







有部分是转自 https://blog.csdn.net/lzm1340458776/article/details/43231707
hive distribute by 和group by 的区别:
group by是对检索结果的保留行进行单纯分组,一般总爱和聚合函数一块用例如AVG(),COUNT(),max(),main()等一块用。
group by操作表示按照某些字段的值进行分组,有相同的值放到一起,语法样例如下:
- select col1,col2,count(1),sel_expr(聚合操作)
- from tableName
- where condition
- group by col1,col2
- having...
(1):select后面的非聚合列必须出现在group by中(如上面的col1和col2)。
(2):除了普通列就是一些聚合操作。
group的特性:
(1):使用了reduce操作,受限于reduce数量,通过参数mapred.reduce.tasks设置reduce个数。
(2):输出文件个数与reduce数量相同,文件大小与reduce处理的数量有关。
问题:
(1):网络负载过重。
(2):出现数据倾斜(我们可以通过hive.groupby.skewindata参数来优化数据倾斜的问题)。
下面我们通过一些语句来深入体会group by相关的操作:
- insert overwrite table pv_gender_sum
- select pv_users.gender count(distinct pv_users.userid)
- from pv_users
- group by pv_users.gender;
在select语句中可以有多个聚合操作,但是如果多个聚合操作中同时使用了distinct去重,那么distinct去重的列必须相同,如下语句不合法:
- insert overwrite table pv_gender_agg
- select pv_users.gender,count(distinct pv_users.userid),count(distinct pv_users.ip)
- from pv_users
- group by pv_users.gender;
对上述非法语句做如下修改及将distinct的类改为一致就正确:
- insert overwrite table pv_gender_agg
- select pv_users.gender,count(distinct pv_users.userid),count(distinct pv_users.userid)
- from pv_users
- group by pv_users.gender;
还有一个要注意的就是文章开头所说的知识点即select后面的非聚合列必须出现在group by中,否则非法,如下:
- select uid,name,count(sal)
- from users
- group by uid;
修改上述语句即将name也加到group by后面。
- select uid,name,count(sal)
- from users
- group by uid,name;
下面我们来看看一些优化的属性:
(1):Reduce的个数设置
设置reduce的数量:mapred.reduce.tasks,默认为1个,如下图:
当将reduce的个数设置为3个的时候,如下:
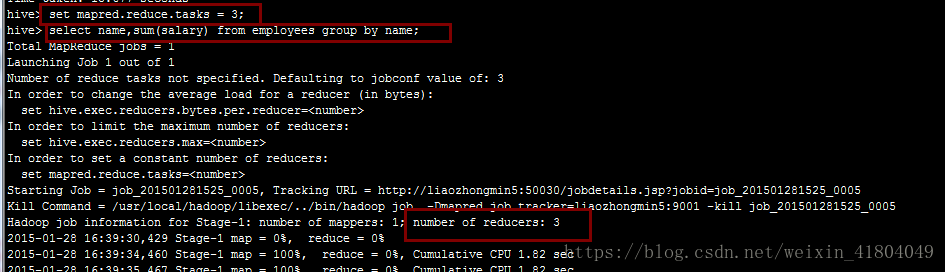
(2):group by的Map端聚合
hive.map.aggr控制如何聚合,我使用的版本是0.90,默认是开启的即为true,这个时候Hive会在Map端做第一级的聚合。这通常提供更好的效果,但是要求更多的内存才能运行效果。
- hive>
- hive> set hive.map.aggr=true;
- hive> select count(1) from employees;
(3):数据倾斜
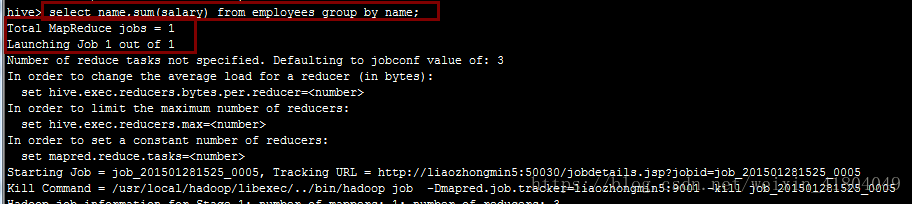
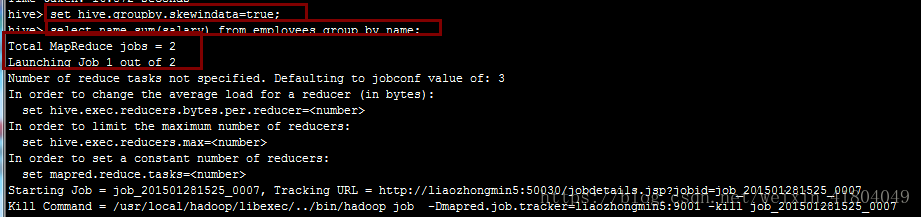
hive.groupby.skewdata属性设定是否在数据分布不均衡,即发生倾斜时进行负载均衡,当选项hive.groupby.skewdata=true时,生成的查询计划会有两个MapReduce即产生两个Job,在第一个MapReduce中,Map的输出结果会随机的分布到不同的Reduce中,对Reduce做部分聚合操作并输出结果,此时相同的group by key有可能分发到不同的reduce中,从而达到负载均衡的目的,第二个MapReduce任务根据预处理的数据按照group by key分布到Reduce中(此时Key相同就分布到同一个Reduce中),最后完成聚合操作。
参数设置前只启动了一个Job,如下图:
参数设置前只启动了两个Job,如下图:
distribute by是控制在map端如何拆分数据给reduce端的。hive会根据distribute by后面列,对应reduce的个数进行分发,默认是采用hash算法。sort by为每个reduce产生一个排序文件。在有些情况下,你需要控制某个特定行应该到哪个reducer,这通常是为了进行后续的聚集操作。distribute by刚好可以做这件事。因此,distribute by经常和sort by配合使用。
注:Distribute by和sort by的使用场景
1.Map输出的文件大小不均。
2.Reduce输出文件大小不均。
3.小文件过多。
4.文件超大。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









