







零、CNN常用命令
- 卷积
tf.nn.conv2d(input[batch,h,w,c],filter[h,w,c,out],strides=[1,h,w,1],padding='SAME'/'VALID',use_cudnn_on_gpu=None,data_format=None,name=None)有关参数详细说明,见:https://blog.csdn.net/xierhacker/article/details/53174594
- 采样
tf.nn.max_pooltf.nn.avg_pool(value[batch,h,w,c], ksize[1,h,w,1], strides=[1,dh,dw,1], padding='SAME'/'VALID', data_format=’NHWC’, name=None)
- 非线性
tf.nn.relu(z)- 全连层
tf.nn.relu_layer(input_op,kernel,biases,name=scope)
tf.nn.relu(tf.add(tf.matmul(current,kernels),bias))- softmax
tf.nn.softmax- 损失
tf.nn.l2_loss- 非线性
tf.nn.relu
- 其他
tf.nn.bias_add(conv,biases)
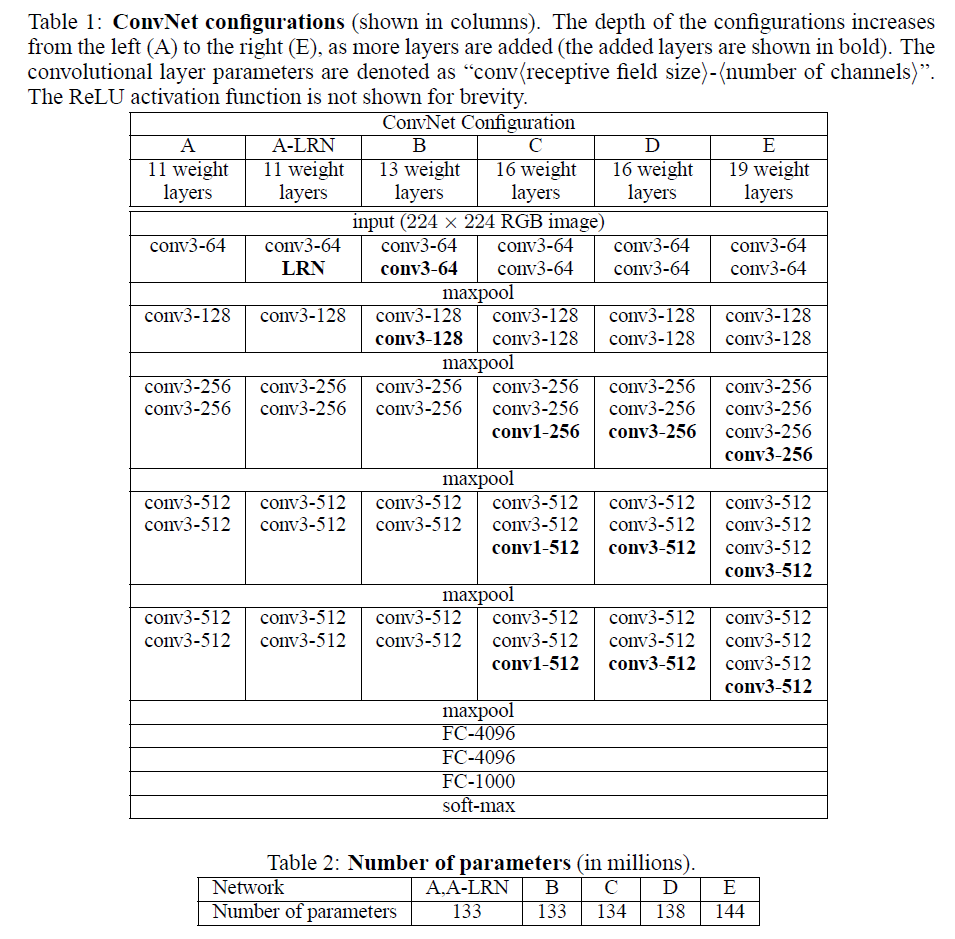
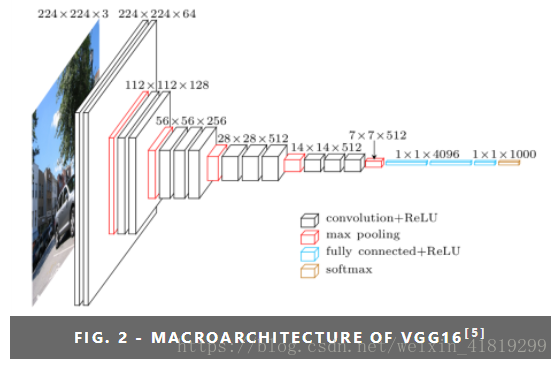
一、VGG16模型
二、VGG网络常见问题
-
卷积后尺寸计算
w‘=(w - kernel_size + 2*padding)/stride +1
举个例子:224*224*3的图片经过第一层conv3-64 ,kernel_size=3,stride=1,pad=1,每个卷积核是3*3*3通道的,共有64个卷积核
w'=h’=(224-3+2*1)/1+1=224
卷积后的大小为224*224*64
结论:用kernel_size=3,stride=1,pad=1进行卷积,卷积后长宽不变,通道数看卷积核数量
-
各层尺寸和参数数量
由table2可知:vgg16的参数量在138M(138344128),vgg19的参数量在144M。vgg16各层参数及像素值计算如下:
输入图:224*224*3
1)CONV3-64
尺寸:224*224*64
参数:3*3*3*64
2)CONV3-64
尺寸:224*224*64
参数:3*3*64*64
)MAXPOOL
尺寸:112*112*64
参数:0
3)CONV3-128
尺寸:112*112*128
参数:3*3*64*128
4)CONV3-128
尺寸:112*112*128
参数:3*3*128*128
)MAXPOOL
尺寸:56*56*128
参数:0
5)CONV3-256
尺寸:56*56*256
参数:3*3*128*256
6)CONV3-256
尺寸:56*56*256
参数:3*3*256*256
7)CONV3-256
尺寸:56*56*256
参数:3*3*256*256
)MAXPOOL
尺寸:28*28*256
参数:0
8)CONV3-512
尺寸:28*28*512
参数:3*3*256*512
9)CONV3-512
尺寸:28*28*512
参数:3*3*512*512
10)CONV3-512
尺寸:28*28*512
参数:3*3*512*512
)MAXPOOL
尺寸:14*14*512
参数:0
11)CONV3-512
尺寸:14*14*512
参数:3*3*512*512
12)CONV3-512
尺寸:14*14*512
参数:3*3*512*512
13)CONV3-512
尺寸:14*14*512
参数:3*3*512*512
)MAXPOOL
尺寸:7*7*512
参数:0
14)FC-4096
尺寸:1*1*4096
参数:7*7*512*4096
15)FC-4096
尺寸:1*1*4096
参数:4096*4096
16)FC-1000
尺寸:1*1*1000
参数:4096*1000
)soft-max
-
单层时间复杂度大小
以224*224*3通过conv3-64为例:
输出为224*224*64
该卷积层的时间复杂度为Time~O(3*3*3*224*224*64)
对卷积层来说Time~O(输出featuremap长*输出featuremap宽*卷积核长*卷积核宽*输入通道数*输出通道数)
以最后两层FC-4096——FC-1000为例:
Time~O(1*1*4096*1*1*1000)
-
模型内存大小
>500MB
通过参数计算:有138M参数,138M(个参数)*32位(float32)=4416M位 8位(bit)等于1B(字节) 4416M位 ≈552MB
-
计算量
15300M 或称 15300百万

-
模型压缩思路
-
感受野
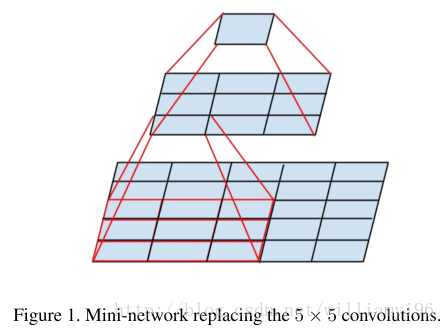
如上图所示:两个3x3的卷积层连在一起可视为5x5的filter(即感受野一样),三个连在一起可视为一个7x7的。
优点:和大卷积核相比:(1)可以减少参数(2)更深,进行了更多的非线性映射,增加网络的拟合、表达能力。
缺点:和Alexnet 相比,参数量大,模型内存大,计算量大
-
RELU1_1什么意思
relu线性整流层,一般会将VGG网络按照池化层分为几段:
layers = (
'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1',
'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2',
'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3',
'relu3_3', 'conv3_4', 'relu3_4', 'pool3',
'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'conv4_3',
'relu4_3', 'conv4_4', 'relu4_4', 'pool4',
'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'conv5_3',
'relu5_3', 'conv5_4', 'relu5_4'
)relu1_1就是第一段的第一层卷积层的输出做的非线性输出
三、代码
from datetime import datetime
import tensorflow as tf
import math
import time
batch_size = 32
num_batches = 100
# 用来创建卷积层并把本层的参数存入参数列表
# input_op:输入的tensor name:该层的名称 kh:卷积层的高 kw:卷积层的宽 n_out:输出通道数,dh:步长的高 dw:步长的宽,p是参数列表
def conv_op(input_op,name,kh,kw,n_out,dh,dw,p):
n_in = input_op.get_shape()[-1].value#[b,,w,c]----c
with tf.name_scope(name) as scope:
kernel = tf.get_variable(scope + "w",shape=[kh,kw,n_in,n_out],dtype=tf.float32,initializer=tf.contrib.layers.xavier_initializer_conv2d())#获取一个已经存在的变量或者创建一个新的变量
conv = tf.nn.conv2d(input_op, kernel, (1,dh,dw,1),padding='SAME')
bias_init_val = tf.constant(0.0, shape=[n_out],dtype=tf.float32)
biases = tf.Variable(bias_init_val , trainable=True , name='b')
z = tf.nn.bias_add(conv,biases)
activation = tf.nn.relu(z,name=scope)
p += [kernel,biases]
return activation
# 定义全连接层
def fc_op(input_op,name,n_out,p):
n_in = input_op.get_shape()[-1].value
with tf.name_scope(name) as scope:
kernel = tf.get_variable(scope+'w',shape=[n_in,n_out],dtype=tf.float32,initializer=tf.contrib.layers.xavier_initializer_conv2d())
biases = tf.Variable(tf.constant(0.1,shape=[n_out],dtype=tf.float32),name='b')
# tf.nn.relu_layer()用来对输入变量input_op与kernel做乘法并且加上偏置b
activation = tf.nn.relu_layer(input_op,kernel,biases,name=scope)
p += [kernel,biases]
return activation
# 定义最大池化层
def mpool_op(input_op,name,kh,kw,dh,dw):
return tf.nn.max_pool(input_op,ksize=[1,kh,kw,1],strides=[1,dh,dw,1],padding='SAME',name=name)
#定义网络结构
def inference_op(input_op,keep_prob):
p = []
conv1_1 = conv_op(input_op,name='conv1_1',kh=3,kw=3,n_out=64,dh=1,dw=1,p=p)
conv1_2 = conv_op(conv1_1,name='conv1_2',kh=3,kw=3,n_out=64,dh=1,dw=1,p=p)
pool1 = mpool_op(conv1_2,name='pool1',kh=2,kw=2,dw=2,dh=2)
conv2_1 = conv_op(pool1,name='conv2_1',kh=3,kw=3,n_out=128,dh=1,dw=1,p=p)
conv2_2 = conv_op(conv2_1,name='conv2_2',kh=3,kw=3,n_out=128,dh=1,dw=1,p=p)
pool2 = mpool_op(conv2_2, name='pool2', kh=2, kw=2, dw=2, dh=2)
conv3_1 = conv_op(pool2, name='conv3_1', kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
conv3_2 = conv_op(conv3_1, name='conv3_2', kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
conv3_3 = conv_op(conv3_2, name='conv3_3', kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
pool3 = mpool_op(conv3_3, name='pool3', kh=2, kw=2, dw=2, dh=2)
conv4_1 = conv_op(pool3, name='conv4_1', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
conv4_2 = conv_op(conv4_1, name='conv4_2', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
conv4_3 = conv_op(conv4_2, name='conv4_3', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
pool4 = mpool_op(conv4_3, name='pool4', kh=2, kw=2, dw=2, dh=2)
conv5_1 = conv_op(pool4, name='conv5_1', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
conv5_2 = conv_op(conv5_1, name='conv5_2', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
conv5_3 = conv_op(conv5_2, name='conv5_3', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
pool5 = mpool_op(conv5_3, name='pool5', kh=2, kw=2, dw=2, dh=2)
#先把relu5_3最大池化后的输出展开成二维的,再按照全连网络的形式构建全连接层
shp = pool5.get_shape()
flattened_shape = shp[1].value * shp[2].value * shp[3].value
resh1 = tf.reshape(pool5,[-1,flattened_shape],name="resh1")#7*7*512=25088
fc6 = fc_op(resh1,name="fc6",n_out=4096,p=p)
fc6_drop = tf.nn.dropout(fc6,keep_prob,name='fc6_drop')
fc7 = fc_op(fc6_drop,name="fc7",n_out=4096,p=p)
fc7_drop = tf.nn.dropout(fc7,keep_prob,name="fc7_drop")
fc8 = fc_op(fc7_drop,name="fc8",n_out=1000,p=p)
softmax = tf.nn.softmax(fc8)
predictions = tf.argmax(softmax,1)
return predictions,softmax,fc8,p
def time_tensorflow_run(session,target,feed,info_string):
num_steps_burn_in = 10 # 预热轮数
total_duration = 0.0 # 总时间
total_duration_squared = 0.0 # 总时间的平方和用以计算方差
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target,feed_dict=feed)
duration = time.time() - start_time
if i >= num_steps_burn_in: # 只考虑预热轮数之后的时间
if not i % 10:
print('%s:step %d,duration = %.3f' % (datetime.now(), i - num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches # 平均每个batch的时间
vr = total_duration_squared / num_batches - mn * mn # 方差
sd = math.sqrt(vr) # 标准差
print('%s: %s across %d steps, %.3f +/- %.3f sec/batch' % (datetime.now(), info_string, num_batches, mn, sd))
def run_benchmark():
with tf.Graph().as_default():
image_size = 224 # 输入图像尺寸
images = tf.Variable(tf.random_normal([batch_size, image_size, image_size, 3], dtype=tf.float32, stddev=1e-1))
keep_prob = tf.placeholder(tf.float32)
prediction,softmax,fc8,p = inference_op(images,keep_prob)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
time_tensorflow_run(sess, prediction,{keep_prob:1.0}, "Forward")
# 用以模拟训练的过程
objective = tf.nn.l2_loss(fc8) # 给一个loss,output = sum(t**2)/2
grad = tf.gradients(objective, p) # 参数一对参数二的求导
time_tensorflow_run(sess, grad, {keep_prob:0.5},"Forward-backward")
run_benchmark()
参考文献:
https://blog.csdn.net/zhangwei15hh/article/details/78417789
https://blog.csdn.net/qq_28739605/article/details/80320766














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









