






像ChatGPT一样的大语言模型,背后的AI技术是什么?它是如何工作的?
像ChatGPT和Bard这样的系统生成文本的能力似乎近乎神奇。它们代表了人工智能技术的重大进步。
但文本生成实际上是如何工作的呢?在这个视频中,我们将深入探讨生成式人工智能技术的底层原理,希望这能帮助你理解你可以如何使用它,以及何时不应过分依赖它。
让我们首先看看生成式人工智能在人工智能领域中的位置。关于人工智能有很多关注、兴奋和夸大之词,我认为将人工智能视为一组工具是一个有用的方式。
在人工智能中,最重要的工具之一是监督学习,它在标记事物方面非常出色。其次,是生成式人工智能。如果你研究人工智能,你可能会认识到还有其他工具,比如称为无监督学习和强化学习。
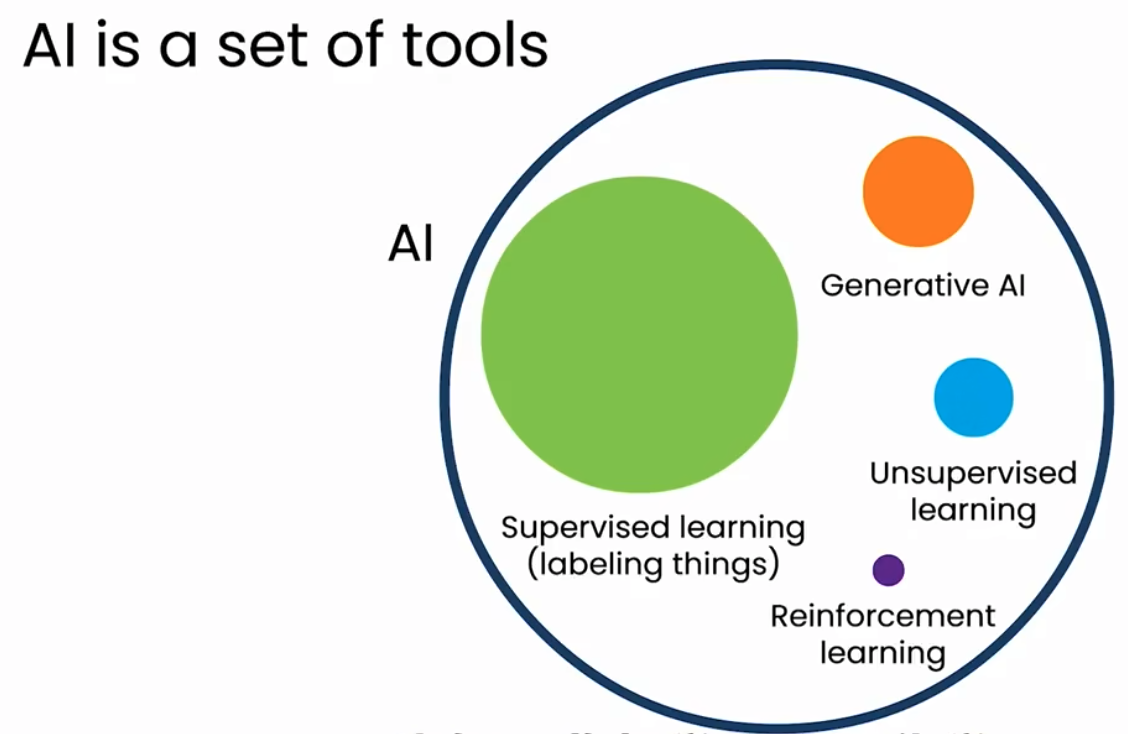
但在本课程中,我将简要介绍监督学习,然后大部分时间都会花在生成式人工智能上。
在描述生成式人工智能是如何工作之前,让我简要描述一下监督学习,因为生成式人工智能实际上是使用监督学习构建的。
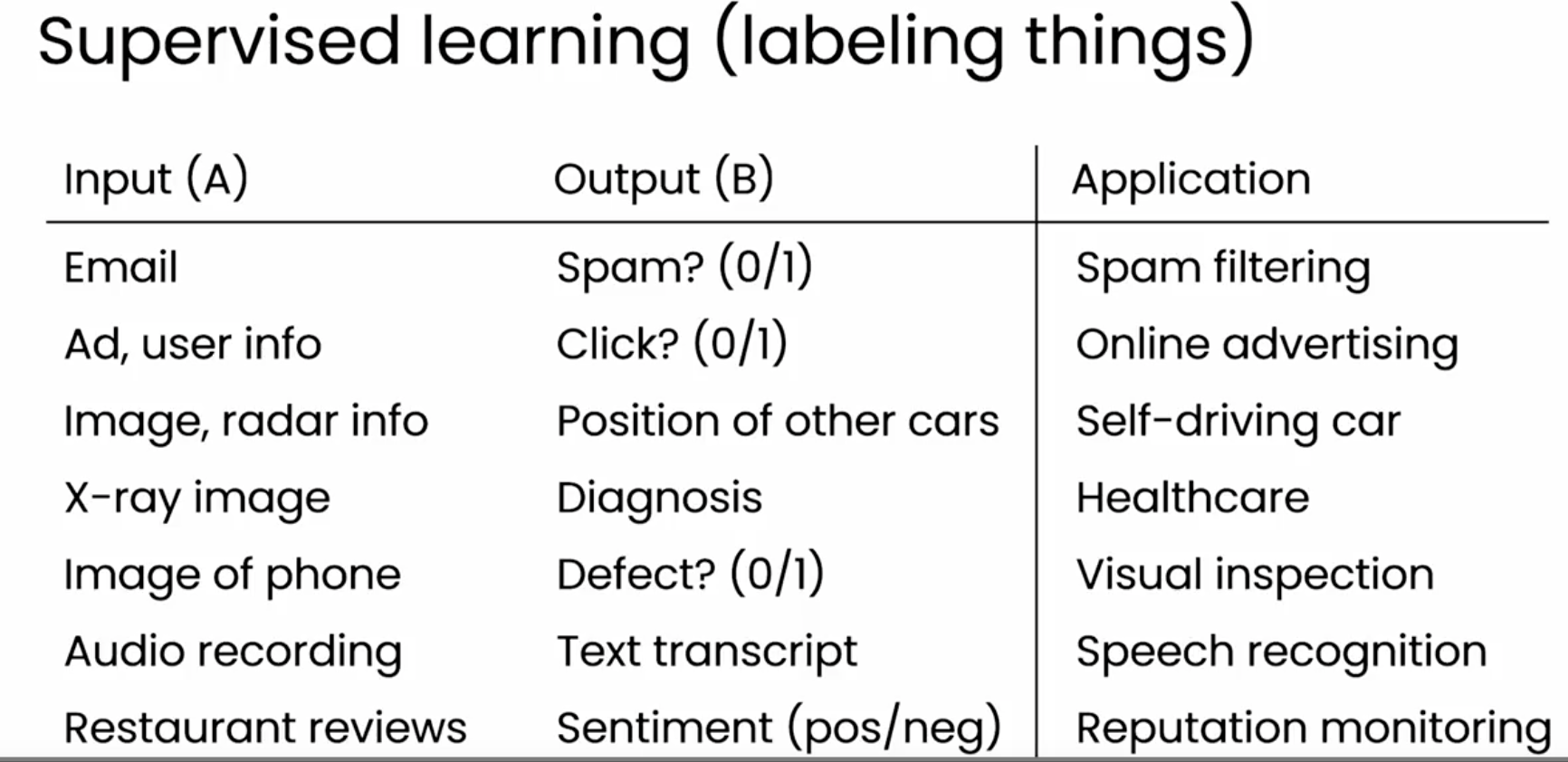
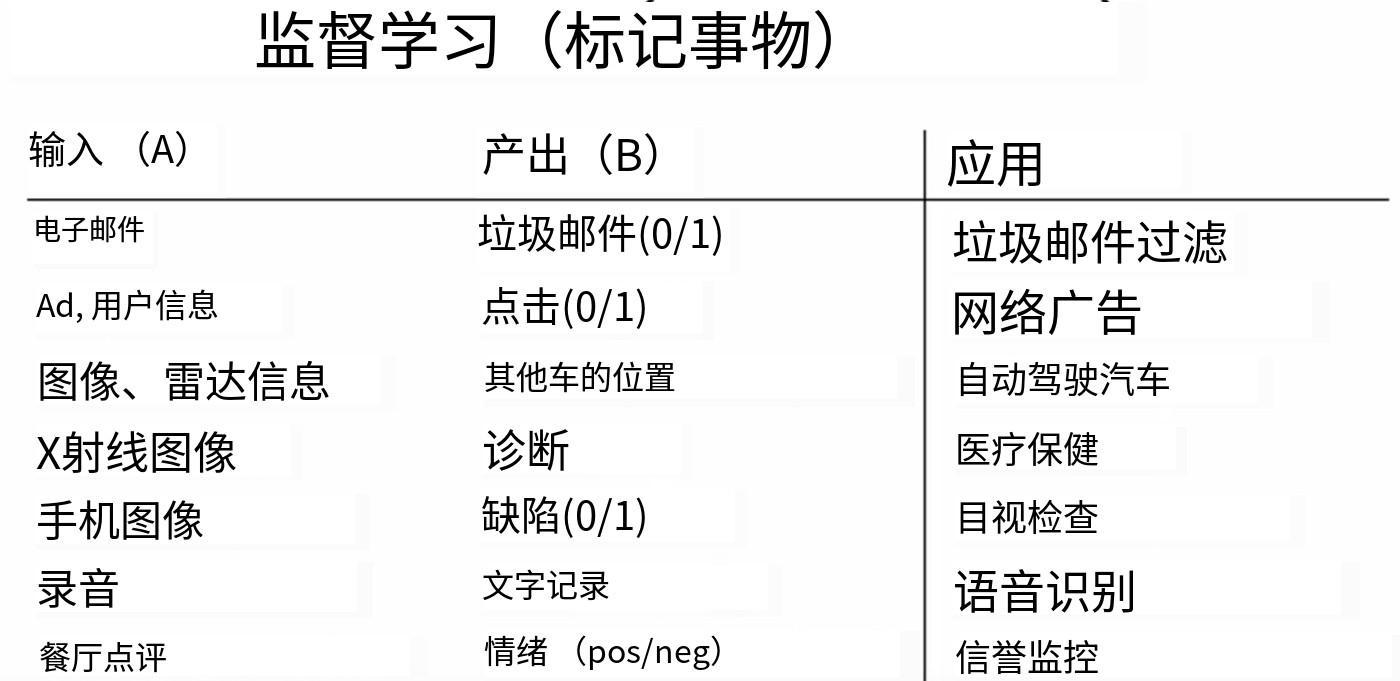
监督学习是一种让计算机在给定输入(我将其称为A)的情况下,生成相应输出(我将其称为B)的技术。
看一些例子。在给定一封电子邮件时,监督学习可以决定该电子邮件是否为垃圾邮件。输入A是一封电子邮件,输出B要么是零,表示不是垃圾邮件,要么是一,表示是垃圾邮件。这就是今天垃圾邮件过滤器的工作原理。
第二个例子,可能是我曾经工作过的一些公司最赚钱的应用,尽管不是最激动人心的,但对一些公司来说非常有利的在线广告,通过给定一则广告和有关用户的一些信息,人工智能系统可以生成与您是否点击该广告相关的输出B。通过展示稍微更相关的广告,这为在线广告平台带来了显著的收入。
实际上,多年前,当我在Google成立并领导Google Brain团队时,我在早期为Google Brain团队设定的主要任务是,让我们建立非常大的人工智能模型并为其提供大量数据。
幸运的是,这个方法奏效了,最终推动了Google在人工智能方面的进步。大规模监督学习至今仍然很重要,但构建非常大的模型来标记事物的这个想法是我们如今得到生成式人工智能的途径。
让我们看看生成式人工智能如何使用一种称为大型语言模型(LLM)的技术来生成文本。
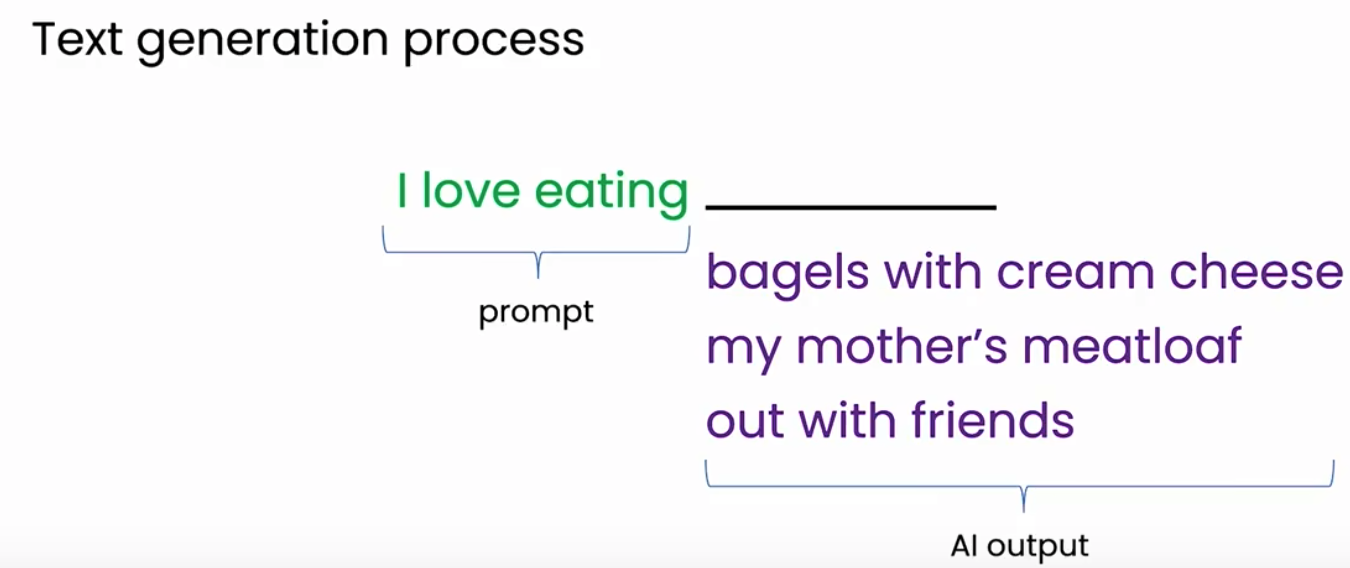
给定一个输入,比如“I love eating”,这被称为prompt(提示词),LLM可以用“可能是带奶油芝士的百吉饼”来完成这个句子,或者如果你再运行它一次,它可能会说“我妈妈的肉l”,或者如果你再运行它第三次,也许它会说“和朋友一起”。
LLM,也就是大型语言模型,是如何生成这个输出的呢?
事实证明,LLM是通过使用监督学习构建的。它使用监督学习来重复预测接下来的一个词是什么。例如,如果一个人工智能系统在互联网上读到一个句子,比如“我最喜欢的食物是带奶油芝士的百吉饼”,那么这一个句子将被转化为很多数据点,以尝试学习预测下一个词是什么。

当你在大量数据上训练一个非常大的人工智能系统,对于LLM来说,大量数据意味着数百亿字,有时甚至是一万亿字,那么你就会得到一个像ChatGPT这样的大型语言模型,它在给定提示的情况下非常擅长生成一些额外的词语作为响应。
目前,我省略了一些技术细节。具体来说,下周我们将讨论一个过程,使LLM不仅仅预测下一个词,而且实际上学会遵循指令,并确保其输出是安全的。
但LLM的核心是从大量数据中学到的技术,以预测下一个词。这就是大型语言模型的工作方式;它们被训练成反复预测下一个词。事实证明,许多人,也许包括你在内,已经发现这些模型对于日常工作中的写作、查找基本信息或作为思考伙伴来帮助思考非常有用。在下一个视频中,让我们看一些例子。
可在coursera网站查看正版视频。吴恩达的生成式人工智能课。本文为学习笔记,如有侵权,联系删除。
文章持续更新,可以关注微公【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的号。坚持以实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
白天工作晚上写文,呕心沥血
觉得写的不错的话最后,求点赞,评论,收藏。或者一键三连

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









