







Pig简介
Apache Pig是一个高级过程语言,适合使用Hadoop和Mapreduce平台来查询大型半结构化数据,当Pig处理数据时,Pig本身
会在后台生成一系列得MapReduce操作来执行任务,这个过程对用户来说是透明的。
用于执行Pig Latin程序的执行环境,当前有两个环境:单JVM中的本地执行环境和Hadoop集群上的分布式执行环境。
Pig内部,每个操作或变换是对输入进行数据处理,然后产生输出结果,这些变换操作被转换成一系列MapReduce作业,
Pig让程序员不需要知道这些转换具体是如何进行的,这样工程师可以将精力集中在数据上,而非执行的细节上。
相比Java的MapReduce API,Pig为大型数据集的处理提供了更高层次的抽象,与MapReduce相比,Pig提供了更丰富的数据结构,一般都是多值和嵌套的数据结构。Pig还提供了一套更强大的数据变换操作,包括在MapReduce中被忽视的连接Join操作。
Pig与Hive的区别
对于开发人员,直接使用Java APIs可能是乏味或容易出错的,同时也限制了Java程序员在Hadoop上编程的运用灵活性。于是Hadoop提供了两个解决方案,使得Hadoop编程变得更加容易。
•Pig是一种编程语言,它简化了Hadoop常见的工作任务。Pig可加载数据、表达转换数据以及存储最终结果。Pig内置的操作使得半结构化数据变得有意义(如日志文件)。同时Pig可扩展使用Java中添加的自定义数据类型并支持数据转换。
•Hive在Hadoop中扮演数据仓库的角色。Hive添加数据的结构在HDFS,并允许使用类似于SQL语法进行数据查询。与Pig一样,Hive的核心功能是可扩展的。
Pig和Hive总是令人困惑的。Hive更适合于数据仓库的任务,Hive主要用于静态的结构以及需要经常分析的工作。Hive与SQL相似促使 其成为Hadoop与其他BI工具结合的理想交集。Pig赋予开发人员在大数据集领域更多的灵活性,并允许开发简洁的脚本用于转换数据流以便嵌入到较大的应用程序。Pig相比Hive相对轻量,它主要的优势是相比于直接使用Hadoop Java APIs可大幅削减代码量。正因为如此,Pig仍然是吸引大量的软件开发人员。
一些基本操作:
1.从文件导入数据
1)Mysql (Mysql需要先创建表).
CREATE TABLE TMP_TABLE(USER VARCHAR(32),AGE INT,IS_MALE BOOLEAN);
CREATE TABLE TMP_TABLE_2(AGE INT,OPTIONS VARCHAR(50)); -- 用于Join
LOAD DATA LOCAL INFILE '/tmp/data_file_1' INTO TABLE TMP_TABLE ;
LOAD DATA LOCAL INFILE '/tmp/data_file_2' INTO TABLE TMP_TABLE_2;2)Pig
tmp_table = LOAD '/tmp/data_file_1' USING PigStorage('\t') AS (user:chararray, age:int,is_male:int);
tmp_table_2= LOAD '/tmp/data_file_2' USING PigStorage('\t') AS (age:int,options:chararray); 2.查询整张表
1)Mysql
SELECT * FROM TMP_TABLE;2)Pig
DUMP tmp_table; 3. 查询前50行
1)Mysql
SELECT * FROM TMP_TABLE LIMIT 50;
2)Pig
tmp_table_limit = LIMIT tmp_table 50;
DUMP tmp_table_limit;
4.查询某些列
1)Mysql
SELECT USER FROM TMP_TABLE;
2)Pig
tmp_table_user = FOREACH tmp_table GENERATE user;
DUMP tmp_table_user;
5. 给列取别名
1)Mysql
SELECT USER AS USER_NAME,AGE AS USER_AGE FROM TMP_TABLE;
2)Pig
tmp_table_column_alias = FOREACH tmp_table GENERATE user AS user_name,age AS user_age;
DUMP tmp_table_column_alias;
6.排序
1)Mysql
SELECT * FROM TMP_TABLE ORDER BY AGE;
2)Pig
tmp_table_order = ORDER tmp_table BY age ASC;
DUMP tmp_table_order;
7.条件查询
1)Mysql
SELECT * FROM TMP_TABLE WHERE AGE>20;
2) Pig
tmp_table_where = FILTER tmp_table by age > 20;
DUMP tmp_table_where;
8.内连接Inner Join
1)Mysql
SELECT * FROM TMP_TABLE A JOIN TMP_TABLE_2 B ON A.AGE=B.AGE;
2)Pig
tmp_table_inner_join = JOIN tmp_table BY age,tmp_table_2 BY age;
DUMP tmp_table_inner_join;
9.左连接Left Join
1)Mysql
SELECT * FROM TMP_TABLE A LEFT JOIN TMP_TABLE_2 B ON A.AGE=B.AGE;
2)Pig
tmp_table_left_join = JOIN tmp_table BY age LEFT OUTER,tmp_table_2 BY age;
DUMP tmp_table_left_join;
10.右连接Right Join
1)Mysql
SELECT * FROM TMP_TABLE A RIGHT JOIN TMP_TABLE_2 B ON A.AGE=B.AGE;
2)Pig
tmp_table_right_join = JOIN tmp_table BY age RIGHT OUTER,tmp_table_2 BY age;
DUMP tmp_table_right_join;
11.全连接Full Join
1)Mysql
SELECT * FROM TMP_TABLE A JOIN TMP_TABLE_2 B ON A.AGE=B.AGE
UNION SELECT * FROM TMP_TABLE A LEFT JOIN TMP_TABLE_2 B ON A.AGE=B.AGE
UNION SELECT * FROM TMP_TABLE A RIGHT JOIN TMP_TABLE_2 B ON A.AGE=B.AGE;
2)Pig
tmp_table_full_join = JOIN tmp_table BY age FULL OUTER,tmp_table_2 BY age;
DUMP tmp_table_full_join;
12.同时对多张表交叉查询
1)Mysql
SELECT * FROM TMP_TABLE,TMP_TABLE_2;
2)Pig
tmp_table_cross = CROSS tmp_table,tmp_table_2;
DUMP tmp_table_cross;
13.分组GROUP BY
1)Mysql
SELECT * FROM TMP_TABLE GROUP BY IS_MALE;
2)Pig
tmp_table_group = GROUP tmp_table BY is_male;
DUMP tmp_table_group;
14.分组并统计
1)Mysql
SELECT IS_MALE,COUNT(*) FROM TMP_TABLE GROUP BY IS_MALE;
2)Pig
tmp_table_group_count = GROUP tmp_table BY is_male;
tmp_table_group_count = FOREACH tmp_table_group_count GENERATE group,COUNT($1);
DUMP tmp_table_group_count;
15.查询去重DISTINCT
1)MYSQL
SELECT DISTINCT IS_MALE FROM TMP_TABLE;
2)Pig
tmp_table_distinct = FOREACH tmp_table GENERATE is_male;
tmp_table_distinct = DISTINCT tmp_table_distinct;
DUMP tmp_table_distinct;
pig支持数据类型
double > float > long > int > bytearray
tuple|bag|map|chararray > bytearray
double float long int chararray bytearray都相当于pig的基本类型
tuple相当于数组 ,但是可以类型不一,举例('dirkzhang','dallas',41)
Bag相当于tuple的一个集合,举例{('dirk',41),('kedde',2),('terre',31)},在group的时候会生成bag
Map相当于哈希表,key为chararray,value为任意类型,例如['name'#dirk,'age'#36,'num'#41
nulls 表示的不只是数据不存在,他更表示数据是unkown
注意进入到pig环境后,只能向后删除不能向前删除。直接输入dump ;会输出最近的变量。
在目录下创建文件按:
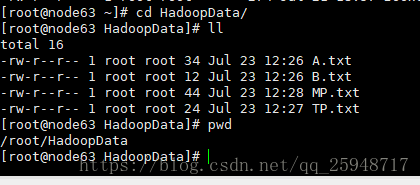
内容如下:
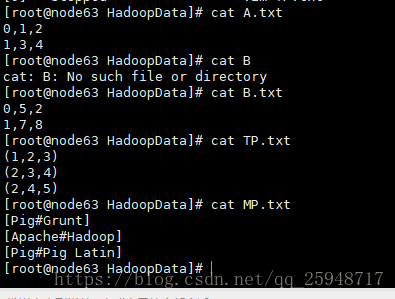
输入pig,进入到Pig,创建pig目录,上传到HDFS

上传成功:
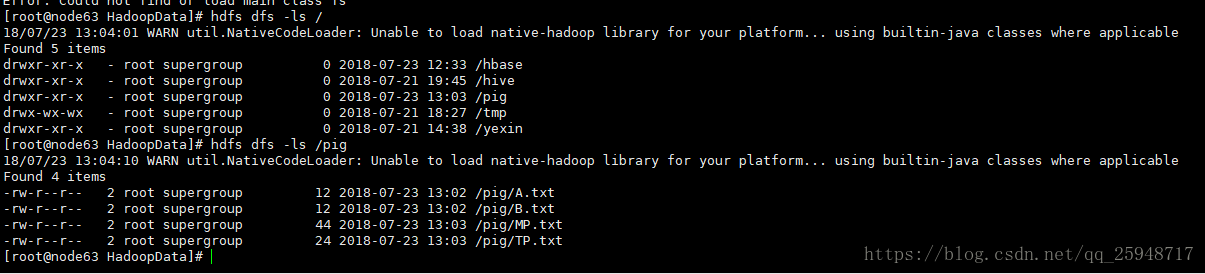
从文件导入数据(注意文件在hdfs上):装载A.txt到变量a,b为a的列$0+列$1
a = load '/pig/A.txt' using PigStorage(',') as (c1:int,c2:double,c3:float);
注意:= 前后一定要有空格!!!!!

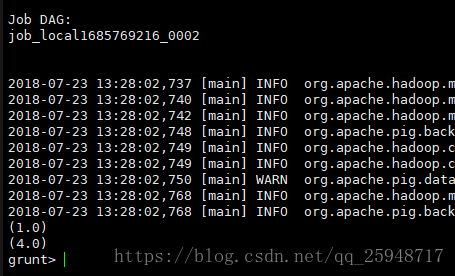
grunt> b = foreach a generate $0+$1 as b2;
grunt> dump b;

变量c为b的b2列减1:
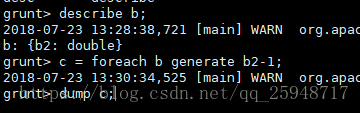
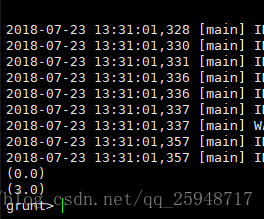
变量d为a的第一列,如果是0则输出(c1,c2),如果不是0则输出(c1,c3):

变量f为a的c1>0并且c2>1的输出:
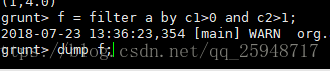
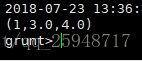
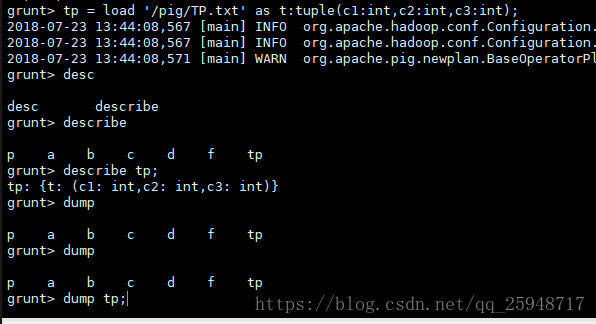
装载Tuple数据TP.txt到tp变量,变量g为tp产生的输出:
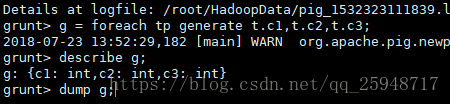
有时可能会产生dump g;输出错误,查看原因时因为10020端口没有开启:
发现这个10020号端口是mapreduce.jobhistory.address。查看hadoop配置文件mapred-site.xml中已经有了这个定义:
<property>
<name>mapreduce.jobhistory.address</name>
<value>master.hadoop:10020</value>
</property> 运行:
mr-jobhistory-daemon.sh start historyserver重新启动再运行一遍就可以了,
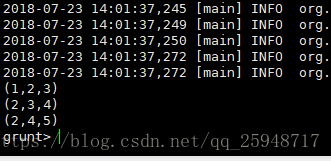
对g进行分组,输出Bag数据到bg:
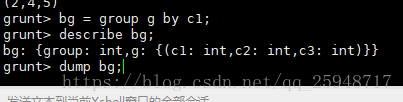
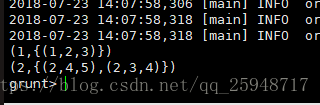
输入:illustrate bg;
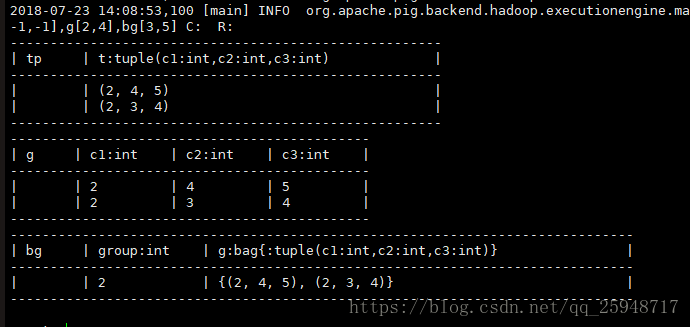
x = foreach bg generate g.c1;
dump x;
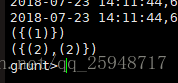
装载Map数据MP.txt到变量mp,h为mp产生的输出:
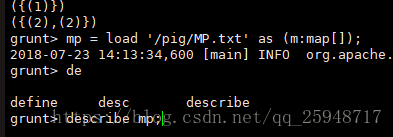
dump mp;
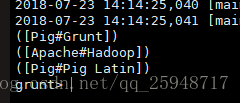
dump h;
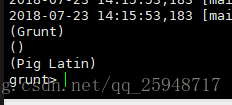
数据集运算:
先加载:a = load '/pig/A.txt' using PigStorage(',') as (a1:int,a2:int,a3:int);
b = load '/pig/B.txt' using PigStorage(',') as (b1:int,b2:int,b3:int);
并集:c = union a,b;
dump c;
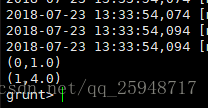
(0,1,2)
(1,3,4)
(0,5,2)
(1,7,8)
将c分割为d和e,其中d的第一列数据为0,e的第一列数据为1,($0表示数据集的第一列):
split c into d if $0 == 0,e if $0 == 1;
dump d;
(0,1,2)
(0,5,2)
dump e;
(1,3,4)
(1,7,8)
选取c中的一部分数据:
f = filter c by $1 > 3;
dump f;
(0,5,2)
(1,7,8)
对数据按列分组:
g = group c by $2;
dump g;
(2,{(0,1,2),(0,5,2)})
(4,{(1,3,4)})
(8,{(1,7,8)})
将所有的元素集合到一起:
h = group c all;
dump h;
(all,{(1,3,4),(0,1,2),(1,7,8),(0,5,2)})
查看h中元素的个数:
i = foreach h generate COUNT ($1);
dump i;
连表查询,条件:a.$2 == b.$2
j = join a by $2,b by $2;
dump j;
(0,1,2,0,5,2)
k为c的$1 和$1*$2的输出:
k = foreach c generate $1,$1 * $2;
dump k;
(1,2)
(3,12)
(5,10)
(7,56)















 113
113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









