







文章目录
1.传统日志采集存在哪些问题
2.分布式日志采集有哪些方案
3.ElasticSeach+Logstash+Kibana作用
4.ELK为何需要结合kafka
5.基于docker构建ELK
6.springboot项目整合elk实现异步日志采集
1. 传统日志采集存在哪些优缺点
在传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常低下。因此我们需要集中化的管理日志,ELK则应运而生。
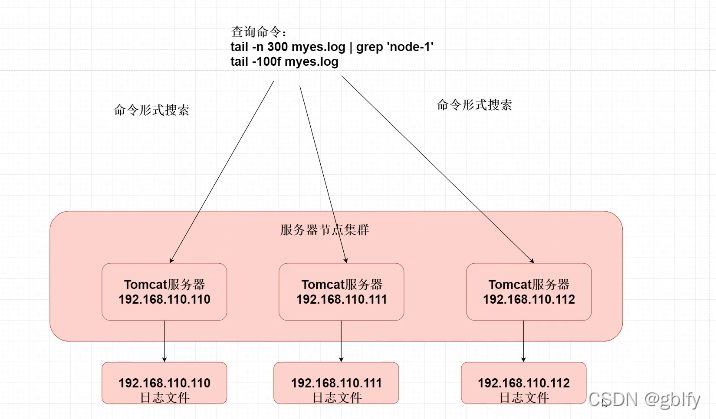
2. Elk采集日志的原理
Elk
E=ElasticSeach(存储日志信息)
l Logstash(搬运工)
K Kibana连接到我们ElasticSeach图形化界面查询日志
Elk采集日志的原理:
1. 需要在每个服务器上安装Logstash(搬运工)
2. Logstash需要配置固定读取某个日志文件
3. Logstash将我们的日志文件格式化为json的格式输出到es中
4. 开发者使用Kibana连接到ElasticSeach 查询存储日志内容。
ELK日志收集原理
ELK=ElasticSeach+Logstash+Kibana,日志收集原理如下所示。
1、每台服务器集群节点安装Logstash日志收集系统插件
2、每台服务器节点将日志输入到Logstash中
3、Logstash将该日志格式化为json格式,根据每天创建不同的索引,输出到ElasticSearch中
4、浏览器使用安装Kibana查询日志信息
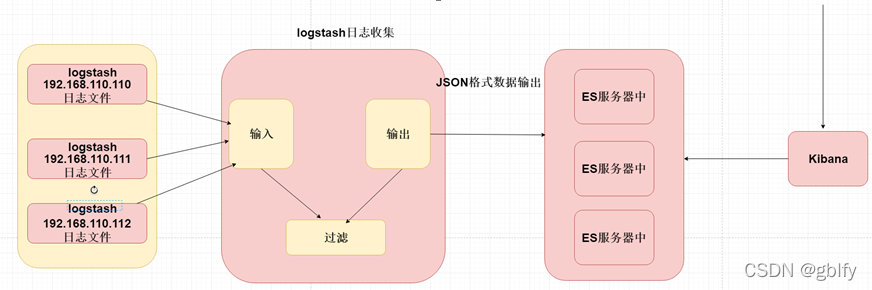
该方案的缺点:就是在每个服务器节点上都会安装Logstash做读写日志IO操作,可能性能不是很好,而且比较冗余。
3. 为什么需要将日志存储在ElasticSeach 而不是mysql中呢
ElasticSeach 底层使用到倒排索引 搜索日志效率高
4. 为什么需要使用elk+kafka
1.如果单纯的使用elk的话,服务器节点扩容 需要每个服务器上安装我们Logstash
步骤比较冗余。
2. Logstash读取本地日志文件,可能会对本地的磁盘io性能会有一定影响。
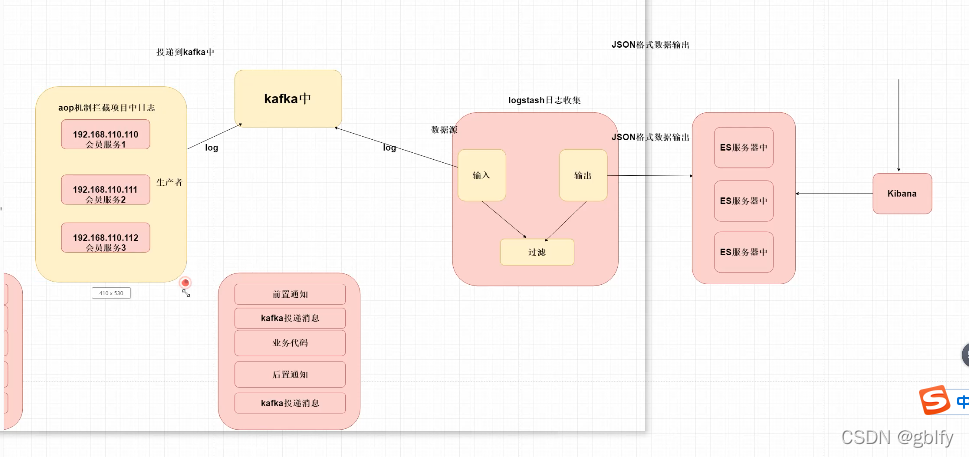
5. elk+kafka原理
- springboot项目会基于aop的方式拦截系统中日志
日志(错误日志)
错误日志:异常通知
请求与响应日志信息—前置或者环绕通知。 - 将该日志投递到我们kafka中 注意该过程一定要是异步的形式。
- Logstash 数据源—kafka 订阅kafka的主题 获取日志消息内容
- 在将日志消息内容输出到es中存放
开发者使用Kibana连接到ElasticSeach 查询存储日志内容。
6. elk+kafka 环境的构建
https://gblfy.blog.csdn.net/article/details/123433995















 917
917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











