






作者:海晨威
地址:https://zhuanlan.zhihu.com/p/132554155
文章经过作者同意转载
随着NLP的不断发展,对BERT/Transformer相关知识的研(mian)究(shi)应(ti)用(wen),也越来越细节,下面尝试用QA的形式深入不浅出BERT/Transformer的细节知识点。
1、不考虑多头的原因,self-attention中词向量不乘QKV参数矩阵,会有什么问题?
2、为什么BERT选择mask掉15%这个比例的词,可以是其他的比例吗?
3、使用BERT预训练模型为什么最多只能输入512个词,最多只能两个句子合成?
4、为什么BERT在第一句前会加一个[CLS]标志?
5、Self-Attention 的时间复杂度是怎么计算的?
6、Transformer在哪里做了权重共享,为什么可以做权重共享?
7、BERT非线性的来源在哪里?
8、BERT的三个Embedding直接相加会对语义有影响吗?
9、Transformer的点积模型做缩放的原因是什么?
10、在BERT应用中,如何解决长文本问题?
1、不考虑多头的原因,self-attention中词向量不乘QKV参数矩阵,会有什么问题?
Self-Attention的核心是用文本中的其它词来增强目标词的语义表示,从而更好的利用上下文的信息。
self-attention中,sequence中的每个词都会和sequence中的每个词做点积去计算相似度,也包括这个词本身。
对于 self-attention,一般会说它的 q=k=v,这里的相等实际上是指它们来自同一个基础向量,而在实际计算时,它们是不一样的,因为这三者都是乘了QKV参数矩阵的。那如果不乘,每个词对应的q,k,v就是完全一样的。
在相同量级的情况下,qi与ki点积的值会是最大的(可以从“两数和相同的情况下,两数相等对应的积最大”类比过来)。
那在softmax后的加权平均中,该词本身所占的比重将会是最大的,使得其他词的比重很少,无法有效利用上下文信息来增强当前词的语义表示。
而乘以QKV参数矩阵,会使得每个词的q,k,v都不一样,能很大程度上减轻上述的影响。
当然,QKV参数矩阵也使得多头,类似于CNN中的多核,去捕捉更丰富的特征/信息成为可能。
2、为什么BERT选择mask掉15%这个比例的词,可以是其他的比例吗?
BERT采用的Masked LM,会选取语料中所有词的15%进行随机mask,论文中表示是受到完形填空任务的启发,但其实与CBOW也有异曲同工之妙。
从CBOW的角度,这里 有一个比较好的解释是:在一个大小为
的窗口中随机选一个词,类似CBOW中滑动窗口的中心词,区别是这里的滑动窗口是非重叠的。
那从CBOW的滑动窗口角度,10%~20%都是还ok的比例。
上述非官方解释,是来自我的一位朋友提供的一个理解切入的角度,供参考。
3、使用BERT预训练模型为什么最多只能输入512个词,最多只能两个句子合成一句?
这是Google BERT预训练模型初始设置的原因,前者对应Position Embeddings,后者对应Segment Embeddings
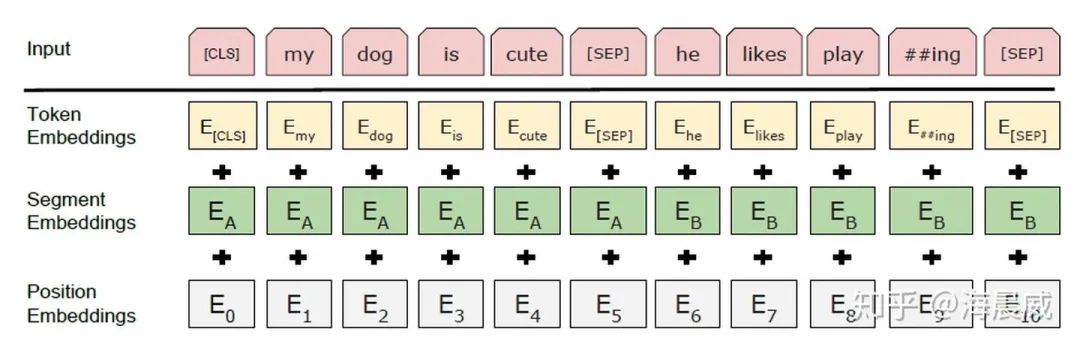
在BERT中,Token,Position,Segment Embeddings 都是通过学习来得到的,pytorch代码中它们是这样的
self.word_embeddings = Embedding(config.vocab_size, config.hidden_size)
self.position_embeddings = Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = Embedding(config.type_vocab_size, config.hidden_size)
上述BERT pytorch代码来自:github.com/xieyufei1993,结构层次非常清晰。
而在BERT config中
"max_position_embeddings": 512
"type_vocab_size": 2
因此,在直接使用Google 的BERT预训练模型时,输入最多512个词(还要除掉[CLS]和[SEP]),最多两个句子合成一句。这之外的词和句子会没有对应的embedding。
当然,如果有足够的硬件资源自己重新训练BERT,可以更改 BERT config,设置更大max_position_embeddings 和 type_vocab_size值去满足自己的需求。
4、为什么BERT在第一句前会加一个[CLS]标志?
BERT在第一句前会加一个[CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。
为什么选它呢,因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。
具体来说,self-attention是用文本中的其它词来增强目标词的语义表示,但是目标词本身的语义还是会占主要部分的,因此,经过BERT的12层,每次词的embedding融合了所有词的信息,可以去更好的表示自己的语义。
而[CLS]位本身没有语义,经过12层,得到的是attention后所有词的加权平均,相比其他正常词,可以更好的表征句子语义。
当然,也可以通过对最后一层所有词的embedding做pooling去表征句子语义。
这里补充一下bert的输出,有两种,在BERT TF源码中对应:
一种是get_pooled_out(),就是上述[CLS]的表示,输出shape是[batch size,hidden size]。
一种是get_sequence_out(),获取的是整个句子每一个token的向量表示,输出shape是[batch_size, seq_length, hidden_size],这里也包括[CLS],因此在做token级别的任务时要注意它。
5、Self-Attention 的时间复杂度是怎么计算的?
Self-Attention时间复杂度: ,这里,n是序列的长度,d是embedding的维度。
Self-Attention包括三个步骤:相似度计算,softmax和加权平均,它们分别的时间复杂度是:
相似度计算可以看作大小为(n,d)和(d,n)的两个矩阵相乘: ,得到一个(n,n)的矩阵
softmax就是直接计算了,时间复杂度为
加权平均可以看作大小为(n,n)和(n,d)的两个矩阵相乘: ,得到一个(n,d)的矩阵
因此,Self-Attention的时间复杂度是 。
这里再分析一下Multi-Head Attention,它的作用类似于CNN中的多核。
多头的实现不是循环的计算每个头,而是通过 transposes and reshapes,用矩阵乘法来完成的。
In practice, the multi-headed attention are done with transposes and reshapes rather than actual separate tensors. —— 来自 google BERT 源码
Transformer/BERT中把 d ,也就是hidden_size/embedding_size这个维度做了reshape拆分,可以去看Google的TF源码或者上面的pytorch源码:
hidden_size (d) = num_attention_heads (m) * attention_head_size (a),也即 d=m*a
并将 num_attention_heads 维度transpose到前面,使得Q和K的维度都是(m,n,a),这里不考虑batch维度。
这样点积可以看作大小为(m,n,a)和(m,a,n)的两个张量相乘,得到一个(m,n,n)的矩阵,其实就相当于(n,a)和(a,n)的两个矩阵相乘,做了m次,时间复杂度(感谢评论区指出)是 。
张量乘法时间复杂度分析参见:矩阵、张量乘法的时间复杂度分析
因此Multi-Head Attention时间复杂度也是 ,复杂度相较单头并没有变化,主要还是transposes and reshapes 的操作,相当于把一个大矩阵相乘变成了多个小矩阵的相乘。
6、Transformer在哪里做了权重共享,为什么可以做权重共享?
Transformer在两个地方进行了权重共享:
(1)Encoder和Decoder间的Embedding层权重共享;
(2)Decoder中Embedding层和FC层权重共享。
对于(1),《Attention is all you need》中Transformer被应用在机器翻译任务中,源语言和目标语言是不一样的,但它们可以共用一张大词表,对于两种语言中共同出现的词(比如:数字,标点等等)可以得到更好的表示,而且对于Encoder和Decoder,嵌入时都只有对应语言的embedding会被激活,因此是可以共用一张词表做权重共享的。
论文中,Transformer词表用了bpe来处理,所以最小的单元是subword。英语和德语同属日耳曼语族,有很多相同的subword,可以共享类似的语义。而像中英这样相差较大的语系,语义共享作用可能不会很大。
但是,共用词表会使得词表数量增大,增加softmax的计算时间,因此实际使用中是否共享可能要根据情况权衡。
该点参考:zhihu.com/question/3334
对于(2),Embedding层可以说是通过onehot去取到对应的embedding向量,FC层可以说是相反的,通过向量(定义为 x)去得到它可能是某个词的softmax概率,取概率最大(贪婪情况下)的作为预测值。
那哪一个会是概率最大的呢?在FC层的每一行量级相同的前提下,理论上和 x 相同的那一行对应的点积和softmax概率会是最大的(可类比本文问题1)。
因此,Embedding层和FC层权重共享,Embedding层中和向量 x 最接近的那一行对应的词,会获得更大的预测概率。实际上,Decoder中的Embedding层和FC层有点像互为逆过程。
通过这样的权重共享可以减少参数的数量,加快收敛。
但开始我有一个困惑是:Embedding层参数维度是:(v,d),FC层参数维度是:(d,v),可以直接共享嘛,还是要转置?其中v是词表大小,d是embedding维度。
查看 pytorch 源码发现真的可以直接共享:
fc = nn.Linear(d, v, bias=False) # Decoder FC层定义
weight = Parameter(torch.Tensor(out_features, in_features)) # Linear层权重定义
Linear 层的权重定义中,是按照 (out_features, in_features) 顺序来的,实际计算会先将 weight 转置在乘以输入矩阵。所以 FC层 对应的 Linear 权重维度也是 (v,d),可以直接共享。
7、BERT非线性的来源在哪里?
前馈层的gelu激活函数和self-attention,self-attention是非线性的,感谢评论区指出。
8、BERT的三个Embedding直接相加会对语义有影响吗?
这是一个非常有意思的问题,苏剑林老师也给出了回答,真的很妙啊:
Embedding的数学本质,就是以one hot为输入的单层全连接。
也就是说,世界上本没什么Embedding,有的只是one hot。
在这里想用一个例子再尝试解释一下:
假设 token Embedding 矩阵维度是 [4,768];position Embedding 矩阵维度是 [3,768];segment Embedding 矩阵维度是 [2,768]。
对于一个字,假设它的 token one-hot 是[1,0,0,0];它的 position one-hot 是[1,0,0];它的 segment one-hot 是[1,0]。
那这个字最后的 word Embedding,就是上面三种 Embedding 的加和。
如此得到的 word Embedding,和concat后的特征:[1,0,0,0,1,0,0,1,0],再过维度为 [4+3+2,768] = [9, 768] 的全连接层,得到的向量其实就是一样的。
再换一个角度理解:
直接将三个one-hot 特征 concat 起来得到的 [1,0,0,0,1,0,0,1,0] 不再是one-hot了,但可以把它映射到三个one-hot 组成的特征空间,空间维度是 4*3*2=24 ,那在新的特征空间,这个字的one-hot就是[1,0,0,0,0...] (23个0)。
此时,Embedding 矩阵维度就是 [24,768],最后得到的 word Embedding 依然是和上面的等效,但是三个小Embedding 矩阵的大小会远小于新特征空间对应的Embedding 矩阵大小。
当然,在相同初始化方法前提下,两种方式得到的 word Embedding 可能方差会有差别,但是,BERT还有Layer Norm,会把 Embedding 结果统一到相同的分布。
BERT的三个Embedding相加,本质可以看作一个特征的融合,强大如 BERT 应该可以学到融合后特征的语义信息的。
参考:zhihu.com/question/3748
下面两个问题也非常好,值得重点关注,但网上已经有很好的解答了,如下:
9、Transformer的点积模型做缩放的原因是什么?
参考:zhihu.com/question/3397
10、在BERT应用中,如何解决长文本问题?
参考:zhihu.com/question/3274
推荐阅读














 2527
2527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









