







这是我学习ReID系列看的第二篇paper,这是今天做的笔记。
首先翻译一下这篇文章的题目,在行人重检测中使用对抗重叠的目标作为样本,读起来可能比较拗口。简单点说就是模拟生成将普通训练的ReID模型中那些不能正常检测出来的特殊的数据(这就是Adversarially Occluded Samples,博客中称之为错误样本),将这些数据放入模型中进行训练,可以提高模型的accuracy。
再介绍一下行人检测的概念,通过今天的学习,我对于这个概念有了新的理解。行人重检测,就是从不同的相机场景中检测出特殊的人物这样一个任务。尽管行人检测的正确率目前来讲已经得到了较大的提高,人们在模型的训练过程中发现,训练与测试时候的表现总是存在较大的差距。针对于这个情况,文章中提出了一种数据增广的方法——引入错误样本来解决这样一个问题。
这个错误样本是在原始数据上,遮盖掉对实验结果影响比较大的那部分生成的。引入的错误样本具有着两个特殊点:1)有意义的,他们与真实样本中存在的一些例如由于建筑物,书包,图片模糊而导致的遮掩状况存在相似性。2)由于在最初的模型中,他们的训练是艰难的,因而通过将他们加入训练,能够发现更多的能够确认身份的细节,从而避免模型陷入局部最优。
文章中主要做了以下三点工作:1)分析了之前行人重检测模型中泛化能力不足的原因,并且提出了引入错误样本这样一个数据增广的办法。2)做了大量的实验,并且对模型内部进行了一些观察 3)文章中提供的方法,在 Market1501, CUHK03 and
DukeMTMC-reID三个数据集上都要很好的表现。
方法简介
文章中提出的整个模型框架主要分为了三个部分,首先,利用原始数据将一个ReID的模型训练到收敛。第二步中利用一些网络可视化的技术来寻找出哪些部分对于最后的结果有着比较重要的影响。并将原始数据中的这些部分遮掩掉生成错误样本。在第三步中,将原始数据与错误样本共同输入,作为数据来重新训练ReID的模型。整个模型的框架如下所示
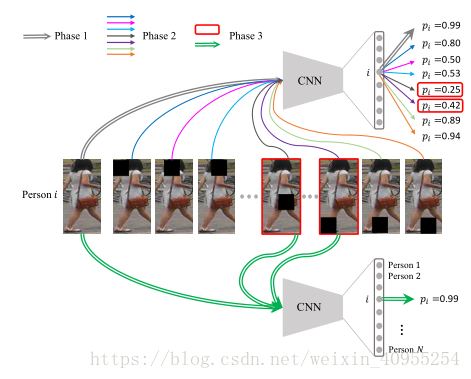
下面对这三个部分分别进行介绍:
1)基础ReID模型
文中采取了参考文献1里面的检测模型作为基础模型,在训练的过程中,它与物体识别采取相同的网络结构,并且将每个人作为单独的一个类别。在测试的过程中,将最后一个全连接层去除,并且将模型的剩余部分作为一个特征检测器。
假设我们由一个训练集 I包含了C个人,将它视为C种不同的类别,这个数据集中一共包含了N张图片,每个训练样本都是在这个数据集中生成 (I i ,c i ),i ∈ {1,2,...,N}。 c i是这个数据集中对应的真实标签,这个网络可以视为十一个从图片集到标签集的映射,可以拟成这样一个方程 z i = g(I i )。然后通过softmax方程,映射为一个概率分布:
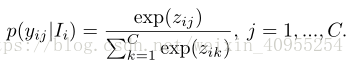
这个模型的损失函数是通过交叉熵函数,计算预测结果与真实值:
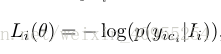
因此整个模型的损失函数可以总结为:
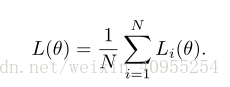
将损失函数值最小化等同于最大化真实值预测。文章中使用mini-batch随机梯度下降来优化函数。
2)寻找重点区域
寻找重点区域最直接的方法就是用一个滑动窗口依次遮盖输入图形的某一部分,并将这个作为结果输入到网络里面去。并且观察遮盖之后与遮盖之前分类结果的变化情况。实验中观察到,遮盖不同地方的窗口会导致分类准确性的不同的变化情况,当遮盖点为最重要的那个部分时,这个情况最为剧烈。其他地方引起的变化相对来说就比较小。

如上图所示,当将最重要的那一部分遮盖掉之后,我们在通过可视化显示出来的特征图中可以看出,第一行是原图,第二行是第一步的模型显示出来的,可以看到其中冷色部分起了比较大的影响,第三行是再次训练的模型,当遮盖掉第二行中的重要部分后,仍然能够正确识别出行人,但是在这过程中,我们从特征图中就看不到某几个区域,而是整张图中的一些细节对结果产生了最后的影响。
3)再次训练模型
在第三步中,对于初始样本以及之后生成的错误样本进行再训练。错误样本对于第一步中的模型是很严重的错误,所以在第三步中将它作为输入来提高模型的性能。但是,我们在训练的过程中发现学习速率的调整是一件比较困难的事情。一方面需要比较小的学习速率去学习细节,一方面比较小的速率又容易陷入局部最优。
如果将初始样本与错误样本结合起来,其他参数都按照初始模型的参数来进行会是一件比较简单的事。
在这里有人会提出这样一个问题,模型一中选出的错误样本对于重新训练的模型是否仍然排斥。

通过上图,我们可以看出,同一张图片在不同的模型下进行训练,他的敏感位置是相同的,所以上述问题的答案是肯定的。同时也可以使用常见的方法进行数据增广。然后整个数据集中,每个batch中的数据依据一定的概率踢馆为错误样本。
4)错误样本的选择
就像上文所说,文中利用一个滑窗来掩盖图片。因此每个滑窗位置都会生成一个新的样本,被视为重训练数据的一部分。假设图片大小是H*W,滑窗大小是d*d,垂直和水平滑动距离是Sw和Sh,因此可以得出下面这个公式:
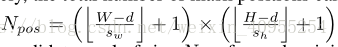
其中N是一个包含了产生的所有掩码图片的池集合。我们就是按着一定的概率,从这个池中选择图片来替代原始数据。这里文中提供了两种方法,一种是hard1,这种方法是在池中,对所有的图片按照重要性进行对比,直接将重要性最高的那张图片作为错误样本进行替换。但是这种方法存在两个问题,对临近区域通常具有相同的重要性,并且有些图片中存在多个目标区域,这种单区域的选择方法就存在一定的弊端性。
第二种方法是对于池中的N种图片进行归一化,然后计算最开始的准确率p,并且将池中掩码后的所有数据带入进行计算得出准确率 p i,然后计算下面的公式:
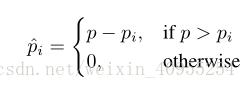
然后通过softmax进行归一化
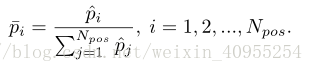
在之后的数据生成中,按照得到的这个概率分布进行。
文章之后还进行了可视化分析,掩码大小对实验结果的影响,掩码几率对实验的影响等一些列分析,这里我就不一一细述了。本文纯属个人学习,如有错误,欢迎交流指正。
1 L. Zheng, Y. Yang, and A. G. Hauptmann. Person re-identification: Past, present and future. arXiv, 2016.















 1650
1650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











