





还在为目标检测项目发愁?用YOLOv11,不仅精度更高,速度还贼快!
想象一下:你只需要1小时,就能从零开始搭建一个完整的目标检测系统。是不是听起来很爽?今天就手把手教你,让你的AI项目瞬间起飞!
🔥 为什么选择YOLOv11?
先说说YOLOv11到底有多牛:
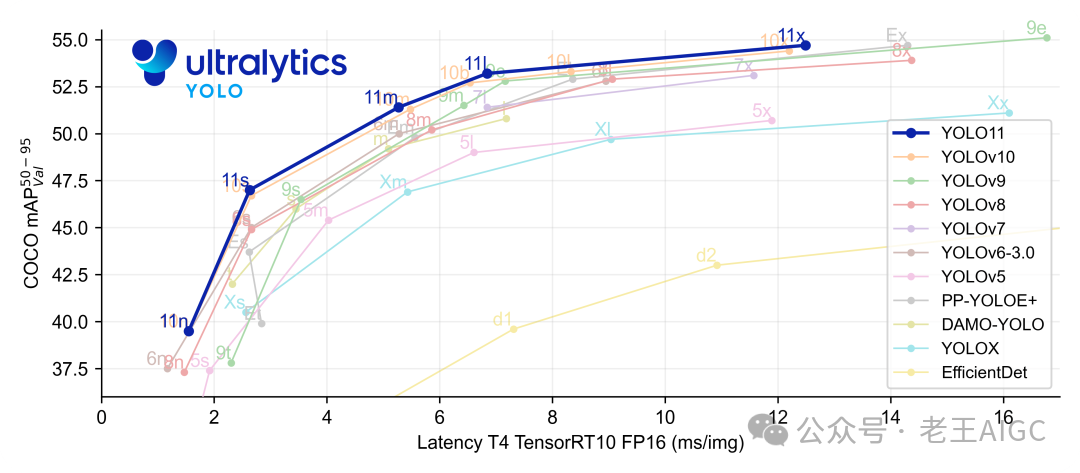
性能爆表:在COCO数据集上的表现比前代提升了15%+,这可不是开玩笑的!
多面手:一个模型搞定目标检测、实例分割、分类、姿态估计,简直是全能选手
部署友好:移动端推理速度快到飞起,再也不用担心卡顿了
上手简单:Ultralytics团队把API设计得超级友好,新手也能秒上手
💻 环境搭建:3分钟搞定
别被环境配置吓到,其实超简单!
# 创建虚拟环境(强烈推荐!)
conda create -n yolov11 python=3.12
conda activate yolov11
# 一键安装核心包
pip install ultralytics
# GPU用户加装CUDA版本PyTorch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128小贴士:如果你已经装了PyTorch,记得跳过重复安装,不然可能会有版本冲突哦!
📊 数据准备:让你的模型有"食物"
数据从哪来?
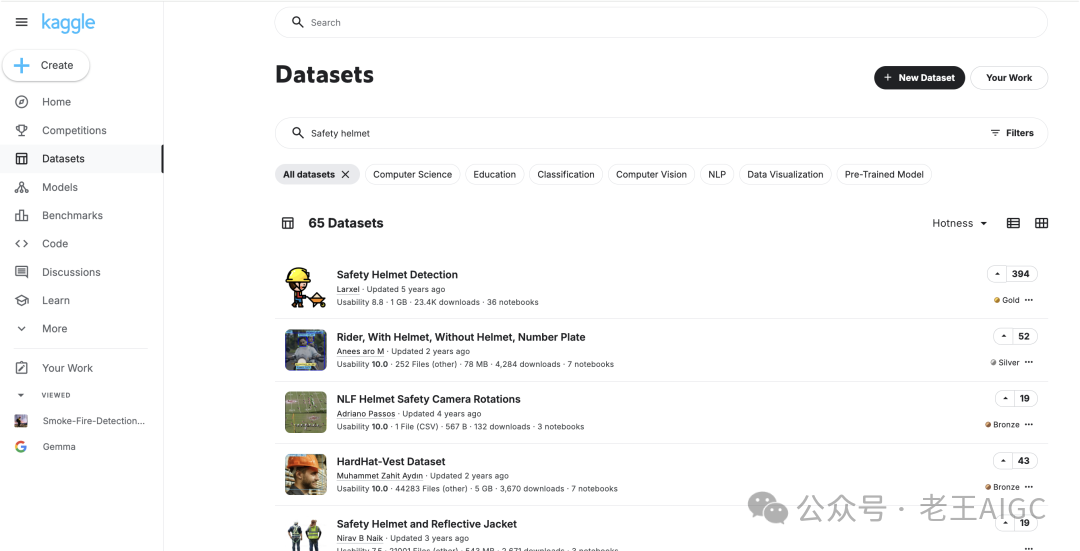
公开数据集推荐:
-
• Kaggle:搜索关键词用英文,比如"Safety helmet",资源超丰富
-
-
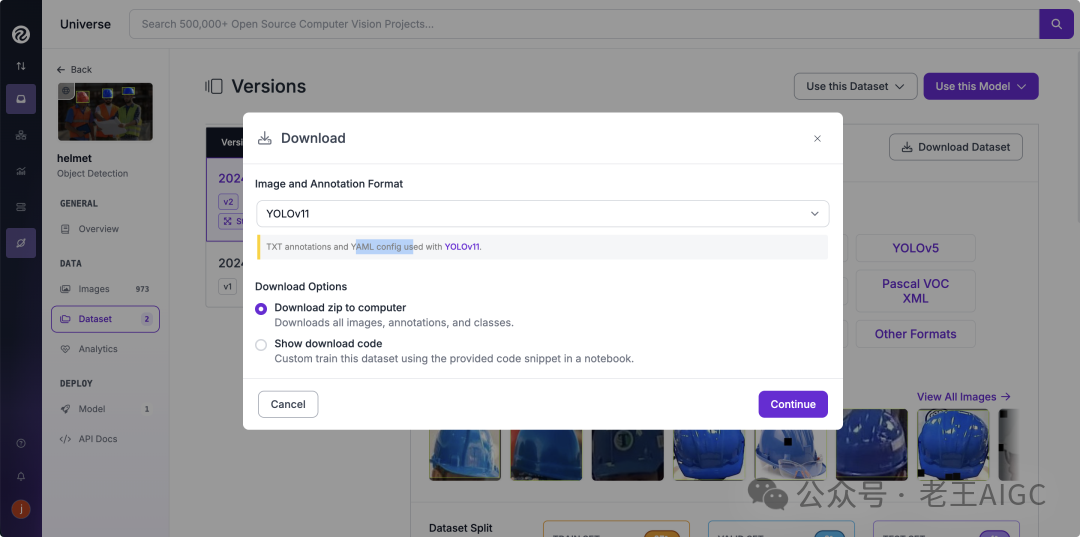
• Roboflow:直接下载YOLOv11格式,省去转换麻烦
-
自己标注数据:
pip install labelimg # VOC格式标注神器
pip install labelme # COCO格式也OK数据格式转换(重点!)
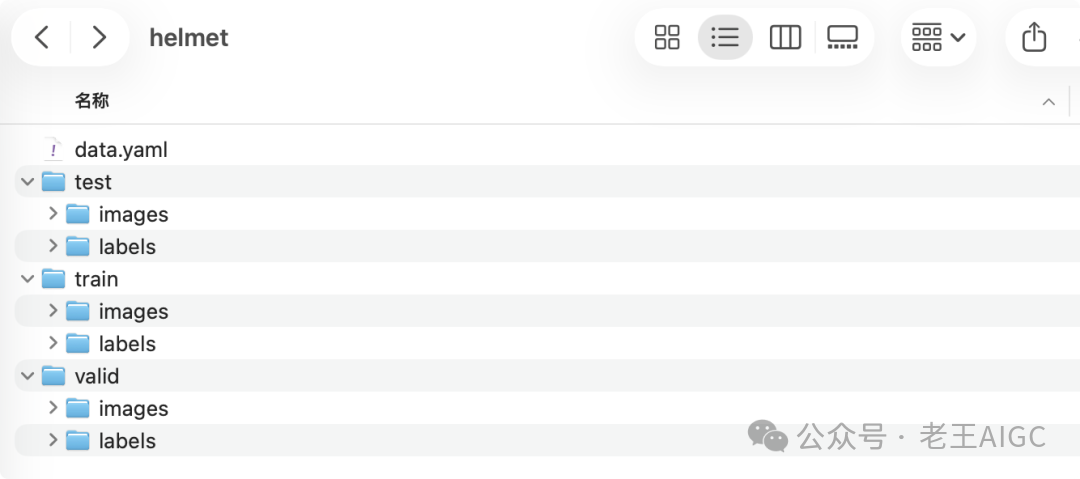
YOLOv11需要特定的目录结构,别搞错了:
VOC转YOLO格式代码(直接复制用):
def convert_bbox(size, box):
"""VOC格式转YOLO格式,归一化坐标"""
dw = 1.0 / size[0]
dh = 1.0 / size[1]
x = (box[0] + box[1]) / 2 * dw
y = (box[2] + box[3]) / 2 * dh
w = (box[1] - box[0]) * dw
h = (box[3] - box[2]) * dh
return [x, y, w, h]⚙️ 配置文件:data.yaml
在项目根目录创建data.yaml:
# 示例:检测人和安全帽
train: datasets/safety/images/train
val: datasets/safety/images/valid
nc: 2
names: ['person', 'helmet']注意:nc(类别数)和names必须对应,这是新手最容易踩的坑!
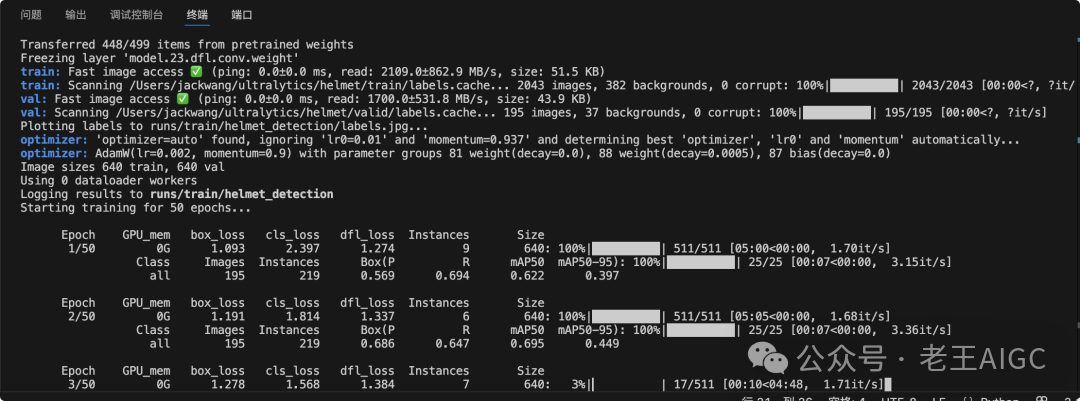
🚀 开始训练:见证奇迹的时刻
Python方式(推荐)
from ultralytics import YOLO
# 加载预训练模型(这步很关键!)
model = YOLO('yolov11n.pt') # n=nano,最轻量
# 开始训练
results = model.train(
data='data.yaml',
epochs=50, # 新手先试50轮
imgsz=640, # 图片尺寸
device=0, # GPU编号,CPU用'cpu'
batch=16, # 批次大小,显存不够就调小
optimizer='AdamW', # 优化器,收敛更快
project='runs/train',
name='helmet_detection',
save_period=10 # 每10轮保存一次
)命令行方式(简单粗暴)
yolo train data=data.yaml model=yolov11n.pt epochs=50 imgsz=640训练小技巧:
• 第一次训练建议用小epochs(10-20),确保流程没问题
• 显存不够?降低batch或换yolov11n.pt
• 想要更高精度?试试yolov11m.pt或yolov11l.pt
📈 模型验证:看看效果如何
from ultralytics import YOLO
import os
defvalidate_model(model_path=):
"""
验证训练好的模型性能
"""
print("🔍 开始模型验证...")
# 检查模型文件是否存在
ifnot os.path.exists(model_path):
print(f"❌ 模型文件不存在: {model_path}")
returnNone
# 加载训练好的模型
model = YOLO(model_path)
# 验证模型性能
metrics = model.val()
print(f"📊 验证结果:")
print(f"mAP50: {metrics.box.map50:.4f}")
print(f"mAP50-95: {metrics.box.map:.4f}")
return metrics
# 使用示例
if __name__ == "__main__":
validate_model('runs/train/helmet_detection/weights/best.pt')关键指标解读:
-
• mAP50:IoU阈值0.5时的平均精度,越高越好
-
• mAP50-95:IoU从0.5到0.95的平均精度,更严格的评估

🎯 推理测试:让模型干活
单张图片推理
from ultralytics import YOLO
import os
defsingle_image_inference(image_path, model_path):
"""
单张图片推理
"""
print(f"🖼️ 开始处理图片: {image_path}")
# 检查模型文件是否存在
ifnot os.path.exists(model_path):
print(f"❌ 模型文件不存在: {model_path}")
returnNone
# 检查图片是否存在
ifnot os.path.exists(image_path):
print(f"❌ 图片文件不存在: {image_path}")
returnNone
# 加载训练好的模型
model = YOLO(model_path)
# 推理
results = model(image_path)
# 显示结果(如果在支持显示的环境中)
try:
results[0].show()
except:
print("💡 当前环境不支持图片显示,将直接保存结果")
# 保存结果
output_path = 'result.jpg'
results[0].save(output_path)
print(f"✅ 结果已保存到: {output_path}")
return results
# 使用示例
if __name__ == "__main__":
single_image_inference('test_image.jpg', 'runs/train/helmet_detection/weights/best.pt')
批量处理
from ultralytics import YOLO
import os
defbatch_inference(input_folder, model_path, output_folder):
"""
批量处理图片
"""
print(f"📁 开始批量处理文件夹: {input_folder}")
# 检查模型文件是否存在
ifnot os.path.exists(model_path):
print(f"❌ 模型文件不存在: {model_path}")
returnNone
# 检查输入文件夹是否存在
ifnot os.path.exists(input_folder):
print(f"❌ 输入文件夹不存在: {input_folder}")
returnNone
# 创建输出文件夹
os.makedirs(output_folder, exist_ok=True)
# 加载训练好的模型
model = YOLO(model_path)
# 处理整个文件夹
results = model(input_folder)
# 保存所有结果
for i, result inenumerate(results):
output_path = os.path.join(output_folder, f'result_{i:04d}.jpg')
result.save(output_path)
print(f"✅ 已保存: {output_path}")
print(f"🎉 批量处理完成!共处理 {len(results)} 张图片")
return results
# 使用示例
if __name__ == "__main__":
batch_inference('test_images/', 'runs/train/helmet_detection/weights/best.pt', 'results/')实时视频检测
from ultralytics import YOLO
import os
def realtime_camera_detection(model_path, camera_id):
"""
摄像头实时检测
"""
print(f"📹 开始摄像头实时检测 (摄像头ID: {camera_id})")
print("💡 按 'q' 键退出检测")
# 检查模型文件是否存在
ifnot os.path.exists(model_path):
print(f"❌ 模型文件不存在: {model_path}")
returnNone
# 加载训练好的模型
model = YOLO(model_path)
try:
# 摄像头实时检测
results = model(source=camera_id, show=True)
print("✅ 实时检测已启动")
except Exception as e:
print(f"❌ 摄像头检测失败: {e}")
print("💡 请检查摄像头是否连接正常")
def video_file_detection(video_path='video.mp4', model_path='runs/train/helmet_detection/weights/best.pt', save_output=True):
"""
视频文件检测
"""
print(f"🎬 开始处理视频文件: {video_path}")
# 检查模型文件是否存在
ifnot os.path.exists(model_path):
print(f"❌ 模型文件不存在: {model_path}")
returnNone
# 检查视频文件是否存在
ifnot os.path.exists(video_path):
print(f"❌ 视频文件不存在: {video_path}")
returnNone
# 加载训练好的模型
model = YOLO(model_path)
try:
# 视频文件检测
results = model(video_path, save=save_output)
print("✅ 视频检测完成")
if save_output:
print("💾 检测结果已保存到 runs/detect/ 文件夹")
return results
except Exception as e:
print(f"❌ 视频检测失败: {e}")
returnNone
# 使用示例
if __name__ == "__main__":
# 实时摄像头检测
realtime_camera_detection('runs/train/helmet_detection/weights/best.pt',0)
# 或者视频文件检测
# video_file_detection('video.mp4', 'runs/train/helmet _detection/weights/best.pt')🔧 常见问题FAQ
Q: 训练时显存不够怎么办?
降低batch size,比如从16改成8或4。或者换更小的模型yolov11n.pt。
Q: 训练中断了怎么办?
别慌!YOLOv11支持断点续训:
model = YOLO("runs/train/helmet_detection/weights/last.pt")
model.train(resume=True)Q: 精度不够高怎么办?
• 增加训练数据,特别是困难样本
• 尝试数据增强
• 调整学习率和优化器
• 使用更大的模型(yolov11m.pt或yolov11l.pt)
Q: 推理速度太慢?
• 降低输入图片尺寸(imgsz=416)
• 使用TensorRT或ONNX优化
• 选择更轻量的模型
Q: 标注数据太累?
试试半监督学习或主动学习,让模型帮你挑选最有价值的数据进行标注。
📚 推荐阅读
想要进一步提升?这些文章不能错过:
1. 10分钟上手YOLOv11:最强姿态估计模型来了,代码开源,效果炸裂!
2. Qwen3-VL震撼登场!工业智能质检系统Dify实战案例让你3分钟上手最强视觉AI
3. 3分钟学会!用Google Colab免费微调AI大模型,手机也能跑
🎉 总结
恭喜你!现在你已经掌握了YOLOv11的完整流程:
✅ 环境搭建:3分钟搞定开发环境
✅ 数据准备:学会了数据标注和格式转换
✅ 模型训练:掌握了训练参数调优
✅ 效果验证:知道如何评估模型性能
✅ 推理部署:实现了从图片到视频的全场景应用
下一步行动建议:
1. 找个小项目练手,比如检测口罩佩戴
2. 尝试不同的模型大小,找到速度和精度的最佳平衡
3. 学习模型优化技术,为生产环境做准备
记住,AI的世界变化很快,但掌握了核心方法,你就能快速适应任何新技术。现在就开始你的YOLOv11之旅吧!
立即体验:关注公众号发消息「YOLO模型」,获取完整安全帽检测模型的权重文件。
想了解更多AI工具和技术趋势?关注我,每周为你带来最新的AI资讯和实用教程!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









