




 本文详细阐述了Elasticsearch如何通过哈希算法分配文档到分片,讲解了默认路由和自定义路由的原理及优缺点,以及在用户数据管理中的应用实例。
本文详细阐述了Elasticsearch如何通过哈希算法分配文档到分片,讲解了默认路由和自定义路由的原理及优缺点,以及在用户数据管理中的应用实例。
es 是一个分布式系统,当我们存储一个文档到 es 上之后,这个文档实际上是被存储到 master 节点中的某一个主分片上。
例如新建一个索引,该索引有两个分片,0个副本,如下:
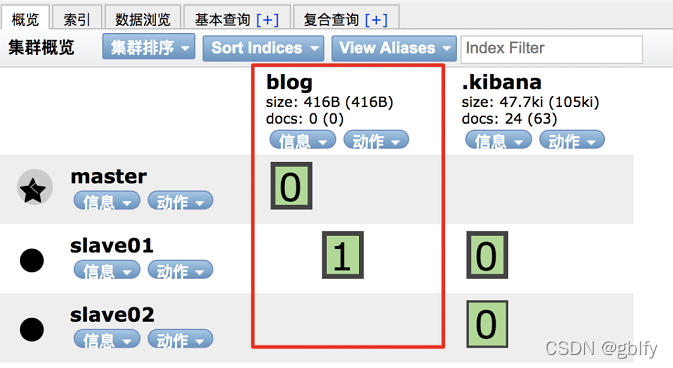
接下来,向该索引中保存一个文档:
PUT blog/_doc/a
{
"title":"a"
}
文档保存成功后,可以查看该文档被保存到哪个分片中去了:
GET _cat/shards/blog?v
查看结果如下:
index shard prirep state docs store ip node
blog 1 p STARTED 0 208b 127.0.0.1 slave01
blog 0 p STARTED 1 3.6kb 127.0.0.1 master
从这个结果中,可以看出,文档被保存到分片 0 中。
那么 es 中到底是按照什么样的规则去分配分片的?
es 中的路由机制是通过哈希算法,将具有相同哈希值的文档放到一个主分片中,分片位置的计算方式如下:
shard=hash(routing) % number_of_primary_shards
routing 可以是一个任意字符串,es 默认是将文档的 id 作为 routing 值,通过哈希函数根据 routing 生成一个数字,然后将该数字和分片数取余,取余的结果就是分片的位置。
默认的这种路由模式,最大的优势在于负载均衡,这种方式可以保证数据平均分配在不同的分片上。但是他有一个很大的劣势,就是查询时候无法确定文档的位置,此时它会将请求广播到所有的分片上去执行。另一方面,使用默认的路由模式,后期修改分片数量不方便。
当然开发者也可以自定义 routing 的值,方式如下:
PUT blog/_doc/d?routing=javaboy
{
"title":"d"
}
如果文档在添加时指定了 routing,则查询、删除、更新时也需要指定 routing。
GET blog/_doc/d?routing=javaboy
自定义 routing 有可能会导致负载不均衡,这个还是要结合实际情况选择。
典型场景:
对于用户数据,我们可以将 userid 作为 routing,这样就能保证同一个用户的数据保存在同一个分片中,检索时,同样使用 userid 作为 routing,这样就可以精准的从某一个分片中获取数据。


















 1252
1252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











