 Scala Spark: 密集与稀疏矩阵的创建与操作
Scala Spark: 密集与稀疏矩阵的创建与操作





 本文介绍了Scala Spark中的矩阵概念,重点讲解了mlib库中的DenseMatrix和SparseMatrix。DenseMatrix以两种形式存储,按列主序存储为默认。创建稠密矩阵可以通过Matrices类或直接实例化DenseMatrix,而SparseMatrix使用列起始号、行号和元素数值数组存储,适合大量0元素的情况。两者提供了构造和操作方法,便于矩阵计算和存储优化。
本文介绍了Scala Spark中的矩阵概念,重点讲解了mlib库中的DenseMatrix和SparseMatrix。DenseMatrix以两种形式存储,按列主序存储为默认。创建稠密矩阵可以通过Matrices类或直接实例化DenseMatrix,而SparseMatrix使用列起始号、行号和元素数值数组存储,适合大量0元素的情况。两者提供了构造和操作方法,便于矩阵计算和存储优化。
mlib中的稠密矩阵和稀疏矩阵
1.矩阵
1.1. mlib中的矩阵特质(Matrix)
Matrix特质是DenseMatrix和SparseMatrix的共同基类,其只包含1个公共变量:

可以看到isTransposed“是否转置”变量默认为false,所以如果在DenseMatrix或SparseMatrix实例创建时,若未传入isTransposed = true的参数,则将以列主序存储矩阵。
1.1. Matrix定义的基本方法
这些在特质中实现的基本方法在其子类中几乎不被重写,有很高的复用性。
//sealed trait Matrix in "Matrices.scala"
返回矩阵元素数组:
toArray: Array[Double]
返回矩阵行迭代器:
rowIter: Iterator[Vector]
·实现是将矩阵转置后再调用子类实现的列迭代器:this.transpose.colIter
返回两个矩阵乘法结果:
multiply(y: DenseMatrix): DenseMatrix
返回矩阵向量乘法结果:
multiply(y: DenseVector): DenseVector
返回矩阵向量乘法结果:
multiply(y: Vector): DenseVector
返回矩阵形式字符串:
toString: String
·调用私有方法asBreeze.toString()
返回以最大行列数控制的矩阵的字符串:
toString(maxLines: Int, maxLineWidth: Int): String
·(这个我一直测试不成功,或者我理解的不对?暂时无解)
返回列主序的稀疏矩阵:
toSparseColMajor: SparseMatrix
返回行主序的稀疏矩阵:
toSparseRowMajor: SparseMatrix
返回对应的稀疏矩阵:
toSparse: SparseMatrix
·底层调用子类重写的私有方法toSparseMatrix(colMajor = true/false/isColMajor)
类似上面的稀疏矩阵,返回稠密矩阵,同样调用子类重写的私有方法:
toDenseColMajor: DenseMatrix
toDenseRowMajor: DenseMatrix
toDense: DenseMatrix
·注意:以上两类转换方法仅仅转换主序,并不转换元素。
·所以转换前后的矩阵元素大小及位置是不变的,仅仅变化的是矩阵的主序存储形式。
返回压缩后的矩阵,该矩阵可能为稠密或稀疏、列主序或行主序的矩阵:
compressed: Matrix
返回压缩后的列主序矩阵:
compressedColMajor: Matrix
返回压缩后的行主序矩阵:
compressedRowMajor: Matrix
·底层实现用多个计算矩阵所占字节数的私有方法,对矩阵进行计算比较,对存储方式进行选择。
2. 稠密矩阵
1.1. mlib中的稠密矩阵(DenseMatrix)
mlib中存储稠密矩阵的形式只有两种,都需要给定行数和列数,以及数值数组,而后分为按列主序存储(默认)和按行主序存储。
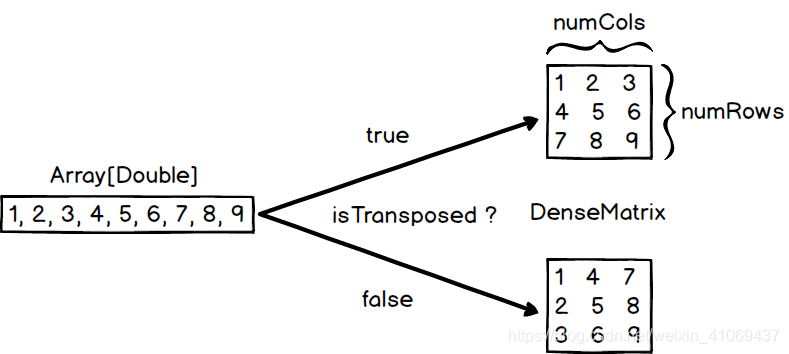
在mlib中创建稠密矩阵的方法有两种,分别是利用Matrices中的静态方法创建不同类型的稠密矩阵,或直接创建DenseMatrix对象,接下来将对这两种方法进行详细解析。
1.1.1. Matrices类中的稠密矩阵构造
先来看一下Matrix类中给出的创建DenseMatrix的方法:
//object Matrices in "Matrices.scala"
创建稠密矩阵:
dense(numRows: Int, numCols: Int, values: Array[Double]): Matrix
创建0矩阵:
zeros(numRows: Int, numCols: Int): Matrix
创建1矩阵:
ones(numRows: Int, numCols: Int): Matrix
创建nxn的单位矩阵:
eye(n: Int): Matrix
生成一个符合均匀分布的随机矩阵:
rand(numRows: Int, numCols: Int, rng: Random): Matrix
生成一个符合高斯分布的随机矩阵:
randn(numRows: Int, numCols: Int, rng: Random): Matrix
生成对角阵:
diag(vector: Vector): Matrix
将矩阵数组横向拼接:
horzcat(matrices: Array[Matrix]): Matrix
将矩阵数组纵向拼接:
vertcat(matrices: Array[Matrix]): Matrix
其中除了horzcat和vertcat外都调用DenseMatrix类中的方法,而行拼接和列拼接方法中对数组中矩阵的类型进行了判断,矩阵可以为Matrix的两个子类DenseMatrix和SparseMatrix,从而以不同的方式返回拼接结果。
1.2. DenseMatrix相关方法
1.2.1. 构造方法
DenseMatrix底层直接以Array[Double]数组存储矩阵数据:
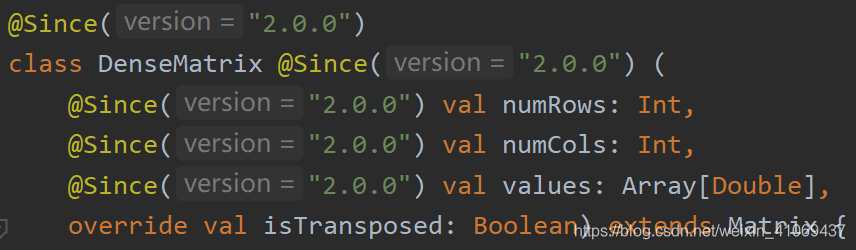
当参数列表缺少isTransposed参数时,默认为false,也就是默认按列主序存储:

Matrices中创建稠密矩阵的方法调用了DenseMatrix的Object类中的静态方法,而这些方法其实就是对DenseMatrix对象创建参数列表中的行列值和数值数组进行简单的运算,也可以直接通过DenseMatrix的静态类中的方法进行直接创建。
//object DenseMatrix in "Matrices.scala"
创建0矩阵:
zeros(numRows: Int, numCols: Int): DenseMatrix
创建1矩阵:
ones(numRows: Int, numCols: Int): DenseMatrix
·内部利用数组方法实现:Array.fill(numRows * numCols)(1.0)
创建nxn的单位矩阵:
eye(n: Int): DenseMatrix
·与ones方法不同,并且也不调用ones方法(这点不太明白为什么这样设计)
·内部利用一个私有的update方法遍历设置:identity.update(i, i, 1.0)
·(这个update方法如此好用却是私有,也很令人困惑,导致mlib中的矩阵无法单独修改某个元素的值)
生成一个符合均匀分布的随机矩阵:
rand(numRows: Int, numCols: Int, rng: Random): DenseMatrix
·内部利用数组方法实现:Array.fill(numRows * numCols)(rng.nextDouble())
生成一个符合高斯分布的随机矩阵:
randn(numRows: Int, numCols: Int, rng: Random): DenseMatrix
·内部利用数组方法实现:Array.fill(numRows * numCols)(rng.nextGaussian())
生成对角阵:
diag(vector: Vector): DenseMatrix
·利用循环进行设置:matrix.update(i, i, values(i))
1.2.2. 成员方法
DenseMatrix类重写的方法:
//class DenseMatrix in "Matrices.scala"
判断两个矩阵是否完全相等:
equals(o: Any): Boolean
返回Hash值:
hashCode: Int
返回指定位置元素:
apply(i: Int, j: Int): Double
复制矩阵:
copy: DenseMatrix
对矩阵进行转置,调换行列主序:
transpose: DenseMatrix
定义函数,利用行列下标和对应元素值进行计算:
foreachActive(f: (Int, Int, Double) => Unit): Unit
·该方法不改变矩阵元素
返回矩阵中非0元素个数:
numNonzeros: Int
·内部利用数组方法实现:values.count(_ != 0)
返回矩阵中元素个数:
numActives: Int
返回列迭代器:
colIter: Iterator[Vector]
3. 稀疏矩阵
2.1. mlib中的稀疏矩阵(SparseMatrix)
mlib中的SparseMatrix稀疏矩阵以列起始号、行号、元素数值三个数组进行存储,具体的构造方法在之后的内容中将体现,我们先以一张示意图看一下mlib是如何以稀疏矩阵的形式存储矩阵的:
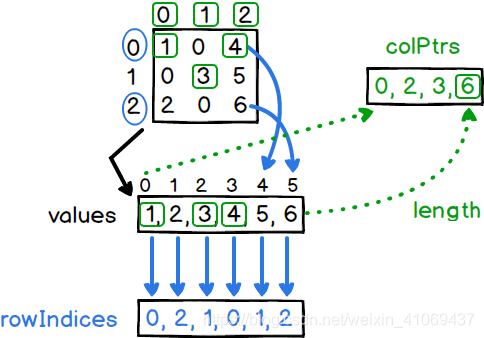
SparseMatrix和DenseMatrix一样,可以通过Matrices静态类或SparseMatrix类提供的方法进行构造。
1.1.1. Matrices类中的稀疏矩阵构造
//object Matrices in "Matrices.scala"
创建稀疏矩阵:
sparse(
numRows: Int,
numCols: Int,
colPtrs: Array[Int],
rowIndices: Array[Int],
values: Array[Double]): Matrix
创建nxn的单位矩阵:
speye(n: Int): Matrix
生成一个符合均匀分布的随机矩阵:
sprand(numRows: Int, numCols: Int, density: Double, rng: Random): Matrix
生成一个符合高斯分布的随机矩阵:
sprandn(numRows: Int, numCols: Int, density: Double, rng: Random): Matrix
将矩阵数组横向拼接:
horzcat(matrices: Array[Matrix]): Matrix
将矩阵数组纵向拼接:
vertcat(matrices: Array[Matrix]): Matrix
可以看出,稀疏矩阵除了构造的方式与稠密矩阵不同外,其它大部分方法是相同的,因为稀疏矩阵和稠密矩阵本身就是矩阵存储的两种方式。
2.2. SparseMatrix相关方法
1.2.1. 构造方法
SparseMatrix底层也是与DenseMatrix一样只采用数组形式存储数据,并没有复杂的数据结构,只不过由三个数组共同存储,当矩阵含大量0元素时,这样的存储形式对比稠密矩阵存储能够节省大量的存储空间:
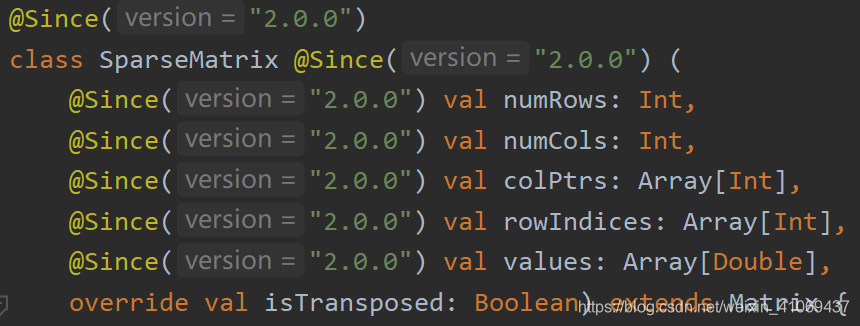
SparseMatrix同样有isTransposed“是否转置”参数,并由此控制列主序还是行主序,默认情况下为列主序:
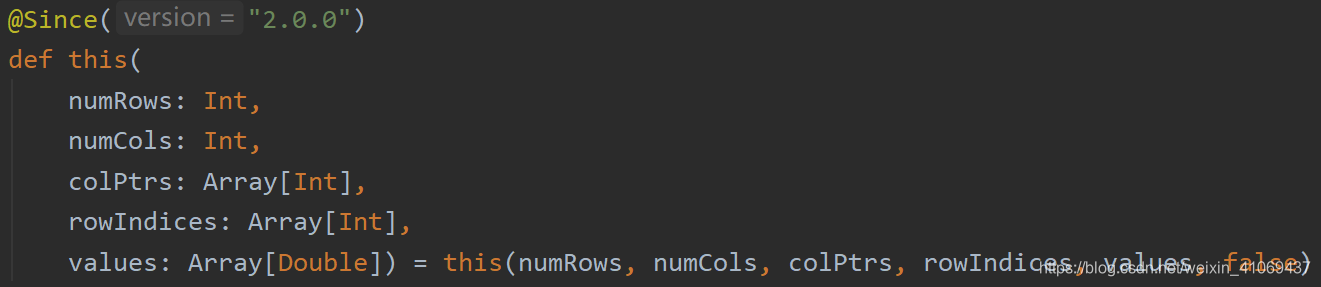
SparseMatrix静态类中同样有被Matrices构造方法调用的静态构造方法,其中有一个fromCOO方法为SparseMatrix独有的方法,可以传入SparseMatrix数据结构的迭代器生成新的矩阵,这个在矩阵拆分时有很大用处。
//object SparseMatrix in "Matrices.scala"
利用SparseMatrix数据结构的迭代器创建稀疏矩阵:
fromCOO(numRows: Int, numCols: Int, entries: Iterable[(Int, Int, Double)]): SparseMatrix
创建nxn的单位矩阵:
speye(n: Int): SparseMatrix
生成一个符合均匀分布的随机矩阵:
sprand(numRows: Int, numCols: Int, density: Double, rng: Random): SparseMatrix
生成一个符合高斯分布的随机矩阵:
sprandn(numRows: Int, numCols: Int, density: Double, rng: Random): SparseMatrix
生成对角阵:
spdiag(vector: Vector): SparseMatrix
1.2.2. 成员方法
SparseMatrix与DenseMatrix一样重写了父类Matrix的部分方法,并且十分相似:
//class SparseMatrix in "Matrices.scala"
判断两个矩阵是否完全相等:
equals(o: Any): Boolean
返回Hash值:
hashCode(): Int
返回指定位置元素:
apply(i: Int, j: Int): Double
复制矩阵:
copy: SparseMatrix
对矩阵进行转置,调换行列主序:
transpose: SparseMatrix
定义函数,利用行列下标和对应元素值进行计算:
foreachActive(f: (Int, Int, Double) => Unit): Unit
返回矩阵中非0元素个数:
numNonzeros: Int
返回矩阵中元素个数:
numActives: Int
返回列迭代器:
colIter: Iterator[Vector]
4. 总结
mlib中的矩阵定义的方法还不是很复杂,通过源码可以比较清晰地了解矩阵库运行的底层形式,为学习和使用提供了很大便利。当然,随着对Mlib矩阵库的了解不断加深,加上通过对源码的探究,mlib中部分设计会令人费解或不适用,这时就需要我们亲自操刀,充分利用库的架构和现有的代码给我们带来的便利,让mlib结合Spark发挥出更加强大的作用!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









