




 Voxel-FPN是一种点云上的one-stage 3D目标检测器,通过多尺度体素特征聚合提高检测性能。文章介绍了其编码器网络、解码器和区域候选网络(RPN)的结构,强调了多尺度体素特征的重要性,并与其他3D检测方法进行了比较。
Voxel-FPN是一种点云上的one-stage 3D目标检测器,通过多尺度体素特征聚合提高检测性能。文章介绍了其编码器网络、解码器和区域候选网络(RPN)的结构,强调了多尺度体素特征的重要性,并与其他3D检测方法进行了比较。
前言
1. 为什么要做这个研究?
目前基于体素的3D目标检测多为从单一尺度的体素中提取体素特征信息,再进行检测,而作者提出了一种密集聚合结构,以自底向上的方式从多尺度编码体素特征。
2. 实验方法是什么样的?
- 将整个点云按照不同尺寸的体素细胞大小(S、2S、3S)划分成体素网格;
- 对每个体素随机抽取相同数量N个点,通过VFE结构提取体素特征信息;
- 高分辨率的体素特征图(体素细胞大小=S)经过多层卷积,下采样输出尺寸缩小一半,然后与低分辨率的体素特征连接,作为下一组卷积块的输入,这样就可以聚合不同尺度的体素特征信息。
- 使用特征金字塔网络(FPN),将低分辨率的特征输入通过上采样提升再与高分辨率的特征连接,每种尺寸的特征图都会直接连接到检测头(检测头具体结构没说)。
3. 得到了什么结果?
作者的贡献在于采用了多尺度体素特征信息进行检测,网络的结构简单,但是效果很好,不过很多细节没有解释清楚,比如检测头结构没有说;为什么添加了4S的feature,效果反而下降了;以及SSD为什么比FPN-RPN强。
摘要
作者提出了Voxel-FPN,一种基于点云的one-stage 3D目标检测器。核心框架包括编码器网络、解码器和区域候选网络(RPN)。编码器以自底向上的方式提取多尺度体素信息,而解码器采用自顶向下的方式融合不同尺度的多特征映射。
1. 介绍
在自动驾驶应用中,相机和激光雷达可以同时捕捉RGB图像和3D点云,目前实现三维目标检测的方法的可分为:
- 融合方法,即同步融合RGB图像和预处理后的三维点云的区域特征,需要成熟的2D检测框架将底层点云投影到鸟瞰视图(BEV)中,可能会导致一定程度的信息丢失。
- 2D检测驱动方法,在RGB图像的检测结果2D bbox扩展后的3D子空间中进行后续的目标检测(视锥方法),RGB图像中缺少目标可能导致检测失败。
- 基于点云的方法,探索点的特征和内部拓扑来检测三维目标。
本文提出的Voxel-FPN可以看作是点云上操作的一个经典的编码器-解码器框架。现有基于体素的方法只利用了单个尺度的体素,作者编码了多尺度体素特征,然后通过自底向上的途径聚合,设计了一个相应的特征金字塔网络(FPN)来解码这些不同尺度的特征地图,并将它们与最终的检测输出关联起来。作者的贡献包括:
- 第一次在3D检测任务中对点云数据进行多尺度体素特征聚合。
- 大量研究多尺度体素特征聚合的合适配置,在处理点云数据进行3D检测任务时,并不是特征越多越好,需要经过筛选。
2.相关工作
2.1 点云表示学习方法
3D目标检测方法需要从点云中学习识别特征,一种简单的方法是将三维点投影到二维平面,利用传统的二维卷积网络进行特征提取,但是降维投影消除了空间相关性,并丢失了点之间的拓扑结构。
PointNet在点云上应用了非线性变换和最大池化操作来预测分类分布。由于每个点共享变换,实际中可学习参数较少,时间消耗相对较低。因为全连接层只影响特征维数,PointNet允许尺寸可变的点云集作为输入。
当使用共享映射处理每个点并通过观察全部点集的相关性来探索全局信息时,PointNet可能会忽略不同尺度上的局部特征。因此,PointNet++着重于从相邻的点构建丰富的层次特征。一个集合抽象层(SA层)由采样局部中心点、分组和一个小型PointNet模块来聚合局部区域的特征。SA层的目的是分层提取特征,然后通过FP层(插值和跨层跳跃连接)进行上采样操作。
PointNet的优点是产生逐点或全局特征的极大灵活性,点可以进一步体素化或者分组,这使得PointNet可以作为一个基本组件嵌入到3D检测框架中。例如,VoxelNet中提出的体素特征编码(VFE),根据点的局部坐标将点分组为体素。与PointNet的架构类似,在每个体素细胞中进行线性转换和最大池化聚集特征,然后收集体素特征并传输到中间层,形成关于局部邻域形状的描述信息。
2.2 基于融合的3D目标检测
MV3D和AVOD将点云投影成多个视图,如在BEV或前视图中,将RGB图像中相应区域的特征叠加,最终融合生成一个用于检测的全面表示。由于2D图像和3D空间稀疏分布的点不对齐,这种融合方法可能存在瓶颈。
2.3 基于点云的3D目标检测
F-PointNets将2D检测结果扩展到3D空间的相应视锥中,然后使用PointNet/PointNet++将点分割成二进制(前景或背景)类,使用前景点进行回归。但当前视图中存在物体遮挡时,视锥中有多个物体,效果就不好了,这种检测方法依赖于输入的2D proposal的质量。
2.4 2D proposal驱动的3D目标检测
基于点云的方法可以进一步分为基于体素和基于点的两个粒度级别。VoxelNet将点分组为体素,提取每个体素中的特征,并将提取的体素特征聚合到中间的卷积层中进行检测。PointPillars利用两个物体在高度维度上没有重叠的先验知识,只在BEV平面实现体素化,点被分组成垂直列,而不是跨步体素。相对于在VoxelNet中需要大量计算的3D卷积,PointPillars向2D卷积转移,从而大大降低了点特征提取的空间和时间复杂度。
PointRCNN是一个two-stage的3D检测器,首先提取逐点特征,并将每个点作为候选框的回归中心。为了减少过多的输入点,在第一阶段使用标准的PointNet++来分割点,只将前景点作为回归目标,在第二阶段,生成的3D候选框和感兴趣区域(ROI)中的局部聚合特征一起被收集,用于定位和分类细化。
3. 整体架构
如图1所示,所提出的框架主要由三个区块组成:体素特征提取、多尺度特征聚合和具有特征金字塔结构的区域候选网络(RPN-FPN)。
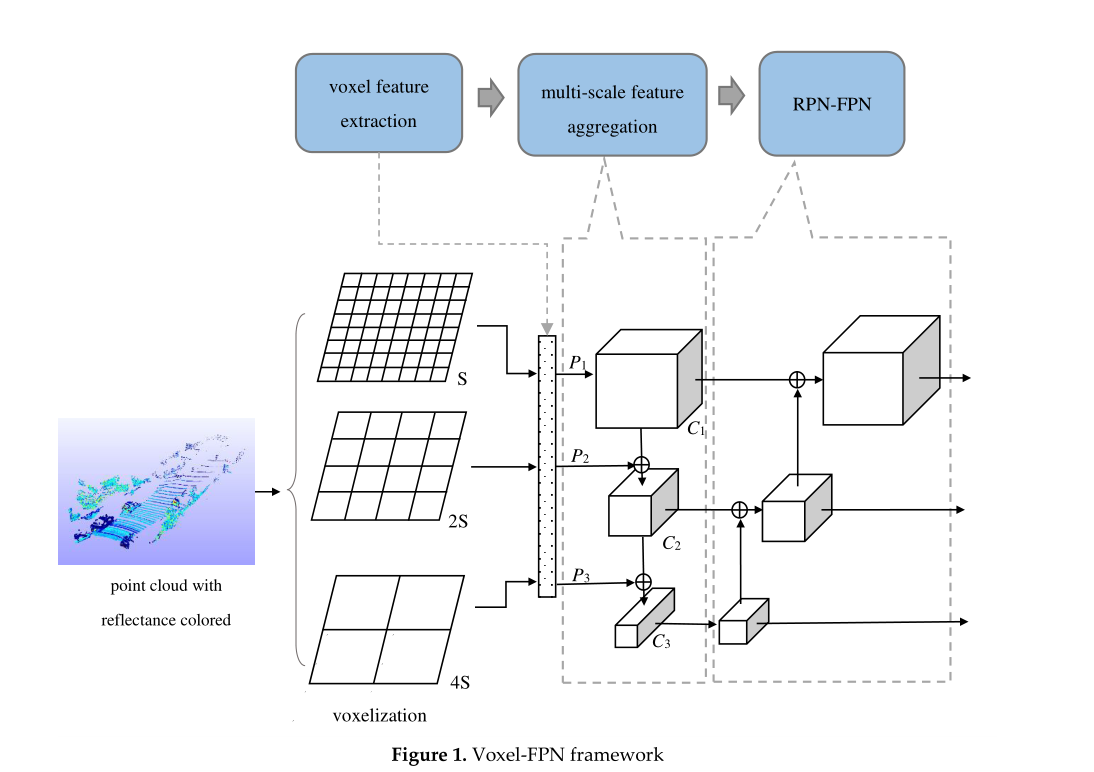
3.1 体素特征提取
3D空间被分成不同的候选区域,并从鸟瞰视图生成默认锚定网络。假设点云的范围是沿着xyz轴的 W , H , D W,H,D W,H,D范围空间,被分成均匀分布的体素细胞,表示为 ( v W , v H , v D ) (v_W, v_H, v_D) (vW,vH,vD),产生的体素网格的尺寸为 ( W / v W , H / v H , D /
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









