






 本文详细解读了MySQL数据库的优化策略,包括数据库级别(如表结构优化、索引使用、存储引擎选择)、硬件层面(如磁盘寻道、读写和内存带宽)以及性能与可移植性的平衡。同时介绍了InnoDB和MyISAM引擎的特点以及内存缓冲区的调优方法。
本文详细解读了MySQL数据库的优化策略,包括数据库级别(如表结构优化、索引使用、存储引擎选择)、硬件层面(如磁盘寻道、读写和内存带宽)以及性能与可移植性的平衡。同时介绍了InnoDB和MyISAM引擎的特点以及内存缓冲区的调优方法。
目录
官方文档解读
MySQL :: MySQL 8.3 Reference Manual :: 10.1 Optimization Overview https://dev.mysql.com/doc/refman/8.3/en/optimize-overview.html 根据MySQL官方网站的宏观指导,对于MySQL数据库的优化,可以概括为三个主要方面:数据库级别的优化,硬件层面的优化,以及性能与可移植性之间的平衡。
https://dev.mysql.com/doc/refman/8.3/en/optimize-overview.html 根据MySQL官方网站的宏观指导,对于MySQL数据库的优化,可以概括为三个主要方面:数据库级别的优化,硬件层面的优化,以及性能与可移植性之间的平衡。
一.数据库级别优化
数据库优化应遵循自顶向下的结构化数据库设计原则和方法。首先,开展全面的需求分析;随后,将需求分析成果细分为多个局部应用。通过绘制局部E-R图,展示每个局部应用中的实体、属性及其相互关系;最终,整合并优化这些E-R图,形成一个统一、精简的全局概念模型,以便全系统用户共同理解和接受。在全局概念模型的设计与优化过程中,我们会对现实世界中的实体和属性进行总结、归纳和提炼,形成最优的实体对象,为后续的数据库结构设计奠定坚实基础。
E-R图(实体-关系图)是用于描述现实世界信息结构的重要工具,但它并不直接适用于计算机处理。为了适应关系型数据库的处理需求,需要将E-R图转换成关系模式,即设计数据库中的表结构。
1.1 表结构优化
1. 规范化原则
在表结构的设计过程中,应遵循规范化原则,以提升数据的以下方面:
- 数据一致性:通过减少数据冗余,确保数据的统一性。
- 数据完整性:通过定义实体和关系的完整性约束,保证数据的准确性。
- 可维护性:规范化结构使得数据库的维护和扩展更加简便。
2. 完整性约束
设计关系模式时,需要定义以下类型的约束:
- 数据项约束:包括字段的数据类型、长度、是否允许为空等。
- 表级约束:如主键、唯一性约束等,确保表中数据的唯一性和有效性。
- 表间约束:如外键约束,维护表之间的关系和数据的引用完整性。
3. 视图外模式
此外,可以通过创建用户视图来实现数据的抽象,从而提供数据的安全性和独立性。视图可以限制用户只能访问特定的数据,同时保护底层表结构的变化不会影响到用户的操作。
4. 反规范化设计
最后,为了提升数据库的性能,可能对表会采取一些反规范化的设计。反规范化是在保证数据一致性和完整性的前提下,适当增加数据冗余,以减少查询时的表连接操作,从而提高查询效率。这种权衡是在规范化设计和性能优化之间找到平衡点。
1.2 列的数据类型优化
列的数据类型优化是数据库设计中的一个重要环节,它直接影响数据库的性能、存储空间和数据的准确性。以下是一些关于如何进行列数据类型优化的建议:
1. 选择合适的数据类型:
- 根据数据的实际用途选择最合适的数据类型。例如,对于存储年月的字段,可以使用
DATE类型而不是DATETIME。 - 对于整数类型,根据数值的范围选择
TINYINT、SMALLINT、MEDIUMINT、INT或BIGINT。 - 对于字符串,根据长度选择
CHAR(固定长度)或VARCHAR(可变长度)。
2.考虑数据的存储空间:
- 使用
VARCHAR而不是TEXT或BLOB,除非确实需要存储大量数据,因为TEXT和BLOB通常需要额外的存储和检索开销。 - 对于非常短的字符串,
CHAR可能比VARCHAR更高效,因为它不需要额外的长度字节。
3. 避免数据类型转换:
- 确保在比较或计算时字段的数据类型匹配,以避免数据库在查询时进行隐式数据类型转换。
4. 考虑数据的访问模式:
- 如果某个字段经常用于排序或分组,可以考虑使用索引来优化查询性能。
- 对于经常作为查询条件的字段,使用适当的数据类型可以提高查询的效率。
5. 使用整数代替字符串:
- 当可能时,使用整数代替字符串作为主键或其他索引字段,因为整数的比较比字符串更快。
6. 避免不必要的精度:
- 对于浮点数,根据需要选择
FLOAT、DOUBLE或DECIMAL,并指定合适的精度。过高的精度可能会导致性能下降。
7. 考虑时区和字符集:
- 对于
DATETIME和TIMESTAMP类型,根据应用的需求选择合适的时区处理。 - 为字符类型选择合适的字符集和排序规则,以支持国际化并优化性能。
1.3 正确使用索引功能
从以往工作经验来看,合理的创建索引可以大幅度提高数据库的查询效率,以下方案可以指导初学者如何正确使用索引功能。
1. 理解MySQL 索引类型
- 主键索引(PRIMARY):唯一且非空,通常用于唯一标识表中的每一行。
- 唯一索引 (UNIQUE):保证列中的所有值都是唯一的。
- 常规索引(INDEX):没有唯一性要求,用于提高查询性能。
- 全文索引 (ULLTEXT):用于全文搜索,适用于文本数据。
- 复合索引:跨越多个列的索引,可以提高涉及多个列的查询性能。遵循”最左前缀“原则。
2. 考虑InnoDB特有的索引特性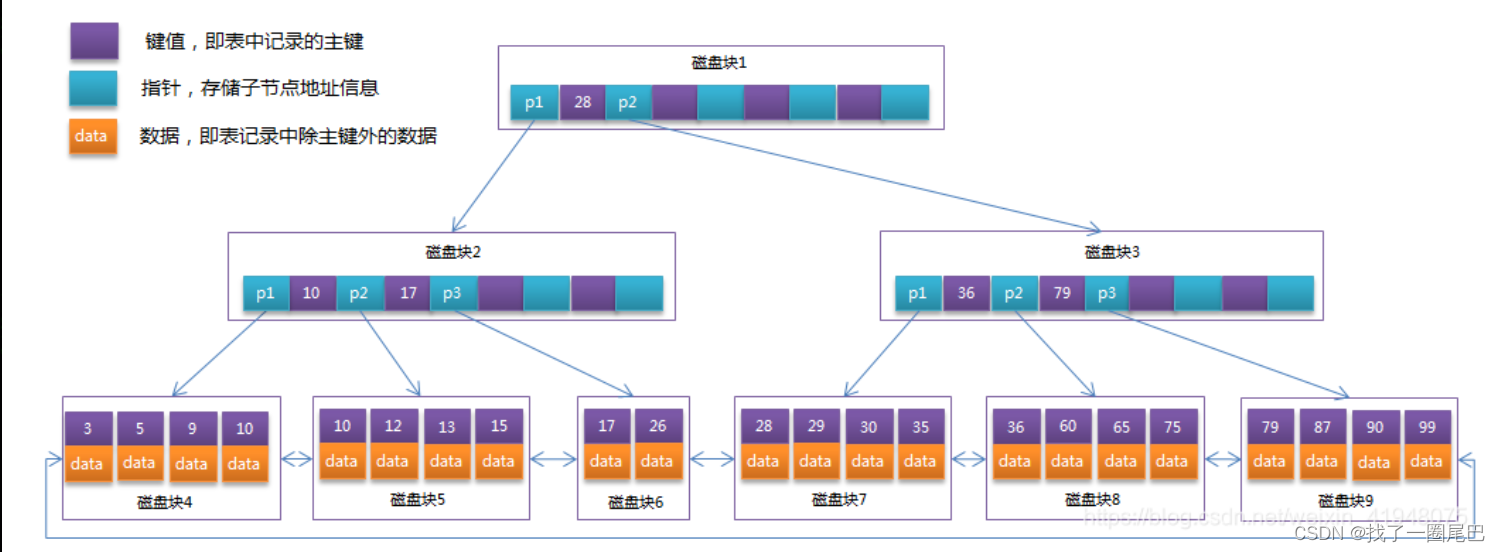
- InnoDB 采用 B+Tree 实现其索引结构,而其中的聚簇索引即主键索引为一级索引,其它索引为二级索引。一级索引结构的查询效率是最高的,所以一般情况下Mysql 表都包含唯一主键Id 作为聚簇索引,以提高使用id 的增删改查效率。
- InnoDB存储引擎会自动创建主键索引,因此建议每个表都有主键。
- InnoDB还会对辅助索引(非主键索引)包含主键列,这就是所谓的聚簇索引。
3. 选择合适的列创建索引
- 索引应该建立在经常作为查询条件的列上,如主键、外键、经常用于
JOIN操作的列、以及经常出现在WHERE子句、ORDER BY和GROUP BY的列。 - 高选择性的列(即具有大量唯一值的列)是创建索引的好候选,因为它们可以快速缩小查询的范围。
4. 避免过多索引
- 索引虽然可以提高查询速度,但也会增加写入操作的负担,因为每次写入操作都需要更新索引。因此,不要过度索引,只对经常查询的列创建索引。
5. 定期维护索引
- 定期使用
OPTIMIZE TABLE、ANALYZE TABLE等命令来维护表和索引。 - 监控索引的使用情况,对于不使用或很少使用的索引,可以考虑移除。
6. 使用 EXPLAIN 语句分析索引使用情况
- 很多情况下,数据库语句并不能如预期的正常使用了数据库的索引,为了保证我们建立的索引被正常使用,通常情况下我们使用 EXPLAIN 执行计划监控语句索引的使用情况。
- 当然,为了保证索引的正常使用,我们的SQL 语句需要设计的更加简洁,而避免复杂语句可能会造成的索引失效情况。
1.4 如何选择表使用的存储引擎
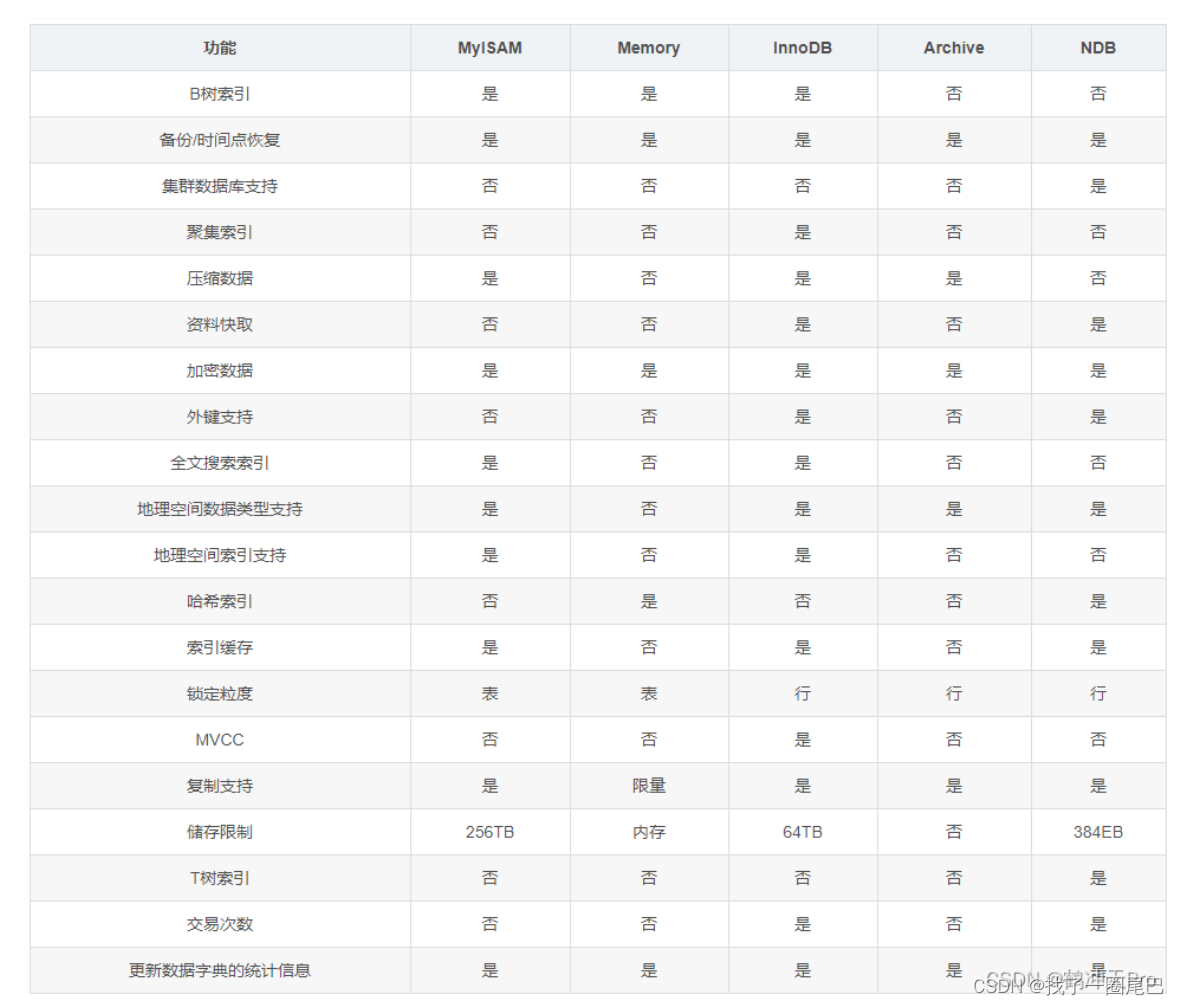
- InnoDB 支持事务,行级锁定和外键支持,因此有利于维护数据的一致性和完整性
- MyISAM存储引擎适用于读操作远多于写操作的场景,因为它不支持事务和行级锁,但读取速度快。同时MylSAM 对于全文搜索有着更好的支持
- Memory存储引擎将所有数据存储在内存中,适合于临时表和非持久化数据,但不适合大型数据集或需要持久化存储的场景。
- MySQL还提供了其他存储引擎,如Archive(用于存储大量不经常访问的历史数据)、CSV(以CSV格式存储数据,便于与外部程序交换数据)等,可以根据特定需求选择。
1.5 压缩表以减少磁盘I/O
1. 压缩表
1.1 OPTIMIZE 命令
OPTIMIZE TABLE your_table_name;
可以使用OPTIMIZE TABLE命令来压缩该表。这个命令会对表进行优化和压缩,清理碎片并恢复空间。优化表的操作可能需要一些时间,具体时间取决于表的大小和服务器的性能。
1.2 InnoDB 行压缩
对每行数据进行压缩。当插入或更新数据时,InnoDB会根据指定的压缩算法对数据进行压缩。行压缩适合于那些每行数据都有很多可压缩空间的场景。压缩和解压缩操作是在数据写入和读取时自动进行的,对用户透明。
···
CREATE TABLE my_table ( id INT PRIMARY KEY, name VARCHAR(50) ) ROW_FORMAT=COMPRESSED;
···
1.3 InnoDB 页压缩
InnoDB存储数据的基本单位是页(默认大小为16KB)。页压缩是对整个数据页进行压缩。如果一页中的数据有很多重复或者可压缩的部分,页压缩可以更有效地减少存储空间。页压缩同样是在数据写入和读取时自动进行的。
···
CREATE TABLE my_table ( id INT PRIMARY KEY, name VARCHAR(50) ) ROW_FORMAT=COMPACT KEY_BLOCK_SIZE=8;
···
压缩可以显著减少磁盘空间的使用,但同时也增加了CPU的使用,因为压缩和解压缩需要计算资源。因此,在使用压缩功能时,需要根据实际情况权衡CPU资源和存储空间资源。在实际应用中,是否使用压缩以及选择哪种压缩策略,需要根据数据库的实际负载、数据特性和硬件资源进行综合考虑
2. 重建表
重建表在一般情况下是一个万能的方式,能有效优化表使用的索引、表空间,修复表损坏等情况。mysql 可以使用 `alter table xxx engine = InnoDB` 命令重建表;
MySQL 5.6.6 引入 Online DDL,可以支持重建表时同时进行增删改查操作,大概流程如下:
1. 建立临时文件,扫描表主键的所有数据页;
2. 用数据页中表的记录生成B+树,存储到临时文件;
3. 生成临时文件的过程中,将这个期间对表的所有操作记录在 row log 的日志文件中;
4. 临时文件生成后,将日志中的操作应用到临时文件;
5. 临时文件替换原来的表数据文件;
alter 语句启动时获取到表的DDL写锁,在拷贝数据前退化为读锁,退化读锁后可以继续进行增删改查操作,不释放锁是为了禁止其他线程对该表进行DDL操作;
1.6 内存缓冲区域调优
1.6.1 InnoDB 缓冲池
配置方案
MySQL :: MySQL 8.3 Reference Manual :: 17.8.3.1 Configuring InnoDB Buffer Pool Sizehttps://dev.mysql.com/doc/refman/8.3/en/innodb-buffer-pool-resize.html innodb_buffer_pool_size 默认大小为128M, 官方推荐其配置为系统内存的 50% 到 75% 。
一般innodb_buffer_pool_size要结合以下两个参数来设置:
innodb_buffer_pool_chunk_size;innodb_buffer_pool_instances;
innodb_buffer_pool_size(我记为A)、innodb_buffer_pool_chunk_size(我记为B)、innodb_buffer_pool_instances (我记为C), N 为正整数;。
1、缓冲池(A)大小必须等于或者是 A x B 的整数倍: A = N(B x C)
2、否则将会自动调整为等于或者是 A x B 的倍数。
比如我一台 4C/8G 的服务器,可配置如下:
innodb_buffer_pool_chunk_size=128M
innodb_buffer_pool_instances=4
innodb_buffer_pool_size=4608M
(128 x 4) x N = ?
这个时候你就需要把大小控制在 8G 的 50%~75% 范围内即可,比如 N 取9,则最终值为4608。
注意事项:
1. innodb_buffer_pool_size为了避免潜在的性能问题,块 ( / ) 的数量innodb_buffer_pool_chunk_size不应超过 1000。
2. 缓冲池大小必须等于或倍数 innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances。更改这些变量设置需要重新启动服务器。
3. 如果在缓冲池调整大小操作开始后启动嵌套事务,则嵌套事务可能会失败。
配置InnoDB缓冲池预取(预读)
MySQL :: MySQL 8.3 Reference Manual :: 17.8.3.4 Configuring InnoDB Buffer Pool Prefetching (Read-Ahead)https://dev.mysql.com/doc/refman/8.3/en/innodb-performance-read_ahead.html 预读请求是异步预取缓冲池中的多个页面的 I/O 请求 ,以预测即将需要这些页面。这些请求将所有页面引入某一 范围内。 InnoDB使用两种预读算法来提高 I/O 性能:线性预读和随机预读。
1.6.2 MyISAM 密钥缓存
MyISAM密钥缓存(Key Cache)是指MySQL用于缓存MyISAM表索引块的内存区域。由于MyISAM表使用非聚集索引,索引和数据是分开存储的,因此索引的缓存对于提高查询性能至关重要。密钥缓存分为多个缓存组,每个缓存组可以独立地分配大小和策略。
在MySQL中,MyISAM密钥缓存默认分为两个部分:
- 热点密钥缓存(Hot Key Cache):也称为“主要密钥缓存”,用于存储频繁访问的索引块。
- 默认密钥缓存(Default Key Cache):用于存储其他索引块。
可以通过MySQL的配置文件(my.cnf或my.ini)或通过SQL命令来管理和配置MyISAM密钥缓存。例如,可以设置密钥缓存的大小、决定哪些索引应该被缓存,以及如何处理缓存的刷新和失效。
在配置文件中,可以设置如下参数来调整MyISAM密钥缓存:
[mysqld]
key_buffer_size = 128M # 设置密钥缓存的总大小
max_key_buffer_size = 256M # 设置密钥缓存的最大大小
此外,还可以使用SQL命令来管理密钥缓存,例如:
CACHE INDEX t1 IN hot_cache; # 将表t1的索引缓存到热点密钥缓存
FLUSH INDEXES; # 刷新所有密钥缓存
RESET INDEXES; # 清除所有密钥缓存二. 硬件层面优化
硬件层面的优化往往是 DBA 更应该考虑的内容,以服务器测试为基准,对磁盘寻道,磁盘读写,CPU 周期,内存宽带 进行并发性能检测,测试mysql 服务器是否存在硬件层面的瓶颈。
2.1 磁盘寻道
磁盘找到一条数据需要时间。对于现代磁盘,平均时间通常低于 10 毫秒,因此理论上我们每秒可以执行大约 100 次搜索。使用新磁盘时,时间改善缓慢,并且很难针对单个表进行优化。优化寻道时间的方法是将数据分布到多个磁盘上。
2.2 磁盘读写
磁盘读写。当磁盘处于正确的位置时,我们就需要读取或写入数据。对于现代磁盘,一个磁盘至少可提供 10–20MB/s 的吞吐量。这比查找更容易优化,因为您可以从多个磁盘并行读取。
2.3 CPU 周期
CPU 周期。当数据在主存中时,我们必须对其进行处理才能得到结果。与内存量相比,拥有较大的表是最常见的限制因素。但对于小表,速度通常不是问题。
2.4 内存带宽
当 CPU 需要的数据量超出了 CPU 缓存的容量时,主存带宽就会成为瓶颈。对于大多数系统来说,这是一个不常见的瓶颈,但需要注意。
三. 性能与可移植性的平衡
mysql 可以使用指定注解/*+ ... */来标识mysql 的优化器提示 Optimizer Hints。除了mysql 数据库,其他数据库系统并不识别该功能。由于hints 的复杂性高,有较强的版本依赖性以及可移植性不好,生产环境并不建议使用mysql 优化器提示功能。在大多数情况下,遵循最佳实践,如优化表结构、使用适当的索引、编写高效的查询,比依赖优化器提示更为可靠和有效。
想要了解具体的Mysql 优化器提示功能,可以参考官方文档给出的内容:


















 965
965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











