









本文介绍『文心大模型』的一项最新工作:“地理位置-语言”预训练模型 ERNIE-GeoL。
-
论文链接:
https://arxiv.org/abs/2203.09127
实践中的观察
近年来,预训练模型在自然语言处理、视觉等多个领域都取得了显著效果。基于预训练模型,利用特定任务的标注样本进行模型微调,通常可以在下游任务取得非常好的效果。
然而,通用的预训练语言模型在应用于地图业务(如 POI 检索、POI 推荐、POI 信息处理等)时的边际效应愈发明显,即随着预训练语言模型的优化,其在地图业务中所带来的提升效果越来越小。
其中一个主要原因是地理领域的信息处理过程往往需要与现实世界的真实地理信息建立关联。例如,在地图 POI 搜索引擎中,当用户输入一个 query 时,除了文本和语义匹配,候选 POI 的位置,以及它与用户当前所在位置的距离,都是非常重要的排序特征。而目前通用的预训练语言模型则缺乏可以建立『地理位置-语言』之间关联的训练数据以及预训练任务。
我们的创新
地理预训练模型 ERNIE-GeoL
NLP 预训练模型(如 ERNIE 3.0)主要聚焦于语言类任务建模,跨模态预训练模型(如 ERNIE-ViL)主要侧重于『视觉-语言』类任务建模。为了更好地学习『地理位置-语言』之间的关联,我们提出了地理预训练模型 ERNIE-GeoL(Geo-Linguistic),主要聚焦于『地理位置-语言』类任务建模。
为了训练 ERNIE-GeoL,我们引入了两类地理知识来增强预训练模型效果。
-
第一类为地名知识,地名(toponym)主要指地理实体(如 POI、街道和地区)的名称。
-
第二类为空间知识(如下图所示),空间知识来自地图业务中常见的空间数据,主要包含单个地理实体的位置信息(通常以地理坐标形式表示),两个地理实体之间的空间关系(通常以三元组的形式表示),以及人类移动数据(通常以 POI 序列的形式表示)。
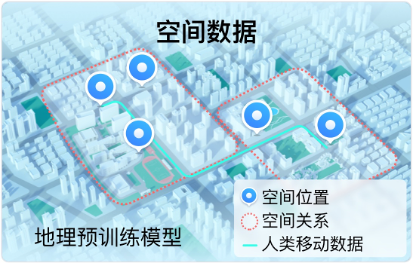
为了在预训练的过程中引入上述两类地理知识,需要解决以下两个挑战:
-
异构数据融合。蕴含地理知识的数据类型主要包含文本(包含地名知识)、三元组以及序列(包含空间知识)。如何将这些多源异构数据进行有效整合,并以统一的形式作为预训练模型的输入,是面临的首要问题。
-
『地理位置-语言』跨模态学习。现有的跨模态预训练大部分是对同一个概念的不同模态之间的关联进行学习。例如,在“视觉-语言”预训练中,主要目标是学习相同物体(如“一只猫”)的文本表示(如“可爱的猫”)和图像(如“猫的图片”)表示之间的语义关联。而在进行“地理位置-语言”预训练时,主要目标是学习一个地理实体(如“POI-ID1”)的文本属性(如该POI名称“北京西站”、POI地址“北京市丰台区莲花池东路118号”)与其对应地理坐标(该POI的经纬度)之间的关联。为了充分学习跨模态间的关联,需要设计有效的网络结构以及针对性的预训练目标。
为解决上述挑战,ERNIE-GeoL 在预训练数据构建、模型结构以及预训练目标三个方面进行了针对性的设计和创新:
1. 预训练数据构建
为了解决挑战1,ERNIE-GeoL 以百度地图数据和 POI 数据库作为数据源,基于图桨 PGL(Paddle Graph Learning),利用其中蕴含的空间关系构建了异构图。如下图所示,该图由两种节点(POI 和查询)和以下三种不同类型的边构成:
-
起点-到-终点,表示的是用户对两个地点的访达,蕴含了丰富的空间移动信息。
-
POI-共同出现-POI,表示共同出现在同一个地块内的两个POI,蕴含了空间共现信息。
-
查询-点击-POI,来自于用户的地点查询日志,蕴含了丰富的地名和空间关系知识。
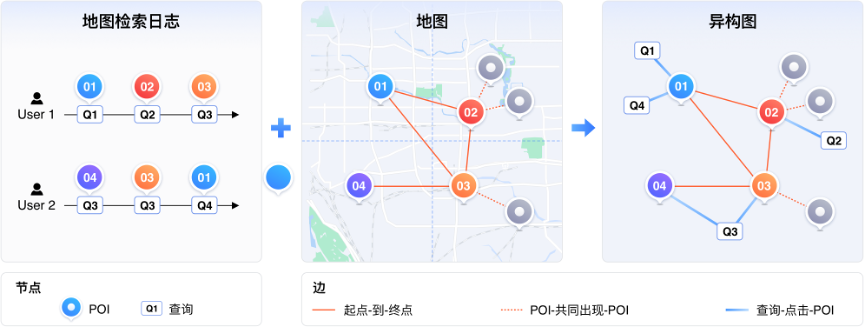
在此异构图的基础上,我们使用随机游走算法自动化地生成大量节点序列作为预训练数据。下面是两个真实的游走序列示例。
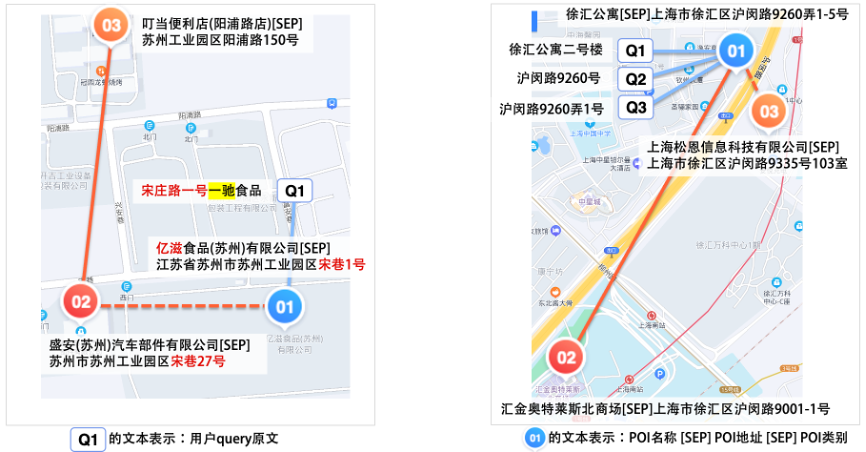
2.模型结构
以上述方式构建的数据蕴含了丰富的地理知识。为了更有效地从中学习地理知识,需要对其中的图结构进行充分建模。
为此,我们在设计 ERNIE-GeoL 的模型结构(详见下图)时,专门引入了一个 TranSAGE 聚合层,用于充分学习训练数据中的图结构,同时将不同模态的数据映射到统一的表示空间。TranSAGE 层使用多头注意力机制对每个节点的不同表示进行聚合,具体细节可参考文后所附论文。

3.预训练目标
为了让模型充分学习『地理位置-语言』间的关联,需要设计行之有效的预训练目标。为此,在用于学习地名知识的掩码语言模型(MLM)预训练任务之外,我们设计了用于学习文本与地理坐标关联的 Geocoding(GC)预训练任务。
实现 Geocoding,有两种候选方案:
-
直接学习文本到经纬度坐标的映射关系。这种方案是回归任务,它的难点主要在于需要学习文本到唯一一个精确坐标的映射关系。若满足业务要求(误差<=20m),该坐标需要精确到小数点后4位,学习难度较大。
-
将地图按一定范围划分格子,给每个格子编号,学习文本到编号的映射关系。这种方案是分类任务,优点是可以捕捉文本和编号间的关联,主要缺点是维度爆炸问题。例如,将全世界按4平方米的范围划分格子,会得到105万亿个编号。
为了结合上述两种方案的优点并规避其缺点,我们选择让模型学习文本与其对应的地理实体所在的真实世界地块的多层级字符编码之间的关联。
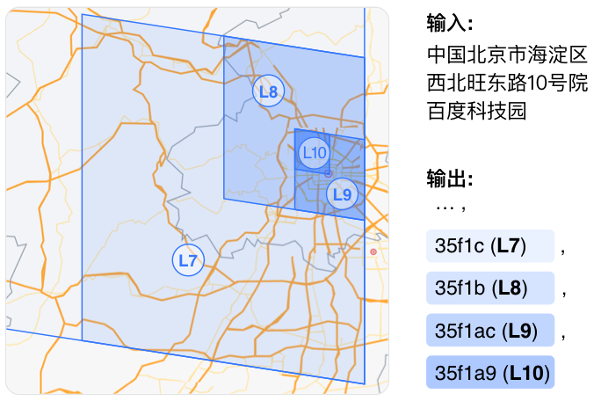
下图给出了该任务的一个示例,我们将百度科技园所在的不同层级的地块(L7 至 L10)表示成前缀互有关联的 token(35f1c 至 35f1a9)。
我们利用固定网格系统的地块编码方式获取其对应的 token。固定网格系统是一类对地球表面按照固定位置划分格子的系统。大部分系统在进行划分时允许选择不同的层级,即用不同尺寸的格子对地表进行划分。按一种固定尺寸划分格子后,每个坐标点只落在一个格子内。
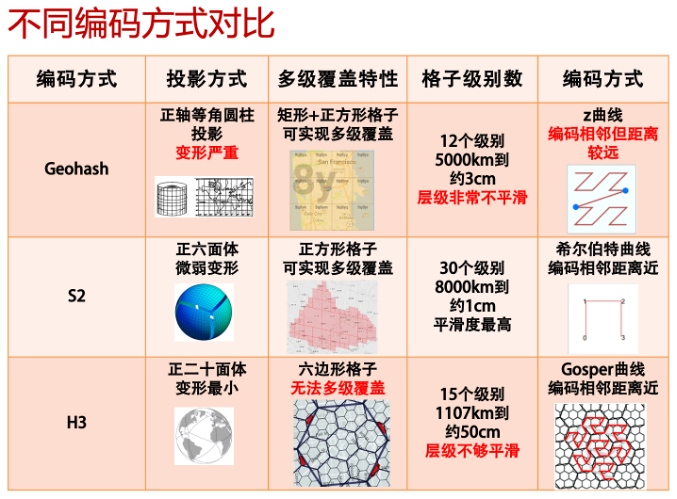
我们从 GeoHash、H3 和 S2 geometry 这3种常见的固定网格系统(3种方案的具体对比见下图)中选择了 S2。主要原因在于S2使用变形程度较小的球面投影方式,并具有以下特性:
-
S2 转换后的token层级最多;
-
S2 不同层级间的平滑度最高;
-
S2 可以实现多级覆盖,即子级别的token所代表的地块一定位于父级别的token所代表的地块之内。
依托多级覆盖特性,在训练的过程中,我们使模型按预测地块编码中每一个字符的方式一次性的预测出多个层级的地块表示。
按这种方式,模型利用注意力机制可以学习到输入中描述不同层级地理概念的文本(如北京市、海定区、西北旺东路10号、百度科技园)和不同层级(如L6、L9、L15、L15)的地理编码的映射关系,从而使模型充分且高效地学习文本与地理坐标的关联,加强模型在处理不完整或不规范地理描述文本时的鲁棒性。具体训练方式详见论文。
ERNIE-GeoL 应用效果如何?
为了验证 ERNIE-GeoL 在地理位置相关任务上的应用效果,我们选取了5个地图业务中的常见任务(详见表1),包括:
-
POI 检索业务中的 query 意图识别(Query Intent Classification)任务;
-
POI 检索业务中的 query-POI 匹配(Query-POI Matching)任务;
-
POI 推荐业务中的下一个 POI 推荐(Next POI Recommendation)任务;
-
POI 信息处理业务中的地址解析(Address Parsing)任务;
-
POI 信息处理业务中的地理编码(Geocoding)任务。
表2显示了各个模型在上述5个任务上的评测结果。从评测结果中可以看出,ERNIE-GeoL 在各个任务上的效果,均显著超过了其他通用预训练语言模型。

ERNIE-GeoL 是否学习到了
地理与语言间的关联?
我们通过定性分析来验证 ERNIE-GeoL 是否学习到了地理与语言间的关联。
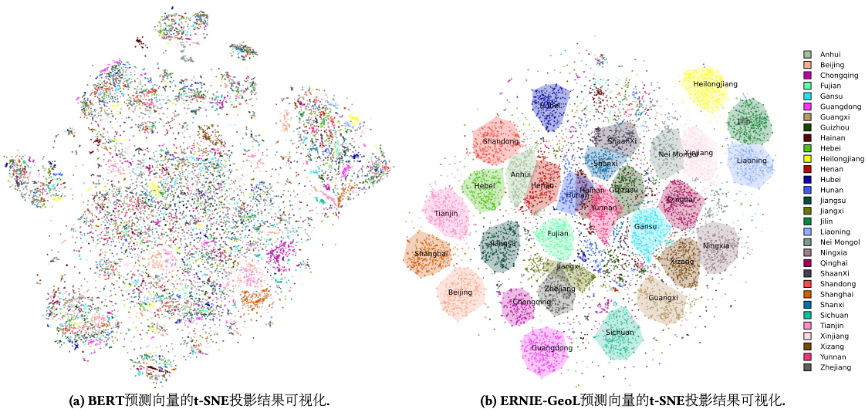
首先,我们选取中国除港澳台以外的31个省级行政区划中检索热度 top 500的 POI。基于这些POI的名字和地址,通过不同预训练模型获得与之对应的 embeddings 后,再利用 t-SNE 算法将得到的 embeddings 进行降维。
结果如下图所示,从中我们可以看出,通用的预训练语言模型 BERT 无法将位于同一省份的 POI 聚在一起。与之形成鲜明对比的是,“地理位置-语言”预训练模型 ERNIE-GeoL 能够很好地将位于相同省份的 POI 聚在一起。同时,在现实世界中临近的省份在图中也相邻,如图中右上角的黑吉辽三省。
其次,借鉴著名的“king – man + woman ≈ queen”类比示例,我们也设计了两个类比示例来验证 ERNIE-GeoL 对于地理类比关系的学习效果(见下图)。
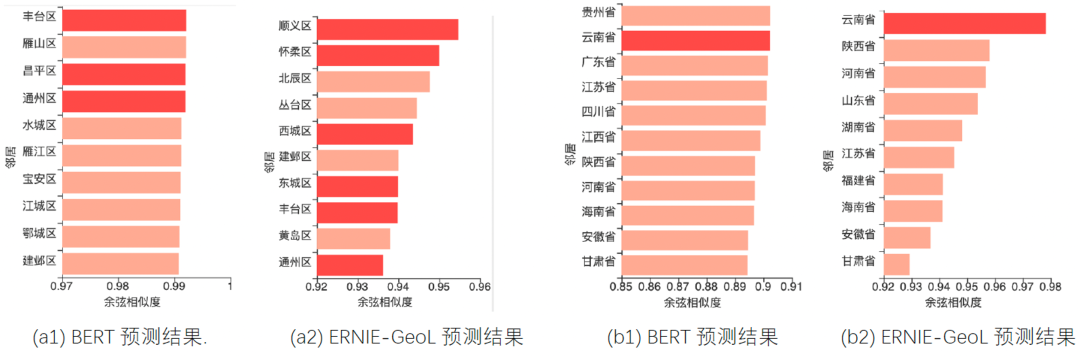
示例 a 用来测试模型是否学习到了“一个城市的下级行政区划”的关系。我们首先将查询设置为“黄埔区-上海+北京”,候选设置为所有中国城市的下级区域名称。然后用预训练模型将查询和候选分别表示为向量并计算各个候选向量和查询向量之间的余弦相似度。
图 a1,a2 分别展示了 BERT 和 ERNIE-GeoL 预测结果中余弦相似度排名前10的候选。从中可以看出,ERNIE-GeoL 召回的正确区域比 BERT 多出一倍。类似的,我们设计了另一个示例来测试模型是否学习到了“一个省的省会”的关系。在该测试中,查询设置为“广东省-广州+昆明”,候选设置为所有中国省级行政单位的名称。
如图 b1,b2 所示,ERNIE-GeoL 以最高的相似度得分输出了正确的目标省份“云南省”。此外,在这两幅图中,与 ERNIE-GeoL 预测的结果相比,BERT 预测结果的余弦相似度得分间的区分度较低。上述两个定性分析的结果表明 ERNIE-GeoL 在一定程度上学会了不同地理实体之间的空间关系和语义关系。
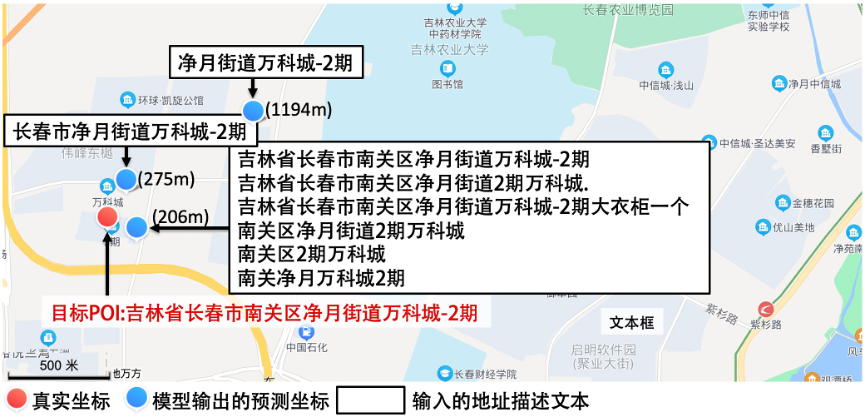
最后,我们以 Geocoding 任务为例验证 ERNIE-GeoL 是否能够处理关于同一地理实体的各种不同描述。该任务的输入为目标 POI(下图中红色文字描述的 POI)的不同文本描述(下图中黑框白底矩形中的文本),输出则为模型预测出的地理坐标。
从该示例中我们可以看出,ERNIE-GeoL 具有较强的鲁棒性,可以处理关于同一地点的不同形式的文本描述,并且能够排除无关词(例如图中“大衣柜一个”)的干扰,准确地预测出与之对应的地理坐标。
总结
ERNIE-GeoL 通过地图数据自动化地构建了蕴含地理知识的大规模预训练数据,并使用专门设计的网络结构和相匹配的预训练目标对地理知识进行了充分的学习。
定量实验中的显著效果提升和定性实验中的差异化结果,表明我们所提出的“地理位置-语言”预训练模型 ERNIE-GeoL 能够显著提升地理位置相关任务的效果并具有广泛的应用落地潜力。
-
有关 ERNIE-GeoL 的更多细节,请参考论文:
https://arxiv.org/abs/2203.09127
















 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









