







贝叶斯要解决的问题:
1、正向概率:假设袋子里有N个白球,M个黑球,伸手摸一把,摸出黑球的概率是多大。
2、逆向概率:如果事先不知道袋子里黑白球的比例,而是闭着眼摸出一个或好几个球,观察这些取出来的球的颜色之后,那么我们可以就此对袋子里的黑白球的比例作出什么样的推测。
为什么用贝叶斯?
就拿黑白球来说,因为自然界中可能白球和黑球的比例太多了,我们根本无法知道有多少个白球和黑球,所以具体比例如果用正向思维就很难推测,但如果我们用逆向思维去,就可以推测一下自然界中黑白球的比例是多少。
贝叶斯公式推导:
问题描述:

男→60%→长裤
女→40%→长裤、裙子
正向:来一个学生,长裤的概率。
逆向:一个学生长裤,它是女生概率。
逆向问题解决:




分母就是穿长裤概率,分子意义(来一个人,这个人是女生且穿长裤的概率)
所以推导出贝叶斯算法概率:
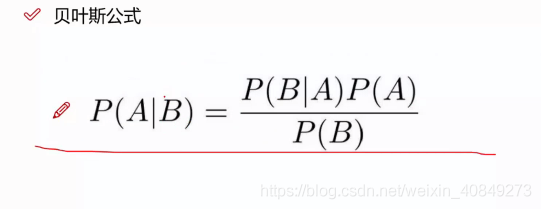
贝叶斯拼写纠错实例(这是个预测问题)
比如说,有个人写了个单词tha,这是我们看到的单词,我们就去猜猜这个人其实想表达的单词为the,than还是其他呢。

我们把问题套用贝叶斯公式:

当用户输入了一个不在字典中的单词,我们需要去猜测:“这个家伙到底真正想输入的单词是什么呢?”用形式化的语言来叙述,就是我们需要求得:
P(我们猜测他想输入的单词 | 他实际输入的单词),这个概率越大越好。
比如用户输入thew,那么猜测他到底想输入the,还是thaw,还是其他的单词?到底哪一个单词的可能性比较大?这时候我们就可以用贝叶斯去求出每个词语的可能性。
不妨把我们的猜测记为h1、h2、...hn,他们都属于一个有限且离散的猜测空间H(单词总共就只有那么多,H代表hypothesis),将用户实际输入的单词记为D(D代表data,即观测数据),于是问题转为:
P(我们的猜测1 | 他实际输入的单词)可以表示为P(h1|D),依次对于猜测2,则表示为P(h2|D)...我们需要计算这些概率值,取最大的。
把所有的猜测先统一记为P(H|D),运用一次贝叶斯公式,我们得到:P(H|D) = P(H) * P(D|H) / P(D)
因为不论对哪一个具体猜测h1、h2、...hn,其中的P(D)都是一样的,所以我们可以把这个东西看出一个常数c,所以在计算或比较P(h1 | D) 和 P(h2 | D) 的时候我们可以忽略P(D)这个常数。把公式简化为:
P(H | D) ∝ P(H) * P(D | H),其中∝代表正比例于。
这个式子的抽象含义是:对于给定观测数据,猜测是好是坏,取决于“这个猜测本身独立的可能性大小(先验概率,Prior )”和“这个猜测生成我们观测到的数据的可能性大小”(似然,Likelihood )的乘积,其中P(H)表示字典中出现H的概率,比如字典中有1000个单词,H有200个,那么P(H) = 1/5。
具体到上面的 thew 例子上,就是用户实际是想输入 the 的可能性大小取决于 the 本身在词汇表中被使用的可能性(频繁程度)大小(先验概率)和 想打 the 却打成 thew 的可能性大小(似然)的乘积。
解决问题的方法变为,对于各种猜测,计算下P(H) * P(D | H) 这个值,然后取值为最大的那个猜测即可。
这个问题中P(H)是先验概率,P(D | H)是似然概率。
垃圾邮件过滤实例
先比较两个模型:


最大似然估计是根据观测的数据找出哪些是最有优势的,比如投一个硬币就投一次,观测到的为正,那么根据最大似然估计可以预测下一次投正的概率为1,这只是投一次的情况,如果投很多次,那也能预测出投正的概率大概为0.5,简单来说,最大似然估计原理就是根据投掷结果来预测以后。
奥卡姆剃刀模型认为先验概率较大模型的具有较大的优势,追寻的是实际中什么东西最常见什么东西就是越好的。
垃圾邮件:

先验概率p(h+)和p(h-)是可求的,比如说统计出每一万封邮件中有9000个正常邮件和1000个垃圾邮件,那么p(h+)和p(h-)分别为0.1和0.9。

对以上图片解释:为什么可以扩展,因为在垃圾邮件中有一封于邮件D出现的词一模一样的概率非常小,所以我们做一个扩展,在垃圾邮件中有一封邮件出现单词d1的概率乘以在垃圾邮件中并且包含单词d1的邮件中有一封邮件出现d2的概率乘以。。。

以上图片解释:我们把贝叶斯转换为朴素贝叶斯,朴素贝叶斯的前提是各个特征相互独立,这里就是di和dm无关。所以扩展后的公式就变成了![]()
可能会产生疑问:为什么可以假设成朴素贝叶斯,让其各个特征独立呢?
因为不做假设几乎无法去求解,我们如果做的假设如果对结果影响不大,就可以这样假设,这样假设后对于求解很方便,也就是说,这样的假设对于结果确实会有影响,但是影响不大,我们舍弃这些很小的影响,用方便求解替代。
贝叶斯算法实现拼写检查器
核心过程:

#本代码实现了输入者输入错误时,纠正输入的错误,把输入值想输的单词输出
#p(c)和p(w\c)分别用语料库词频和插删换改来代替,最后综合考虑两个因素
import re, collections
#re是正则表达式模块,re.findall遍历匹配,可以获取字符串中所有匹配的字符串,返回一个列表。
def words(text): return re.findall('[a-z]+', text.lower())#读取语料库,去除除字母类其他字符并转化为小写,text.lower()的意思是把大写转化为小写字母,+的意思表至少匹配一次,也就是返回的有很多小写字母的字符串
def train(features):
# print(words(open('./big.txt').read()))
model = collections.defaultdict(lambda: 1)#用来计算单词出现频率,初始值为1,因为如果是0的话,会使得先验概率为0
for f in features:
model[f] += 1
# print(model)
return model
NWORDS = train(words(open('./big.txt').read()))#读取语料库并train,得到词库中各个单词出现的频率
alphabet = 'abcdefghijklmnopqrstuvwxyz'#用于edits中字符的换和插
def edits1(word):#word是我们输入的单词,函数返回的是所有编辑距离为1的单词,编辑距离指两个单词经过一次修改(插删换改)就能相互替换
n = len(word)
for i in range(n):
print(i)
print(set(word[0:i] for i in range(n)))#输出的分别为(,a,ap,app),而且顺序是打乱的,set函数用来函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。
print(set(word[i + 1:] for i in range(n)))#输出的分别为(ppl,pl,l,),而且顺序是打乱的
# print(set([word[0:i] + word[i + 1:] for i in range(n)]))
# print(set( [word[0:i] + word[i + 1] + word[i] + word[i + 2:] for i in range(n - 1)]))
# print(set([word[0:i] + c + word[i + 1:] for i in range(n) for c in alphabet]))
# print(set( [word[0:i] + c + word[i:] for i in range(n + 1) for c in alphabet]))
return set([word[0:i] + word[i + 1:] for i in range(n)] + # deletion(删)
[word[0:i] + word[i + 1] + word[i] + word[i + 2:] for i in range(n - 1)] + # transposition(换)
[word[0:i] + c + word[i + 1:] for i in range(n) for c in alphabet] + # alteration(改)
[word[0:i] + c + word[i:] for i in range(n + 1) for c in alphabet]) # insertion(插)
def known_edits2(word):#返回编辑距离为2的单词集合,并且这些单词是在语料库中已经有的
return set(e2 for e1 in edits1(word) for e2 in edits1(e1) if e2 in NWORDS)
def known(words):
# print(set(w for w in words if w in NWORDS))#先构造了一个变量w,然后把words中的单词一个个给w,判断一下是否在语料库中,是的话输出
return set(w for w in words if w in NWORDS)
def correct(word):
candidates = known([word]) or known(edits1(word)) or known_edits2(word) or [word]#如果known(set)非空, candidate 就会选取这个集合, 而不继续计算后面的,这条代码实现了P(w\c)的过程,优先级从编辑距离为0开始到1到2到本身,
#我们已知p(w\c)的含义为想打一个单词却打成另外一个单词的概率,这个概率越小越好,而这条代码的编辑距离的优先级实现了越小越好的这个过程
print(candidates)
return max(candidates, key=lambda w: NWORDS[w])#返回candidates中在语料库中词频较大的词,也就是p(c)较大的词,由贝叶斯公式可知,需要找的是先验概率和似然概率之积最大的词,这条代码综合考虑了先验概率和似然概率。
#print(edits1('appl'))
#print(known_edits2('appl'))
#print(known('appl'))
print(correct('appl'))#会输出apply
#print(correct('knoow'))#会输出know
big.txt是语料库,相当于字典一样。 p(w|c)用编辑距离来替代。
p(c)用NWORDS[W]库中词频代替,w越大说明词频越高,先验概率越大。 big语料库:链接:https://pan.baidu.com/s/1tSGb4Nw86OHpatqYEDXbWg
提取码:2q77
文本分析与关键词提取
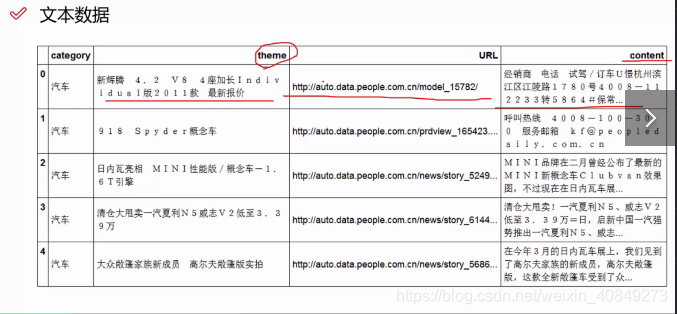
以上示例图片是我们要分析的文本,是拿到数据过后pandas读取进来然后.head()的结果,content是新闻内容,还有主题和连接,文本数据里面包含很多有用的和没用的我们需要把有用的提取出来,我们后续要做的是做一个新闻分类的任务。
停用词:表示文本中大量出现但对文本主题思想内容没有影响的词,会对文本分析起干扰作用,我们把这些词去掉,停用词会有停用词表,网上有很多,我们把文本拿过来,停用词表拿过来,就能进行筛选,把文本中的停用词去掉。

tf-idf:用来做关键词提取,计算文件中词汇的重要程度。

首先介绍一下如何计算tf-idf,并且需要明确的是tf-idf=tf*idf,也就是说tf与idf分别是两个不同的东西。其中tf为谋个训练文本中,某个词的出现次数,即词频(Term Frequency);idf为逆文档频率(Inverse Document Frequency),对于词频的权重调整系数。
其中:

对于逆文档频率,如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数(此处为自然对数)。
假定某训练文本长度为1000个词,”中国”、”蜜蜂”、”养殖”各出现20次,则这三个词的”词频”(TF)都为0.02。然后,搜索Google发现,包含”的”字的网页共有250亿张,假定这就是中文网页总数(即总样本数)。包含”中国”的网页共有62.3亿张,包含”蜜蜂”的网页为0.484亿张,包含”养殖”的网页为0.973亿张。则它们的逆文档频率(IDF)和TF-IDF如下:
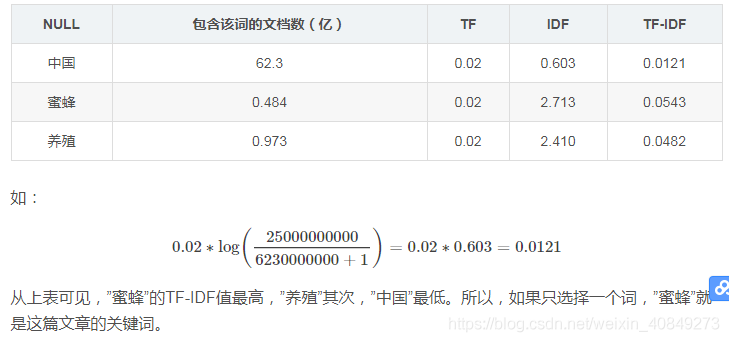
从tf-idf中也可以看出为什么要先把停用词去掉,因为停用词会干扰tf-idf的计算。
相似度计算
关于文档的相似度怎么衡量呢?
比如我们想知道北京关于下雪之类的新闻,一搜索发现出现一堆文章,这些文章都和当前文章比较相似,那么怎么衡量其相似度呢?
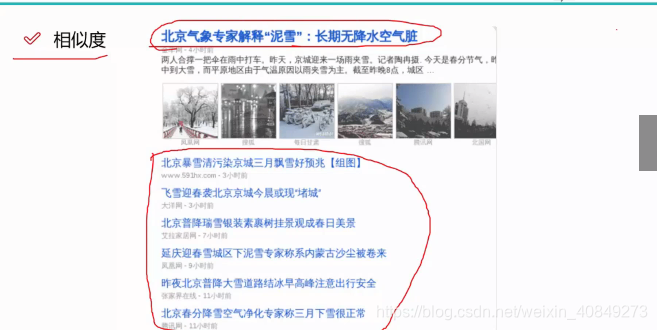

分词可以用jieba分词器。
计算向量我们可以用余弦相似度来计算。
文本分析大致流程:
1、把语料拿过来,进行语料清洗,包括许多流程,包括去掉停用词,筛选掉一些经常重复的话(比如爬贴吧中数据,有许多类似楼主好人之类的话,这些需要清洗掉)。
2、分词,构造向量(可以基于词频来构造向量或者wordlvec来构造等)
3、然后用余弦相似度计算相似度。

文本分析实战演示:














 687
687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









