







工业界通用推荐系统架构:
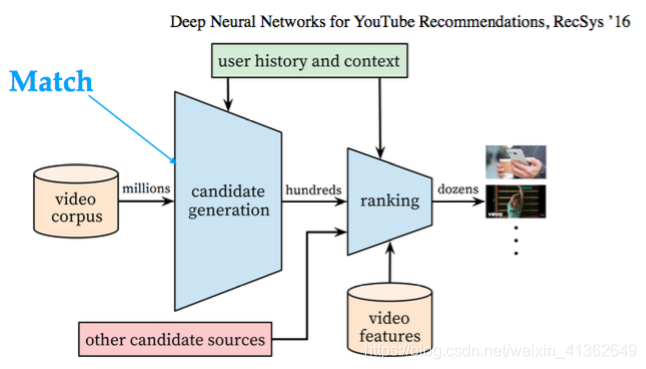
Match&Rank
定义:Match基于当前user(profile、history)和context,快速在全库中找到TopN最相关的Item,给Rank来做小范围综合多目标最大化
通常做法:通常情况下,用各种算法做召回,如:item/user/model-based CF/DNN等等,做粗排之后交由后面的Rank层做更精细的排序,最终展现TopK item.
Match 算法典型应用
猜你喜欢:多样推荐 相似推荐:看了还看 搭配推荐:买了还买
协同过滤算法介绍(Collaborative Filtering简称CF):
1、定义:
简单地来说,CF就是收集(collaborative)用户偏好信息预测(filtering)用户的兴趣
数学形式化:矩阵补全问题
分类:
CF主要包括:
基于邻域(内存、共现关系)的协同过滤---->又包括user-based CF和Item-based CF
基于模型的协同过滤(model-based CF)
2、基于共现关系的协同过滤算法
1、User-based CF :基于用户的协同过滤算法,多用于挖掘那些有共同兴趣的小团体,通常新颖性比较好,准确性稍差
2、Item-based CF:基于物品的协同过滤算法,多用于挖掘物品之间的关系,然后根据用户的历史行为来为用户生成推荐列表
相比于user-based方法,item-based的应用更加广泛
3、相似度
计算相似度主要是通过余弦距离计算
similarity(A,B) = cos(A,B) = A*B/||A||*||B||
1)有时候为了简化,会直接去掉分母,会出现哈利波特效应
(哈利波特效应是指 某个物品太热,而导致好多物品都会跟热门物品关联)
2)在大数据量的环境下,直接计算两个用户之间的相似度,会出现很多用户之间没有对相同的物品进行过行为,大部分交集为 0,为了解决此问题,需要建立每个物品对应用户的倒排表,如下图所示:
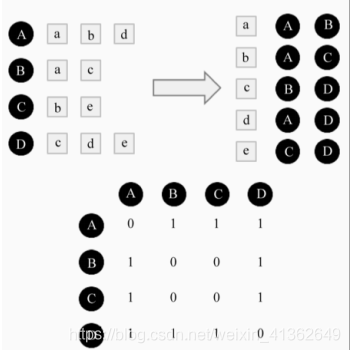
可以根据倒排表,只对有效的pair进行计算,从而简化计算
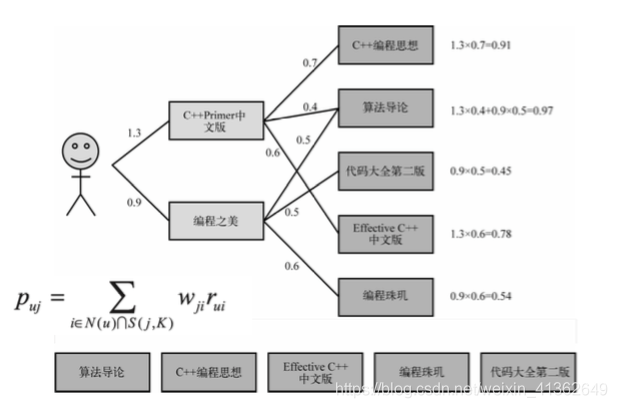
还有一个子主题的知识,看一下下图便知怎么回事,如下图所示:
4、基于ItemCF的推荐算法调用示意图:
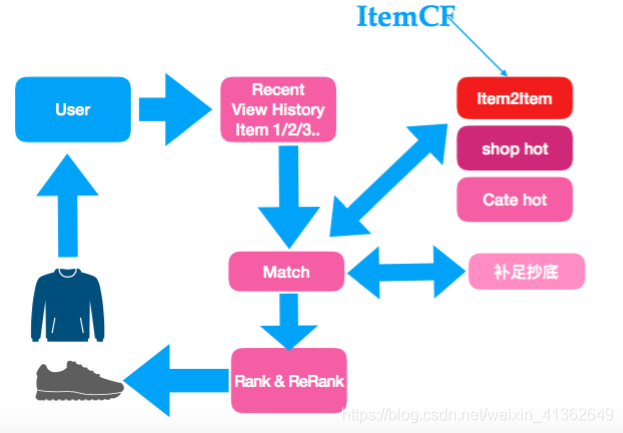
尽量不做补足抄底,用算法补全(补足抄底是指match阶段数据不够,可能会使用热门进行补足)
match后面一般有rank和rerank的策略
5、改进Item2Item
针对之前计算Item2Item存在问题:热门用户、哈利波特效应、用户行为缺乏考虑
解决办法:热门用户降权,热门Item降权
降低热门用户影响:

缓解哈利波特效应:

综合考虑:1、用户行为差 2、热门用户降权
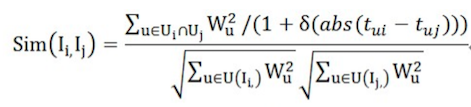
![]()
6、实时Item2Item
针对之前的情况会出现新品推荐问题
解决办法:实时增量Item2Item
![]()
分子:根据user,item的时间顺序流,需要更新item的pair,到存储中去
实时更新统计量
具体详见下述参考文献1
7、混合Item2Item算法框架
针对之前的情况会出现每个场景都用同样的Item2Item
解决办法:有监督混合多种Item2Item算法
1)Learning to Rank
在信息检索中,给定一个query,搜索引擎会召回一系列相关的Documents(通过关键词匹配等方法),然后需要对这些召回的Documents进行排序,最后将Top N的Documents输出。而排序问题就是使用一个模型f(q,d)来对该query下的documents进行排序,这个模型是用机器学习算法训练的模型也可以是人工设定的规则;最关注的是各个Documents之间的相对顺序关系,而不是各个Docuemnts预测分数最准确
具体详见下述参考文献2
2)Hybrid Item2Item算法框架利用Learning to Rank的思想重构Item2Item
以短视频推荐为例:
Feature:
Item Feature : video ctr、video pv、video_comment、
Trigger Feature : trigger ctr、topic ctr
Model:
自己学习各自特征的重要性
Loss:Pairwise Loss,同时优化CTR、LikeR、FavorR
Lambdamart/Neural Nets
3、基于模型协同过滤
1、SVD算法:
目标函数:
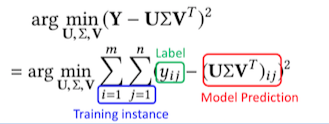
SVD存在的几个问题:1、缺失数据和观测到的数据权重相同(>99% 稀疏性) 2、没有正则项,容易过拟合
SVD具体知识可参考下述参考4
2、矩阵分解(Matrix Factorization)算法
主要改进
用latent vector来表示user和item(ID embedding)
组合关系用内积inner product(衡量user对于某一类商品的偏好)
简化SVD:
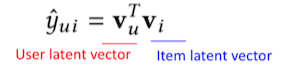
举例:u_1,u_2,i_1,i_2,构造4条样本,构造v_u,v_i矩阵
损失函数:
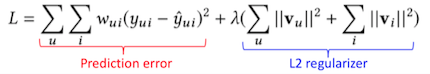
w_ui是样本的权重,比如可观测和不可观测的,权重不同
具体详见下述参考文献5
3、Factored Item Similarity Model(因子项相似度模型)
1)MF用UserID来表示用户,可以叫做user-based CF.(找到相似的user用于推荐)
2)用用户评价过的item表示用户,可以叫做item-based CF(找到相似的item用于推荐)

具体可参考下述参考6
4、SVD++:Fusing User-based and Item-based CF
1) MF(user-based CF)表示UserID表示用户 -> 直接映射ID到隐空间
2) FISM(item-based CF)用用户评价的item来表示用户 -> 映射items到隐空间
3) SVD++混合两种想法
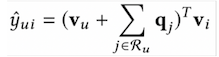
具体文献详见下述参考文献7
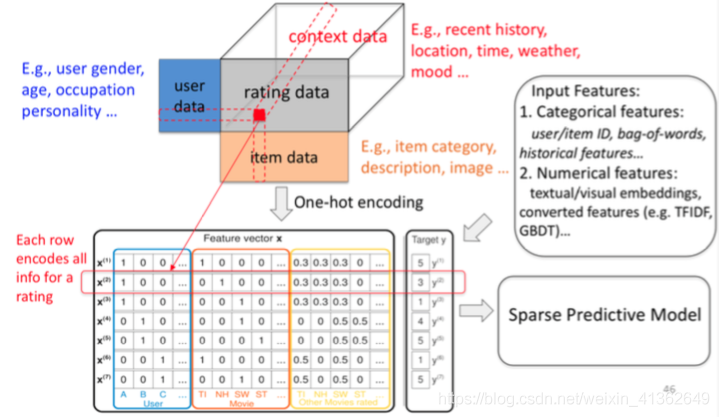
5、Generic Feature-based Recommendation
上述说到CF的一些算法,但是CF只是用交互矩阵来构建模型,没有利用user/item属性和上下文
如下图所示:
6、FM:Factorization Machines
FM受到前面所有的分解模型的启发,每个特征都表示成embedding vector,并且构造二阶关系
FM允许更多的特征工程,并且可以表示之前所有模型为特殊的FM
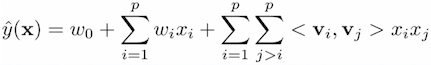
只有uid,item_id,那么就相当于是MF;UserID和Item评价,相当于是SVD++
具体文献详见下述参考文献8
7、之前和现在优化loss方面的区别
之前的很多工作都在优化L2 loss:
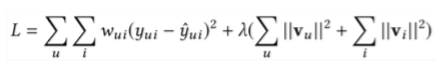
很多内容表明:一个低MSE模型不一定代表排序模型效果好
可能的原因:均方误差和排序指标之间的分歧(排序指标AUC等);观察有偏用户总是去对喜欢的电影打分
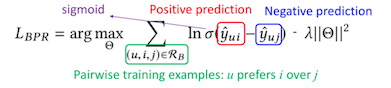
现在大部分工作都是朝向优化pairwise ranking loss
Known as the Bayesian Personalized Ranking loss 个性化排名 优化相对顺序,而不是优化绝对值
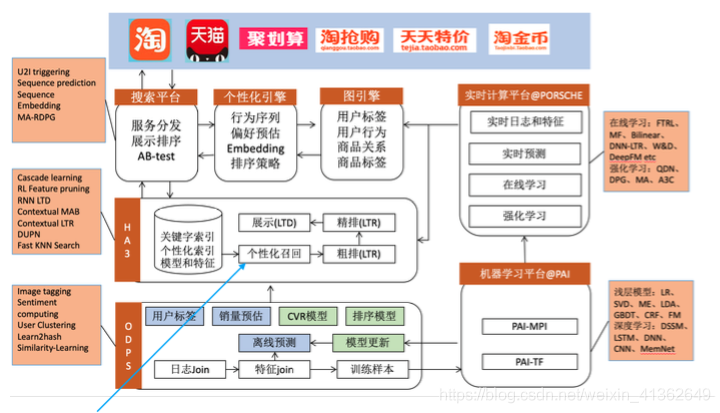
8、淘宝搜索推荐核心系统架构(2018)
具体文章可参考下述参考9
4、深度协同过滤模型(Deep Collaborative Filtering Model)
Methods of representation learning
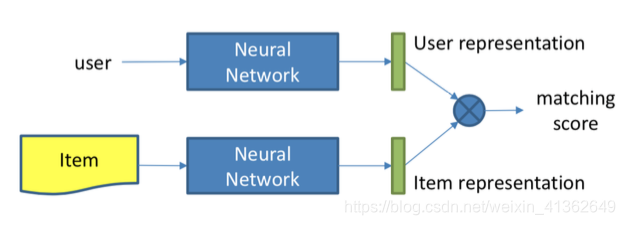
Methods of matching function learning
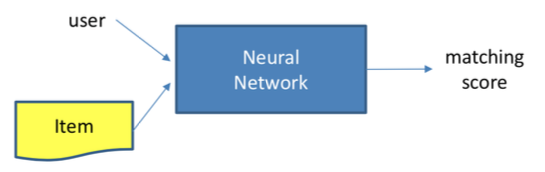
embedding 学习常用算法:
1、矩阵分解(Matrix Factorization)
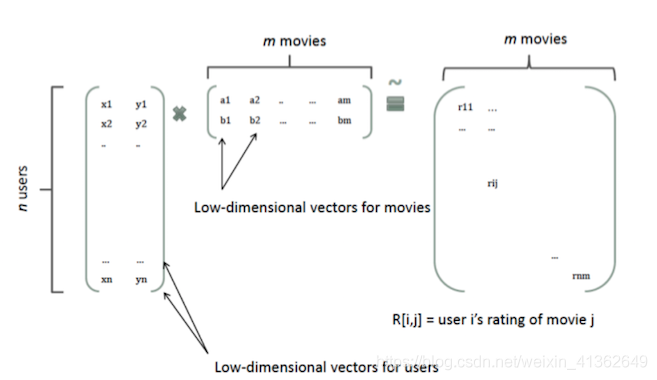
2、topic model
1) embedding from topic model:
看看下面这两张图片你会明白很多东西,?

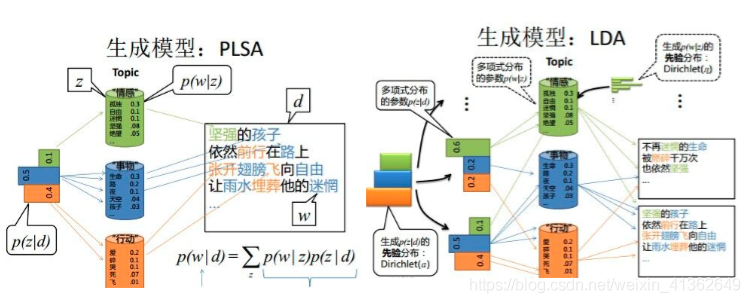
2) LDA in music recommendation:(LDA是一个无监督算法,和聚类有点类似的味道)
建模:歌曲(doc) - 歌词(word) 只看歌词可能是片面的,有时候需要加上其它的特征;用户(doc) - 歌曲(word)
应用:
相似歌曲:根据doc的topic分布计算相似度
生成歌单:每个topic下概率最大的doc
频率比较低的词学习的效果不好
3、word2vec
1)由来:
传统的N-gram统计语言模型:最大化转移概率:w = argmax P(w|History);将词看作原子单位,相互独立;不考虑词之间的相似性;效果受限于语料规模;大多数情况下语料不足,需要平滑
神经网络语言模型:最大化最大似然估计:w = argmax P(w|content);词的分布式表示:词向量;超越n-gram模型-通过上下文,即周围的环境来表示词
其它方法:
LSA:Latent Sematic Analysis 没有线性规则;LDA:Latent Dirichlet Allocation 大数据训练太慢
2)实现方法:
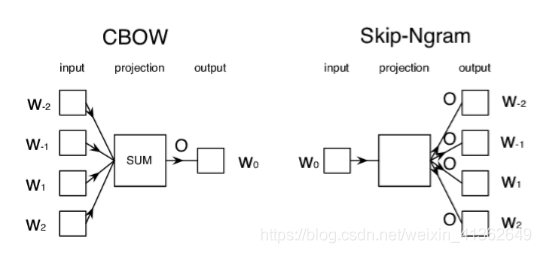
Skip-Ngram是根据word来预测上下文的概率P(context|word)
CBOW(continuous Bag of Words):根据context来预测word概率P(word|context)
3) 训练
Hierarchical Softmax:使用一颗二分Huffman树表示,叶子节点是单词,词频越高离根节点越低,优化计算效率O(logV)
Negative Sampling:

4)优势
不丢失信息的情况下降低维度;矩阵及向量运算便于并行;向量空间具有物理意义;可以在多个不同的维度上具有相似性
线性规则:

4、DNN(Youtobe应用)
1) embedding from DNN:
2)DNN at Google

训练training:通过分类任务学习出用户向量和视频向量,每个视频作为一个类别,观看完成是视频作为一个正例;把最后一层隐层输出作为用户向量(U+C);video embedding:pre trained to feed or training together
服务serving:输入用户向量,查询出与之向量相似度TopK高的视频
3)DNN at Google 前人的一些经验
随机负采样效果好于hierarchical soft-max
使用全量的数据而不是只使用推荐数据
每个用户生成固定数量的样本
丢弃搜索词的序列性
输入数据只使用历史信息
上面主要说一下怎么获取embedding几种方法,其实即使你模型构建好啦,来了一个人,你通过模型给他返回一个可推荐物品列表,返回topK个item,想过这个模型之后选取topK等等过程工业界是怎么实现的嘛
这个部分叫做服务serving,想想去饭店吃饭服务员怎么服务的,其实是一个道理,来一个用户你给他服务给他他最想看的几个物品
下面看一下这个部分的通用框架:

下面框图是一个参数服务器,说白啦就是一个集群,你把数据给它它分给好几个机器处理,最后汇总一下返回,优点就是大数据量的情况下可以加快速度
DB部分:考虑到这种实时的要求,会采用NoSQL存储系统:存储键值对文档,修改灵活;无join操作,操作简单,速度快
kv存储是NoSQL存储的一种,hbase:分布式、持久化、常用于大数据存储,redis:基于内存、速度快、常用于缓存
现在我接触到的存储:定时更新的库会是hbase、hive,如果涉及到实时的话更多的使用redis和ES
哈哈哈,我要去跑步啦,周末愉快~~~
参考:
1、http://net.pku.edu.cn/~cuibin/Papers/2015SIGMOD-tencentRec.pdf
2、https://www.cda.cn/uploadfile/image/20151220/20151220115436_46293.pdf
3、https://blog.csdn.net/huagong_adu/article/details/40710305
4、https://www.cnblogs.com/LeftNotEasy/archive/2011/01/19/svd-and-applications.html
5、https://datajobs.com/data-science-repo/Recommender-Systems-%5BNetflix%5D.pdf
8、https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf














 986
986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









