









首先这两个方法都是Object超类中的两个方法,类 Object 是类层次结构的根类,每个类都使用 Object 作为超类,所有对象(包括数组)都实现这个类的方法。以下是这两个类在Object中内部代码实现源码:


可以明显看到equals方法比较的是内存地址,hashcode方法是一个native方法,native方法的具体实现是用C语言实现的,因为jdk就是用C语言编写的。当有一些需要和硬件打交道的方法,java是做不了的,于是它就偷懒声明一个native方法让c去写一个方法去和硬件打交道,c写好之后java直接调用即可。java是跨平台的语言,跨平台所付出的代价就是失去一些对底层的控制,Java平台有个用户和本地C代码进行互操作的API,称为Java Native Interface (Java本地接口),hashcode()方法就是进行寻址。
然而在实际开发中,很多时候都要进行equals方法重写,目的是因为当你比较两个对象的时候,原本就是new了两个对象,如果是需要比较内存地址“==”号就足够了,没必要还要调用equals绕一下进行比较,所以equals存在的意义是在于重写,重写的目的是什么呢?主要在两个方面:
1.面对容器的时候,例如set,如果存的是不重复的对象,又因为其内部代码是先判断对象hashcode,再判断equals方法,所以这些对象必须重写这两个方法,这里我先用代码征服各位读者,如下:我用hashset存入两个对象,一个对象重写这两个方法,一个对象不重写,new两个属性一样的对象,结果重写了的hashset生效只能存一个,没有重写的两个都存了。首先看没有重写的:


再来看重写了的:
package blog;
public class DuiXiang2 {
public int age;
public String name;
public DuiXiang2(int age, String name) {
super();
this.age = age;
this.name = name;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
DuiXiang2 other = (DuiXiang2) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public String toString() {
return "DuiXiang2 [age=" + age + ", name=" + name + "]";
}
}
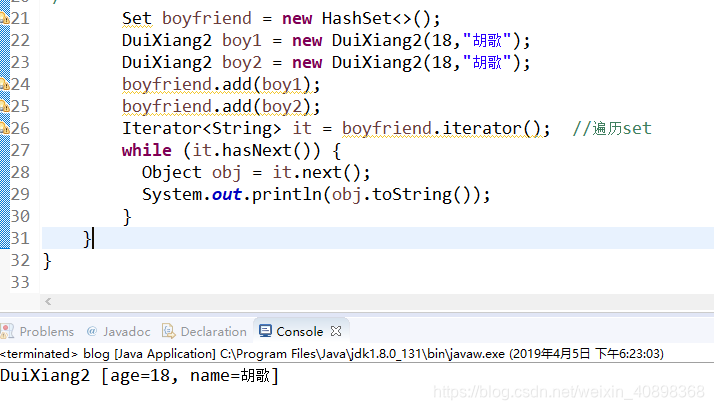
说明没有重写对象这两个方法,hashset失效,显然如果要用到容器存对象这种情况明显不允许,所以一定要重写,具体原因下面剖析hashset内部代码时候再说。
2.面对包装类型的时候,我们都知道像Integer,String,Double这样的包装类型,java是自动帮我们进行了equals方法重写的,因为对这种类型来说我们比较内存地址很少,一般都是对值进行比对,如下的Double类型重写源码(网上很多举例String类型的,咱们举个看得少的)
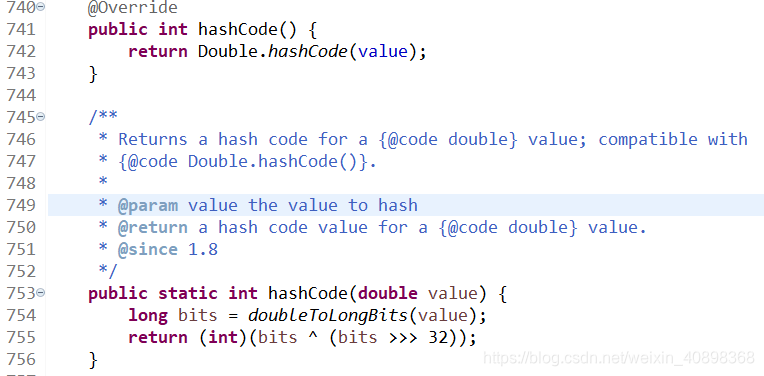

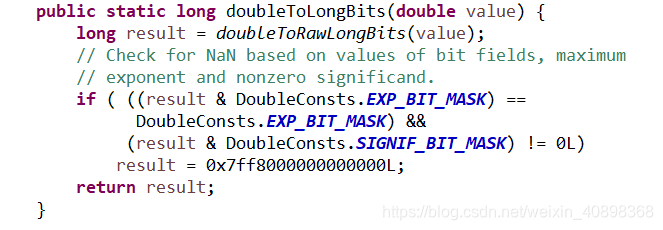
仔细看这个例子和上面对象2那个重写了的类的的equals和hashcode方法,可以明显的看到,equals方法重写时比较值(基本类型值,对象属性值),hashcode方法重写之后不是仅仅跟操作系统有关,还跟Double类的value值,跟对象类2的属性值相关,结合这个可以理解这两句经典结论(既然是结论,那么重写和未重写都应该满足):
- 如果两个对象通过调用 equals 方法是相等的,那么这两个对象调用 hashCode 一定相等;(未重写比较的是对象地址一样,则hashcode肯定一样,重写了之后比较的是属性值一样,那么hashcode值也一样)
- 如果两个对象通过调用 equals 方法是不相等的,这两个对象调用 hashCode 方法可能相同也可能不同。(未重写比较对象地址不一样然而因为存在hash冲突,hashcode值可能一样也可能不一样,重写了之后因为和属性值组合值有关,注意组合值就会出现equals不一样但是组合值一样,所以hashcode值也是可能一样可能不一样,没有违背!有点绕,读者可以细细品味一下,道理跟hashcode值是10,分别由2+8和3+7得到的一样)这两句话是hashmap基础
分水岭,以上我从两个点进行出发解释了重写的目的,接下来谈谈equals和hashcode经常成双入对的原因了(论我和胡歌必须在一起的重要性),为什么重写了equals还要重写hashcode 呢?
既然是敲代码,还是先用代码征服各位读者,还是刚刚那个例子,我把对象2那个类的hashcode方法注释掉,equals方法保留,再跑一遍结果如下:
package blog;
public class DuiXiang2 {
public int age;
public String name;
public DuiXiang2(int age, String name) {
super();
this.age = age;
this.name = name;
}
/*@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}*/
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
DuiXiang2 other = (DuiXiang2) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public String toString() {
return "DuiXiang2 [age=" + age + ", name=" + name + "]";
}
}
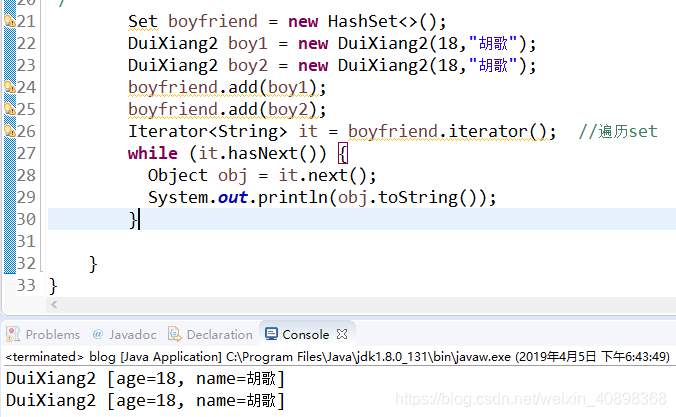
可以看到,没有了hashcode方法,set容器还是放进了两个相同对象,佛说:不可以!
理论上解释:这里我想先声明一下,hashset底层是hashmap,只不过是存储在hashmap的key里面,value是个伪值,利用的是hashmap的key值不能重复这一点,因此这里我只分析hashmap的代码,读者想知道更清楚可以扒开hashset底层代码看。如下是源码中hashset方法,利用的是hashmap
我们先来看hashmap的数据结构和hashmap源码中put的逻辑源码(此处注明一下这里我用的是jdk1.7其数据结构是数组链表,1.8变成了数组链表红黑树,前者更加容易懂)
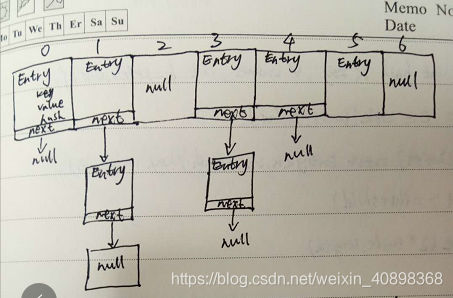
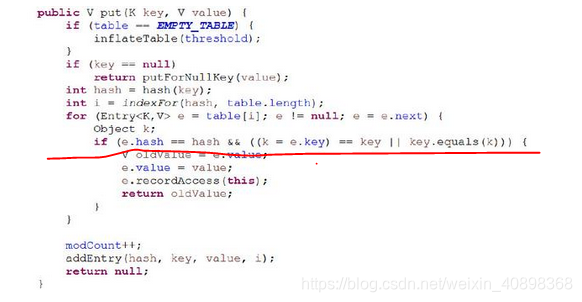
这里由于我用的是jdk1.8,为了轻松点不贴1.7put方法里调用的其他方法了,从源码中可以看到hashmap允许key为null,当key为null时固定方法putForNullKey()处理,然后hash()方法对key的hashcode值进行再一次计算确保散列均匀,indexFor()方法寻找对象在数组中的位置,找到那个位置之后如果有冲突元素遍历链表,遍历链表是为了判断对象是否已经存在,如果存在进行覆盖操作即用新的value替换旧的value并返回value,从而达到键唯一的目的,如果链表不存在则跳过for循环往下进行addEntry()进行添加。
之所以先判断hash方法是为了提高效率,试想一下如果对象属性特别多,链表又比较长,如果先判断equals方法要一个一个比对,但是先判断hash方法可以过滤掉那些hash值不一样的,肯定就不是同一个对象(这点毫无疑问),这是判断顺序的原因。
不知道有没有读者想过为什么都问“为什么重写equals方法还要重写hashcode方法?”,而不反过来问,反正我想过这个问题,个人理解是因为重写equals方法更有意义,此文最初说的那两点,hashcode方法往往是伴随着equlas方法,控制同一个对象,如果只是单独重写hashcode方法可以干啥呢?离开了equals方法重写hashcode没有应用场景,即单独重写hashcode无意义。
那么问题来了,hashcode方法和equals方法是为了判断对象是否已经存在,在循环链表里面,就需要精准定位到需要寻找的对象,为什么要同时出现,为什么重写了equlas还要重写hashcode呢?还记得上面看到的胡歌的例子吗?从这个hashmap底层代码来推,如果只重写了equals方法,首先判断hash值,由于hash值是根据hashcode来计算的,没有重写hashcode则是调用Object的内存地址,可以知道hash值肯定不一样,if判断不需要往后走,最终往下走addEntry,所以这种情况下来多少对象加多少对象,根本不管equals是否相同。有人会问这样会出现什么情况呢?你存进去肯定需要拿出来,再看get取值方法
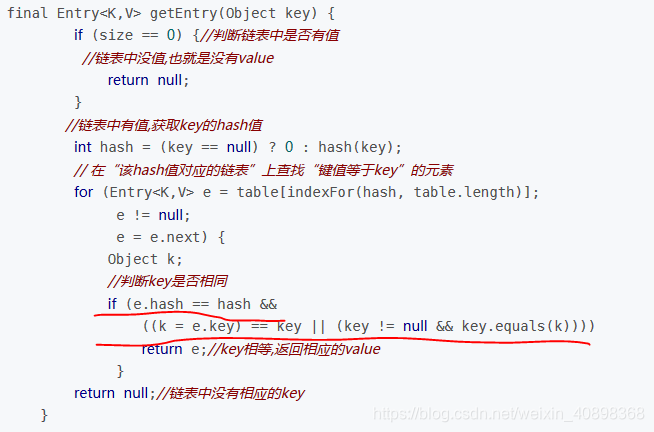
先举一个例子,DuiXiang2注释掉hashcode方法的情况下,还是代码征服
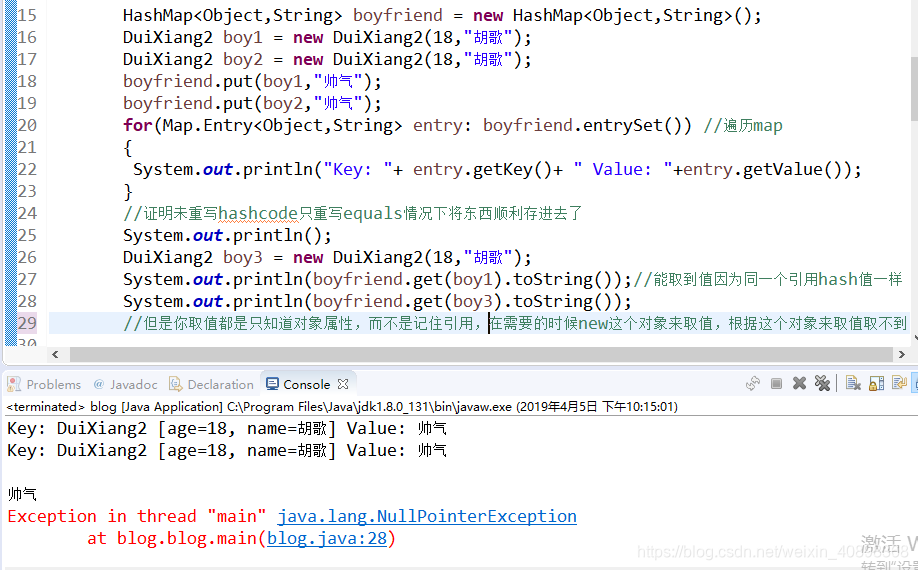
可以看到你能存入相同对象,但是当你取值的时候永远取不到!理论解释:看刚刚的get源码,你new一个对象,根据这个取值,没有重写hashcode方法的话hash值永远不一样,根本就不需要比equals方法,hash值不一样return的永远是null!
我再把DuiXiang2的equals方法和hashcode方法全部重写,结果如下
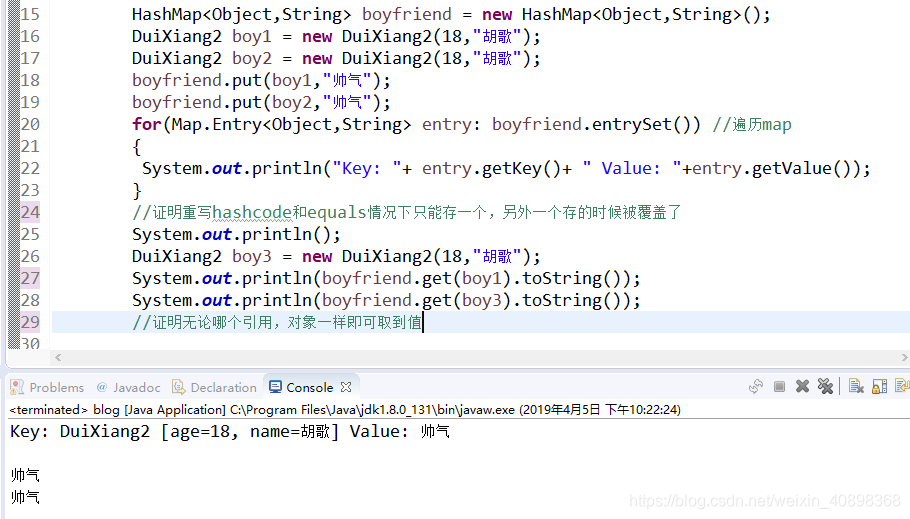
因此,我和胡歌必须在一起!!!到这里相信大家应该会有点收获,水平有限,如果有错欢迎指正!














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









