







转载:https://blog.csdn.net/qq_43664324/article/details/106259046
写在前面:很多人说成是2的倍数,那不就是偶数了?可不是这个意思
对HashMap有了解的人都知道,HashMap默认维护的数组大小是1 << 4,也就是2^4,也就是16。
当我们创建一个HashMap对象的时候,如果我们指定了容量大小,但是却不是2^n,那底层也会帮我们进行处理,源码:
/**
* 有参构造,参数为自定义容量大小
*/
public HashMap(int initialCapacity) {
// 调用了重载方法,用了默认的负载因子
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* 上面调用的重载方法
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
// 此方法用来将我们输入的大小处理为2的n次幂
this.threshold = tableSizeFor(initialCapacity);
}
/**
* 将我们输入的大小处理为2的n次幂
* 例如:
* 输入15,则为16
* 输入17,则为32
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
原因就是底层计算元素在数组中位置的算法所致。
1.首先计算key的hash值(不是单纯的调用key的hashCode方法)
2.hash值和(数组空间大小 - 1)做位与运算,计算元素在数组中的索引。
代码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
。。。。。。。。。。
}
。。。。。。。。
}
key的hash值是很长的一个数字串,要想让这个hash值跟数组索引发生关系,直接能想到的方法就是hash值跟数组大小做取模运算,例如:
hash值为:1642360923
数组大小为:16
数组的索引是0到15,那么要想得出一个0到15的值,就做个取模运算,也就是小学时候学的求余数的运算,1642360923跟16求余数,要是整除了就是0,不整除,那么余数就是1到15,也就是这个取模操作我们可以得到0到15之间的数字,正好满足索引位置。
但是,这也引出了一个问题,hash碰撞。
数组的空间大小有范围,所以总会有两个不同的hash取模的索引却是一样的,这就是碰撞。
HashMap计算hash的时候并不是单纯的调用key的hashCode方法,因为jdk程序员不相信咱们,认为咱们的hashCode方法得出的hash值可能不够标准,它做了一顿骚操作,就是让得出的hash值尽量标准。
人家HashMap并没有用这么简单的取模算法,它是用了位与运算,用hash值跟数组大小减一做&,例如:1642360923 & (16 - 1)。
这种算法同样能达到取模那种效果,而且二进制的位运算,速度快。
与运算的特点,两个二进制数,有一位是0,那么得到的数就是0,例如:
二进制A:11111001
二进制B:10000111
那么结果就是:10000001
问题就出在这儿了,因为hash值是不固定的,所以说key的hash值的二进制数任何位都可能是0也可能是1,那么要想保证尽量减少hash碰撞,而且充分占据每个数组的位置,必须要保证(数组大小-1)的二进制全是1,例如(16-1)的二进制是1111。这样的话,就能保证最后的运算结果,完全取决于hash的二进制数,也就是最后的结果会保证每个位都有可能是0或1。
而一个十进制数,它是个2的n次幂的数,那么它减一后的二进制数就都是1,例如:
16: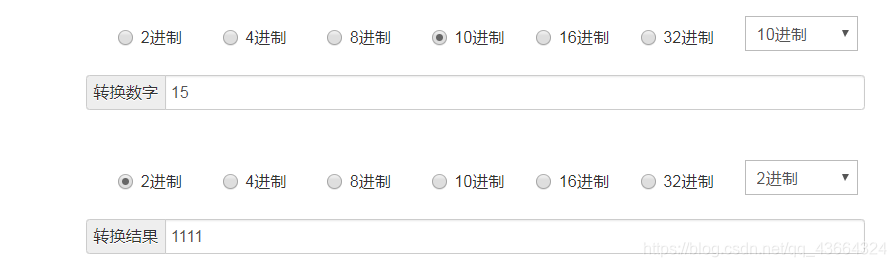
32: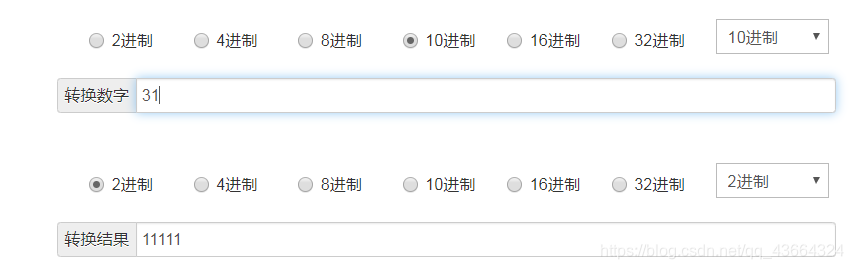
反方向想,要是我的空间大小是15,那么减一是14,二进制是: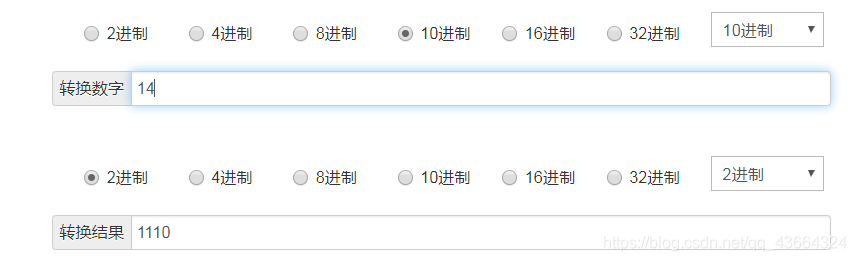
hash值假设是1642360923 ,二进制是:
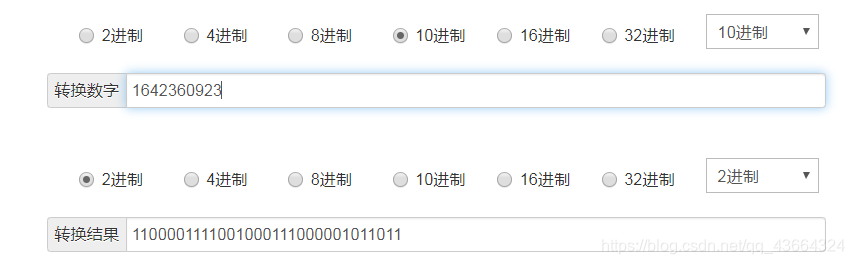
做位与运算:
结果是1010。
你会发现,不管hash的二进制数的最后一位是0还是1,最后一位的结果都会是0,永远得不到1,那么转换为10进制的时候,总会有至少一个数组的索引数字得不到,也就是数组中永远都有一个位置空着,而其他的位置可能都以链表的或平衡二叉树的结构挂了一坨。。。。
所以,为了保证结果的散列性,保证数组的位置充分利用,必须保证(空间大小-1)的二进制都是1,那样得到的结果才全面。
首尾呼应:那些说大小是2的倍数的注意了,就算你是个偶数,比如说12,那么12-1=11,11的二进制是1011,并不符合设计














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









