







使用sklearn.preprocessing.PolynomialFeatures来进行特征的构造。
它是使用多项式的方法来进行的,如果有a,b两个特征,那么它的2次多项式为(1,a,b,a^2,ab, b^2)。
PolynomialFeatures有三个参数
degree:控制多项式的度
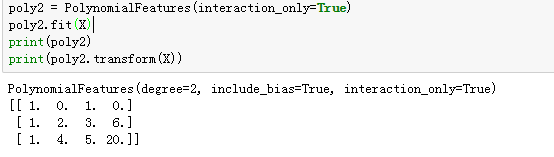
interaction_only: 默认为False,如果指定为True,那么就不会有特征自己和自己结合的项,上面的二次项中没有a^2和b^2。
include_bias:默认为True。如果为True的话,那么就会有上面的 1那一项。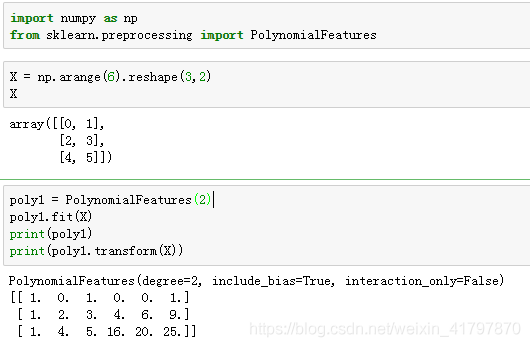
## GBDT+LR
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.preprocessing import OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve,auc
# 弱分类器的数目
n_estimator = 10
# 随机生成分类数据。
X, y = make_classification(n_samples=80000)
# 切分为测试集和训练集,比例0.5
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)
# 将训练集切分为两部分,一部分用于训练GBDT模型,另一部分输入到训练好的GBDT模型生成GBDT特征,然后作为LR的特征。这样分成两部分是为了防止过拟合。
X_train, X_train_lr, y_train, y_train_lr = train_test_split(X_train, y_train, test_size=0.5)
# 调用GBDT分类模型。
grd = GradientBoostingClassifier(n_estimators=n_estimator)
# 调用one-hot编码。
grd_enc = OneHotEncoder()
# 调用LR分类模型。
grd_lm = LogisticRegression()
'''使用X_train训练GBDT模型,后面用此模型构造特征'''
grd.fit(X_train, y_train)
# fit one-hot编码器
# grd.apply方法给定的是:样本在算法中落在第几个叶子上,在GBDT中该方法返回的格式为: [n_samples, n_estimator, n_classes]
grd_enc.fit(grd.apply(X_train)[:, :, 0])
'''
使用训练好的GBDT模型构建特征,然后将特征经过one-hot编码作为新的特征输入到LR模型训练。
'''
grd_lm.fit(grd_enc.transform(grd.apply(X_train_lr)[:, :, 0]), y_train_lr)
# 用训练好的LR模型多X_test做预测
y_pred_grd_lm = grd_lm.predict_proba(grd_enc.transform(grd.apply(X_test)[:, :, 0]))[:, 1]
# 根据预测结果输出
fpr_grd_lm, tpr_grd_lm, _ = roc_curve(y_test, y_pred_grd_lm)
print("AUC:{}".format(auc(fpr_grd_lm, tpr_grd_lm)))















 2816
2816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









