







传统KNN缺点:数据量特别大时,需要计算参考点和每个样本点的距离,计算量非常大,所以提出一种优化算法-----kd-tree.
为了提高kNN搜索的效率,可以考虑使用特殊的结构存储训练数据,以减小计算距离的次数。
kd树(K-dimension tree)是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是是一种二叉树,表示对k维空间的一个划分,构造kd树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一系列的K维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
-
构造kd-tree
输入:多维空间数据集
输出:kd树
(1)开始:构造根结点。选择X为切分坐标轴,以所有实例X坐标的中位数为切分点,将根结点对应的区域切分为左、右两个子区域。左子结点对应坐标小于切分点的子区域,右子结点对应于坐标大于切分点的子区域。将落在切分超平面上的实例点保存在根结点。
(2)重复。对左右子区域,轮换切分坐标轴,继续以坐标轴对应坐标的中位数为切分点。直到所有的点都切分完毕。
举个简单的例子:
例. 给定一个二维空间数据集{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},构造一个平衡kd树。
解:根结点对应包含数据集T的矩形,选择轴,6个数据点的坐标中位数是6,这里选最接近的(7,2)点,以平面将空间分为左、右两个子矩形(子结点);接着左矩形以分为两个子矩形(左矩形中{(2,3),(5,4),(4,7)}点的坐标中位数正好为4),右矩形以分为两个子矩形,如此递归,最后得到如下图所示的特征空间划分和kd树。
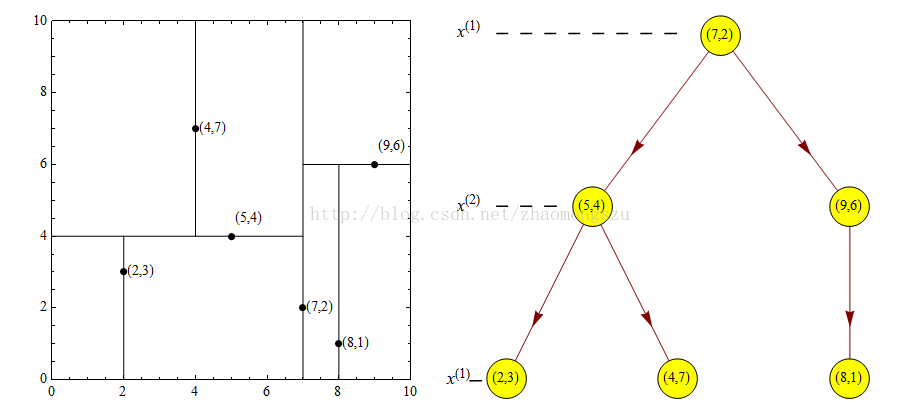
-
搜索kd树
利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。下面以搜索最近邻点为例加以叙述:给定一个目标点,搜索其最近邻,首先找到包含目标点的叶节点;然后从该叶结点出发,依次回退到父结点;不断查找与目标点最近邻的结点,当确定不可能存在更近的结点时终止。这样搜索就被限制在空间的局部区域上,效率大为提高。
用kd树的最近邻搜索:
输入: 已构造的kd树;目标点;
输出:最近邻。
(1) 在kd树中找出包含目标点的叶结点:从根结点出发,递归的向下访问kd树。若目标点当前维的坐标值小于切分点的坐标值,则移动到左子结点,否则移动到右子结点。直到子结点为叶结点为止;
(2) 以此叶结点为“当前最近点”;
(3) 递归的向上回退,在每个结点进行以下操作:
(a) 如果该结点保存的实例点比当前最近点距目标点更近,则以该实例点为“当前最近点”;
(b) 当前最近点一定存在于该结点一个子结点对应的区域。检查该子结点的父结点的另一个子结点对应的区域是否有更近的点。具体的,检查另一个子结点对应的区域是否与以目标点为球心、以目标点与“当前最近点”间的距离为半径的超球体相交。如果相交,可能在另一个子结点对应的区域内存在距离目标更近的点,移动到另一个子结点。接着,递归的进行最近邻搜索。如果不相交,向上回退。
(4) 当回退到根结点时,搜索结束。最后的“当前最近点”即为的最近邻点。
注意:这里的搜索,也是跟上边构造一样,首先先搜索x(1),再搜索x(2)..以此类推下去。
以先前构建好的kd树为例,查找目标点(3,4.5)的最近邻点。同样先进行二叉查找,先从(7,2)查找到(5,4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径:(7,2)→(5,4)→(4,7),取(4,7)为当前最近邻点。以目标查找点为圆心,目标查找点到当前最近点的距离2.69为半径确定一个红色的圆。然后回溯到(5,4),计算其与查找点之间的距离为2.06,则该结点比当前最近点距目标点更近,以(5,4)为当前最近点。用同样的方法再次确定一个绿色的圆,可见该圆和y = 4超平面相交,所以需要进入(5,4)结点的另一个子空间进行查找。(2,3)结点与目标点距离为1.8,比当前最近点要更近,所以最近邻点更新为(2,3),最近距离更新为1.8,同样可以确定一个蓝色的圆。接着根据规则回退到根结点(7,2),蓝色圆与x=7的超平面不相交,因此不用进入(7,2)的右子空间进行查找。至此,搜索路径回溯完,返回最近邻点(2,3),最近距离1.8。
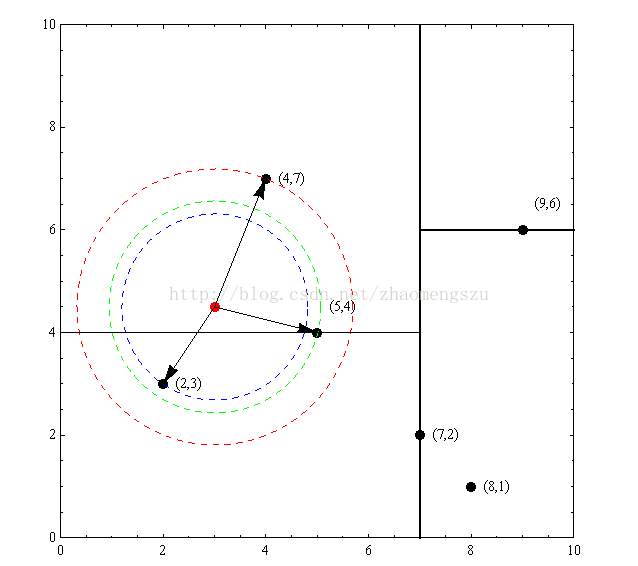
kd-tree的几个问题:
1.如何决定每次根据哪个维度对子空间进行划分呢?
- 直观的来看,我们一般会选择轮流来。先根据第一维,然后是第二维,然后第三……,那么到底轮流来行不行呢,这就要回到最开始我们为什么要研究选择哪一维进行划分的问题。我们研究Kd-Tree是为了优化在一堆数据中高频查找的速度,用树的形式,也是为了尽快的缩小检索范围,所以这个“比对维”就很关键,通常来说,更为分散的维度,我们就更容易的将其分开,是以这里我们通过求方差,用方差最大的维度来进行划分——这也就是最大方差法(max invarince)。
2.如何选定根节点的比对数值呢?
- 选择何值未比对值,目的也是为了要加快检索速度。一般来说我们在构造一个二叉树的时候,当然是希望它是一棵尽量平衡的树,即左右子树中的结点个数相差不大。所以这里用当前维度的中值是比较合理的。














 2936
2936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









