("最好的特征是{}".format(best_error[0]))
print(best_class)
3、测试算法
# 进行预测
def predict(data_test,feature,best_class):
return np.array([best_class[int(data[feature])] for data in data_test])
result_predict = predict(data_predict,best_feature,best_class)
print("预测准确度{}".format(np.mean(result_predict == target_predict) * 100))
print("预测结果{}".format(result_predict))
我们可以发现预测的准确度为65.79%,这个准确度对于OneR算法来说已经很高啦!到此OneR算法完成啦!再次强调欢迎大家的指导批评,谢谢!
参考文献:
https://github.com/xiaohuiduan/data_mining
E N D
各位伙伴们好,詹帅本帅搭建了一个个人博客和小程序,汇集各种干货和资源,也方便大家阅读,感兴趣的小伙伴请移步小程序体验一下哦!(欢迎提建议)
推荐阅读
牛逼!Python常用数据类型的基本操作(长文系列第①篇)
牛逼!Python的判断、循环和各种表达式(长文系列第②篇)
牛逼!Python函数和文件操作(长文系列第③篇)
牛逼!Python错误、异常和模块(长文系列第④篇)














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









