









目标地址:http://weixin.sogou.com/weixin?
这个地址是搜狗微信的文章搜索,可以搜索到微信的文章,而我们目标就是这些文章内容
这个url经过测试,当我们没登陆微信只能看到10页的内容,我们登陆后才可以查看100页的内容,
而且翻页多次会出现ip检测的反爬机制,出现302重新跳转到验证码输入页面,输入验证码后才可以继续浏览网页
于是我们就利用代理池来解决这个反爬。
首先搭建爬虫主题框架,因为是搜索类型的url,一般通过get请求,所以我们通过urlencode进行参数拼接,我这里查询的是query=python&type=2&page=1,type为1是搜索公众号,type为2是搜索微信文章。如果出现连接错误ConnectionError就重新抓取,主体完成。
from urllib.parse import urlencode
import requests
base_url = 'http://weixin.sogou.com/weixin?'
KEYWORD = 'python'
def get_html(url):
try:
response = requests.get(url)
if response.status == 200:
return response.text
except ConnectionError:
return get_html(url)
def get_index(keyword, page):
data = {
'query': keyword,
'type': 2,
'page': page
}
queries = urlencode(data)
url = base_url + queries
html = get_html(url)
print(html)
if '__name__' == '__main__':
get_index(KEYWORD, 1)其次,因为我们这里是抓取一页的搜索内容,所以没有出现302的状态,接下来我们要设置代理池,然后利用cookies抓取100页的内容。我用的代理池是https://github.com/Python3WebSpider/ProxyPool,免费但不稳定(凑合着用把),记得下载这个代理池后安装requirement时修改
redis==2.10.6否则会出现一些脏数据导致代理池出现问题。
代理池运行起来,通过http://localhost:5555/random可以获取代理ip,这样就不用担心封ip了。
增加headers的cookies信息以及获取代理。这里User-Agent最好设置成Chrome 67版本以下,否则会一直卡在302中
from requests.exceptions import ConnectionError
proxy = None
PROXY_POOL_URL = 'http://localhost:5555/random'
headers = {
'Cookie': 'SUV=00BC42EFDA11E2615BD9501783FF7490; CXID=62F139BEE160D023DCA77FFE46DF91D4; SUID=61E211DA4D238B0A5BDAB0B900055D85; ad=Yd1L5yllll2tbusclllllVeEkmUlllllT1Xywkllll9llllllZtll5@@@@@@@@@@; SNUID=A60850E83832BB84FAA2B6F438762A9E; IPLOC=CN4400; ld=Nlllllllll2tPpd8lllllVh9bTGlllllTLk@6yllll9llllljklll5@@@@@@@@@@; ABTEST=0|1552183166|v1; weixinIndexVisited=1; sct=1; ppinf=5|1552189565|1553399165|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZTo4OnRyaWFuZ2xlfGNydDoxMDoxNTUyMTg5NTY1fHJlZm5pY2s6ODp0cmlhbmdsZXx1c2VyaWQ6NDQ6bzl0Mmx1UHBWaElMOWYtYjBhNTNmWEEyY0RRWUB3ZWl4aW4uc29odS5jb218; pprdig=eKbU5eBV3EJe0dTpD9TJ9zQaC2Sq7rMxdIk7_8L7Auw0WcJRpE-AepJO7YGSnxk9K6iItnJuxRuhmAFJChGU84zYiQDMr08dIbTParlp32kHMtVFYV55MNF1rGsvFdPUP9wU-eLjl5bAr77Sahi6mDDozvBYjxOp1kfwkIVfRWA; sgid=12-39650667-AVyEiaH25LM0Xc0oS7saTeFQ; ppmdig=15522139360000003552a8b2e2dcbc238f5f9cc3bc460fd0; JSESSIONID=aaak4O9nDyOCAgPVQKZKw',
'Host': 'weixin.sogou.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.2987.133 Safari/537.36'
}
def get_proxy():
try:
response = requests.get(PROXY_POOL_URL)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None然后修改get_html方法,这里allow_redirects=False是设置不允许自动跳转,没有的话get请求会帮你自动跳转到输入验证码的页面。这里区分有用proxy和没有proxy的情况,因为我们一开始是通过自己的ip进行访问,如果出现302后才通过代理进行访问。然后增加对次数判断,如果请求多次的话就返回None,避免浪费过多资源(事实上好像最多出现Count=2时就能请求成功了)
MAX_COUNT = 5
def get_html(url, count=1):
print('Crawling', url)
print('Trying Count', count)
global proxy
if count >= MAX_COUNT:
print('Tried Too Many Counts')
return None
try:
if proxy:
proxies = {
'http': 'http://' + proxy
}
response = requests.get(url, allow_redirects=False, headers=headers, proxies=proxies)
else:
response = requests.get(url, allow_redirects=False, headers=headers)
if response.status_code == 200:
return response.text
if response.status_code == 302:
# Need Proxy
print('302')
proxy = get_proxy()
if proxy:
print('Using Proxy', proxy)
return get_html(url)
else:
print('Get Proxy Failed')
return None
except ConnectionError as e:
print('Error Occurred', e.args)
proxy = get_proxy()
count += 1
return get_html(url, count)
好了,现在已经获得100页的搜索内容了,也就是我们还需要点击文章连接进去然后进行文章内容爬取才行
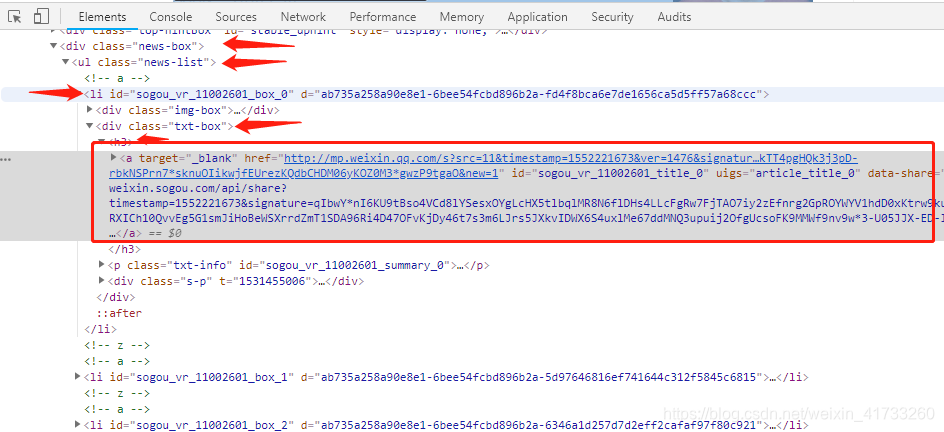
目标是这个<a>,我利用pyquery来进行抓取,yield生成href链接,顺便定义获取文章页面的get_detail,这里转到https://mp.weixin.qq.com,就不需要代理了。
from pyquery import PyQuery as pq
def parse_index(html):
doc = pq(html)
items = doc('.news-box .news-list li .txt-box h3 a').items()
for item in items:
yield item.attr('href')
def get_detail(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None再次分析文章页面的内容,我们想要的文章标题、作者、公众号、内容、发布时间。后面查看有些文章没有作者,只有公众号,所以把作者改为公众号的微信号
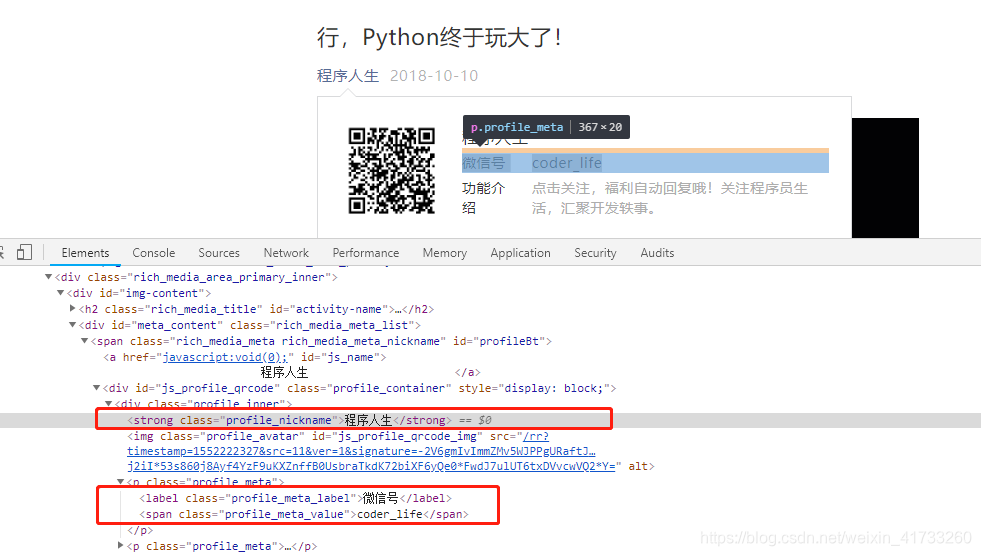
于是乎,写下parse_detail方法,而XMLSyntaxError是pyquery经常出现特殊字符导致匹配不成功,先把它加上。
from lxml.etree import XMLSyntaxError
def parse_detail(html):
try:
doc = pq(html)
title = doc('.rich_media_title').text()
content = doc('.rich_media_content').text()
date = doc('#publish_time').text()
nickname = doc('#js_profile_qrcode > div > strong').text()
wechat = doc('#js_profile_qrcode > div > p:nth-child(3) > span').text()
return {
'title': title,
'content': content,
'date': date,
'nickname': nickname,
'wechat': wechat
}
except XMLSyntaxError:
return None这样我们就获得了关于python的微信文章标题、内容、公众号、微信号、发布时间。这些数据还需要进行保存,用MongoDB保存简单粗暴
import pymongo
MONGO_URI = 'localhost'
MONGO_DB = 'weixin'
client = pymongo.MongoClient(MONGO_URI)
db = client[MONGO_DB]
def save_to_mongo(data):
if db['articles'].update({'title': data['title']}, {'$set': data}, True):
print('Saved to Mongo', data['title'])
else:
print('Saved to Mongo Failed', data['title'])重新写一下mian方法
def main():
for page in range(1, 101):
html = get_index(KEYWORD, page)
if html:
article_urls = parse_index(html)
for article_url in article_urls:
article_html = get_detail(article_url)
if article_html:
article_data = parse_detail(article_html)
print(article_data)
if article_data:
save_to_mongo(article_data)大功告成,到MongoDB中就可以查看爬取下来的内容了

接到同学反馈,说publish_time回来是空值,于是我查看了一下
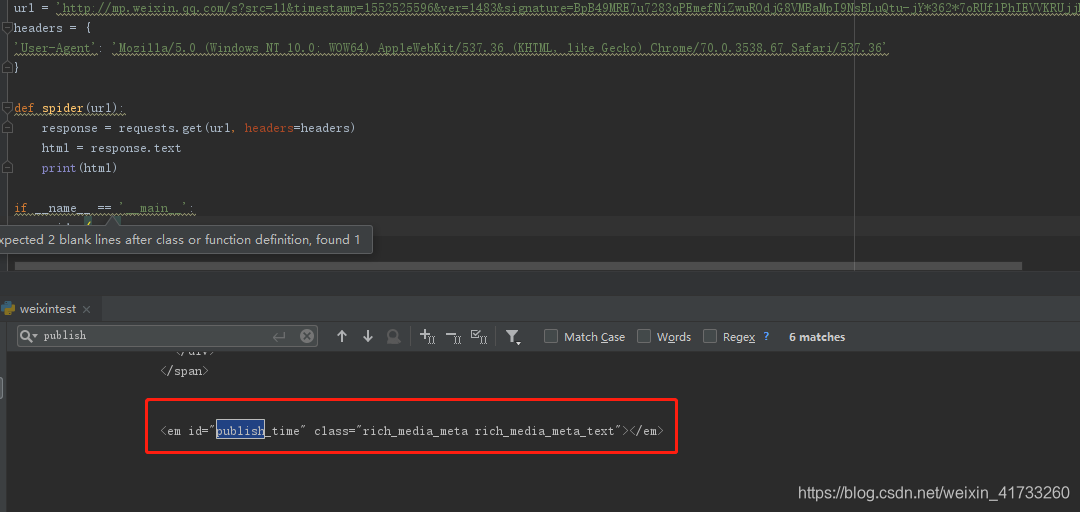
获得的时间确实没有东西,向下找发现是用了js传了值进来
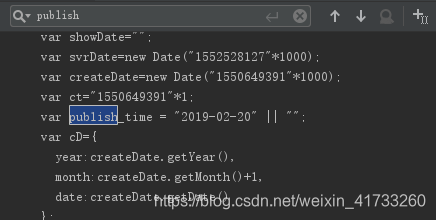
这样还是在requests返回的html中,于是利用re就可以将它匹配出来(bs和pq都只能匹配html或者xml标签)
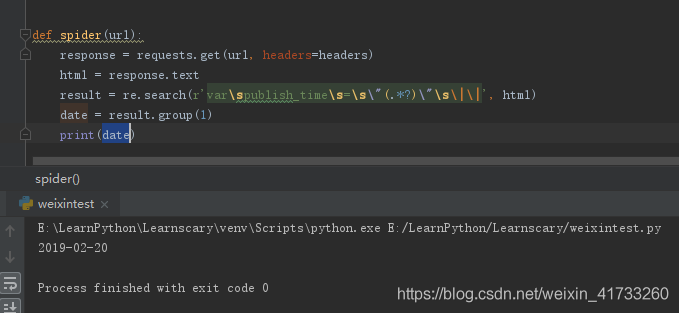
这样就可以了,能用search就不要用match
修改我们的parse_detail方法就可以获得时间了
from lxml.etree import XMLSyntaxError
import re
def parse_detail(html):
try:
doc = pq(html)
title = doc('.rich_media_title').text()
content = doc('.rich_media_content').text()
date = re.search(r'var\spublish_time\s=\s\"(.*?)\"\s\|\|', html).group(1)
nickname = doc('#js_profile_qrcode > div > strong').text()
wechat = doc('#js_profile_qrcode > div > p:nth-child(3) > span').text()
return {
'title': title,
'content': content,
'date': date,
'nickname': nickname,
'wechat': wechat
}
except XMLSyntaxError:
return None














 4832
4832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









