









目录
文本表示方法
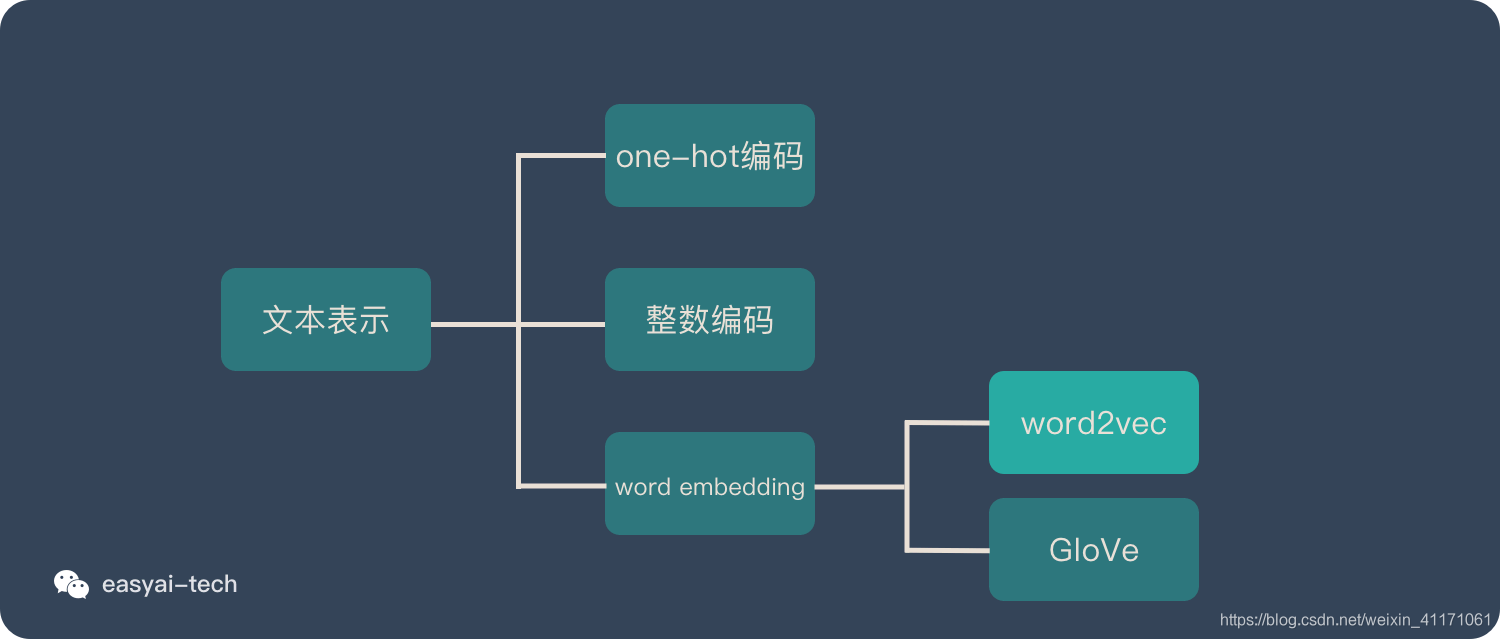
One-hot
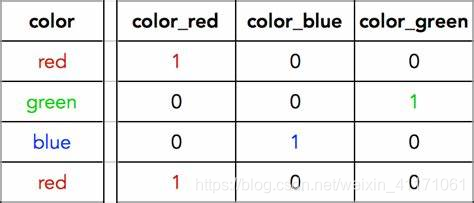
优点:
(1)解决了分类器不好处理离散数据的问题
(2)在一定程度上起到了扩充特征的作用
缺点: 尤其是在文本特征表示上
(1)是一个词袋模型,不考虑词与词之间的顺序,丢失词的顺序信息。
(2)假设词与词相互独立。在大多数情况下,词与词是相互影响的。
(3)得到的特征是离散稀疏的。比如将世界所有城市名称作为语料库,那这个向量会过于稀疏,并且会造成维度灾难。
Q: 对于神经网络而言,在输入特征多数为categorical类别变量时,使用one-hot会使维度大大增加,使用one-hot真的比直接用离散数字表示好吗?
S: 分类问题里,损失函数经常定义为预测值和真实值的误差平方和。离散数字编码之后,3被预测为1的损失>3预测为2(与现实不符)。而one-hot则保证了不同的类别距离相同。 当然实际生活中有许多分类变量也带有距离的含义(比如职称),所以标准基乘上系数可能会更好。当然最后还是要结合实际情况。
把词向量的维度变小?
Dristributed representation通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。这个较短的词向量维度是在训练时指定的。
在 NLP 中,把
x
x
x看做一个句子里的一个词语,
y
y
y是这个词语的上下文词语,那么这里的
f
(
x
)
→
y
f(x)\rarr y
f(x)→y就是语言模型(language model)。这个模型的目的,就是判断
(
x
,
y
)
(x,y)
(x,y) 这个样本,是否符合自然语言的法则,更通俗点说就是:词语x和词语y放在一起,是不是人话。
Word2vec正是来源于这个思想,但它的最终目的,不是要把
f
f
f训练得多么完美,而是只关心模型训练完后的副产物——模型参数(这里特指神经网络的权重),并将这些参数,作为输入x的某种向量化的表示,这个向量便叫做——词向量。
Word2vec
目的:将“不可计算”“非结构化”的词转化为“可计算”“结构化”的向量。
百度百科:
Word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
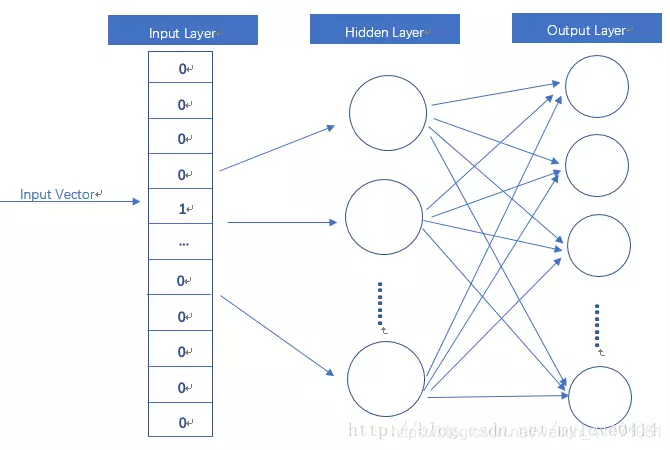
1. Word2vec模型其实就是简单化的神经网络。
2. Word2vec 本质上是一种降维操作:把词语从One-Hot编码形式降维到 Word2vec 形式。
I
n
p
u
t
Input
Input:One-Hot vector
H
i
d
d
e
n
l
a
y
e
r
Hidden~layer
Hidden layer:线性单元,没有激活函数。
O
u
t
p
u
t
L
a
y
e
r
Output Layer
OutputLayer:Softmax回归,维度与Input Layer相同。
O
u
t
p
u
t
Output
Output:模型通过训练数据所学得的参数,隐层的权重矩阵。
CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
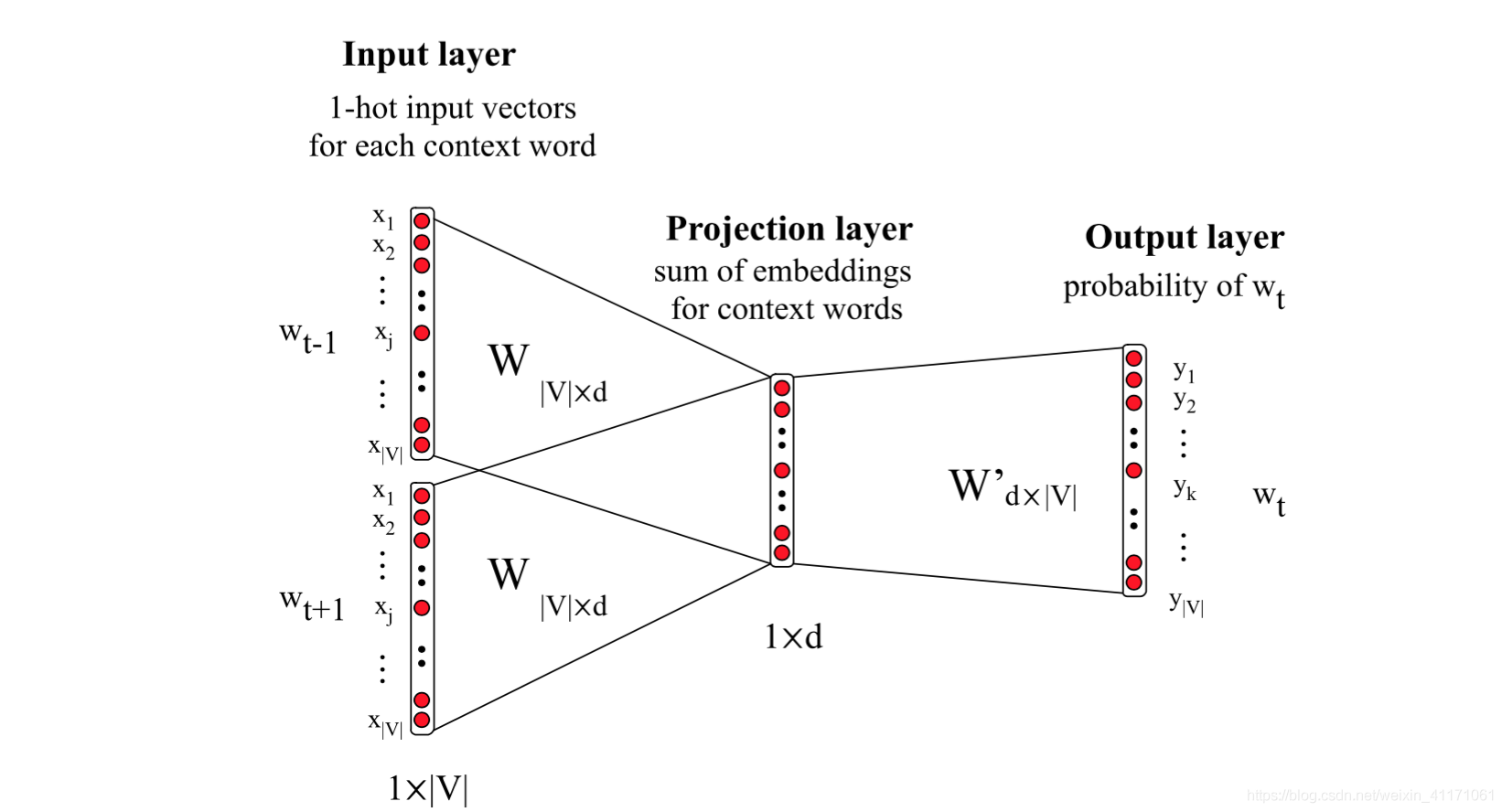
CBOW:给定上下文预测target word
全名:Continuous Bag-of-Words

I
n
p
u
t
l
a
y
e
r
Input~layer
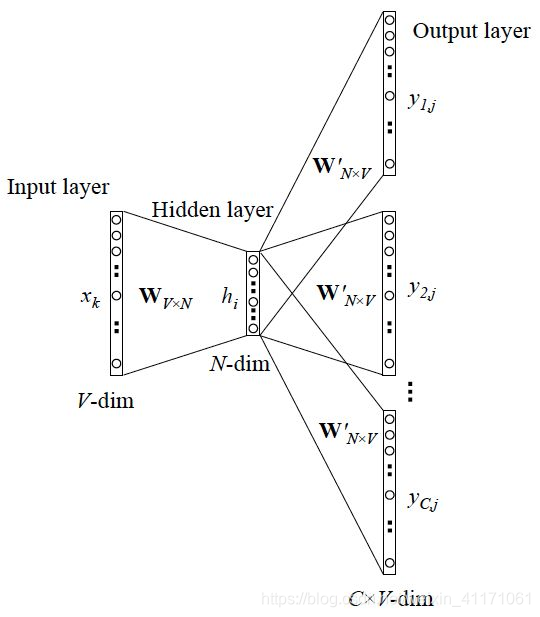
Input layer:上下文单词的one-hot,假设单词的特征空间的维度为
V
V
V。
H i d d e n l a y e r Hidden~layer Hidden layer:输入层的所有one-hot分别乘以共享的输入权重矩阵 W V × d W_{V×d} WV×d,相加求平均,得到隐藏层向量,size为 1 × d 1×d 1×d。
L o s s f u n c t i o n Loss~function Loss function:一般为交叉熵代价函数,采用梯度下降算法更新 W W W和 W ′ W' W′。
O u t p u t l a y e r Output~layer Output layer:隐藏层向量乘以输出层权重矩阵 W d × V ′ W'_ {d×V} Wd×V′,得到 1 × V 1×V 1×V 向量。经激活函数,得到维度为 V V V的概率分布,其中的每一维代表着一个单词的概率(因为是one-hot)。概率最大的index所指示的单词为预测出的中间词(target word),将概率与true label的one-hot做比较,误差越小越好(根据误差更新权重矩阵)。
N e e d O u t p u t Need~Output Need Output:权重矩阵 W V × d W_{V×d} WV×d,其中 d d d为自己设定的数。训练完毕后,输入层的每个单词的one-hot与矩阵 W W W相乘,得到的向量的就是我们想要的词向量(word embedding)。矩阵 W W W就是所有单词的word embedding,也叫做look up table。 也就是说,任何一个单词的one-hot乘以 W W W都将得到该单词的词向量。有了look up table就可以免去训练过程,直接查表得到单词的词向量了。
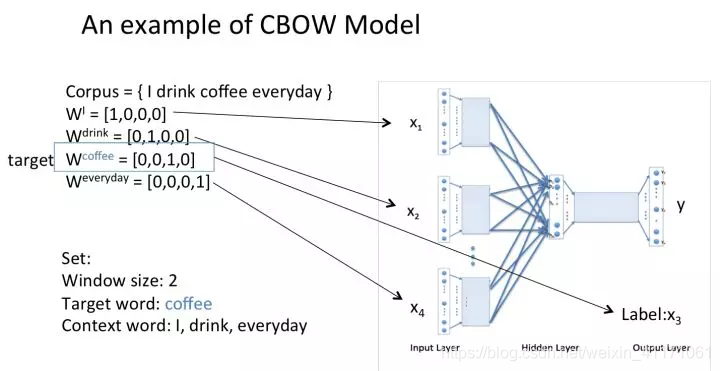
举例:窗口大小是2,表示选取coffe前面两个单词和后面两个单词,作为input词。
训练出来的look up table为矩阵W。即,任何一个单词的one-hot表示乘以W都将得到该单词的word embedding。

Skip-Gram:给定input word来预测上下文

获取训练数据

上图中:
- Training Samples =(Input word, Output word)
- Input word:蓝色框词
- 参数skip_window = 2表示从当前Input word的一侧(左边或右边)选取词的数量为2, 白色框词。
- 参数num_skips表示从整个窗口中选取多少个不同的词,作为output word。
模型训练
神经网络基于这些训练数据,输出概率分布(代表着词典中的每个词是output word的可能性)。如先拿一组数据 (‘dog’, ‘barked’) 来训练神经网络,那么模型通过学习这个训练样本,会告诉我们词汇表中每个单词是“barked”的概率。模型的输出概率代表着:词典中每个词有多大可能性跟input word同时出现。
过程:通过给神经网络输入文本中成对的单词来训练它完成上述概率计算。
再次注意:我们需要的是训练出来的权重矩阵。
此处需要还是 W W W,而不是 W ′ W' W′。因为 y y y是概率,而不是one-hot!词向量是one-hot × W ×W ×W。
训练技巧
Word2vec是一个多分类问题。但实际当中,词语的个数非常多,计算难,所以需要用加速技巧。
- Hierarchical softmax
是 softmax 的一种近似形式,本质是把 N 分类问题变成 log(N)次二分类。 - Negative sampling
本质是预测总体类别的一个子集。
优点
- 考虑上下文,因此跟之前的Embedding方法相比,效果要更好(但不如18年之后的方法)。
- 比之前的Embedding方法维度更少,所以速度更快。
- 通用性很强,可以用在各种 NLP任务中。
缺点
- 由于词和向量是一对一的关系,所以无法解决多义词。
- 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化。
句子、文档层面的任务
- 计算相似度
- 寻找相似词
- 信息检索
- 作为SVM/LSTM等模型的输入
- 中文分词
- 命名体识别
- 句子表示
- 情感分析
- 文档表示
- 文档主题判别
实现:Gensim 和 NLTK
import gensim
sentences=word2vec.Text8Corpus("test.txt") #加载语料库,此处训练集为英文文本或分好词的中文文本,注意去停用词
model=gensim.models.Word2Vec(sentences,sg=1,size=100,window=5,min_count=2,negative=3,sample=0.001,hs=1,workers=4)
model.save("文本名") # 模型保存,打开为乱码
#model.wv.save_word2vec_format("文件名",binary = "Ture/False") #通过该方式保存的模型,能通过文本格式打开,也能通过设置binary是否保存为二进制文件。但该模型在保存时丢弃了树的保存形式(详情参加word2vec构建过程,以类似哈夫曼树的形式保存词),所以在后续不能对模型进行追加训练
gensim.models.Word2Vec.load("模型文件名") # 对.sava保存的模型的加载
model = model.wv.load_word2vec_format('模型文件名') # 对..wv.save_word2vec_format保存的模型的加载
model.train(more_sentences) # 追加训练。如果对..wv.save_word2vec_format加载的模型进行追加训练,会报错
model.most_similar("word",topn=10) # 计算与该词最近似的10个词
model.similarity("word1","word2") # 计算两个词的相似度
model ['word'] # 获取词向量
Natural Language Toolkit:自然语言处理工具包,在NLP领域中,最常使用的一个Python库。
扩展
- 在词嵌入领域,除了 Word2vec之外,还有基于共现矩阵分解的GloVe等词嵌入方法。
来斯惟博士在它的博士论文附录部分,证明了Skip-gram 模型和GloVe的cost fucntion本质上是一样的。
- 输入不一定非得是One-Hot。
- Word2vec在2018年之前比较主流,但是随着BERT、GPT2.0的出现,它已经不算效果最好的方法了。
思考
Word2vec考虑了上下文,那算考虑了词顺序吗?
参考
https://www.jianshu.com/p/471d9bfbd72f
https://zhuanlan.zhihu.com/p/26306795
https://easyai.tech/ai-definition/word2vec/
https://blog.csdn.net/qq_28840013/article/details/89681499














 628
628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









