




 本文介绍了VGG网络模型,通过3x3卷积核和池化层构建深度结构,提升模型对特征的学习能力。VGG块的规律和优势,以及如何调整模型参数以应对大规模数据。通过实例展示了模型结构和训练过程,包括参数尺寸和计算复杂度的控制。
本文介绍了VGG网络模型,通过3x3卷积核和池化层构建深度结构,提升模型对特征的学习能力。VGG块的规律和优势,以及如何调整模型参数以应对大规模数据。通过实例展示了模型结构和训练过程,包括参数尺寸和计算复杂度的控制。
我们在AlexNet(MXNet对AlexNet模型的构建与实现(与LeNet的对比))中知道加深层可以对大型数据集取得不错的结果,但是论文没有具体提供如何去设计这样的模型,鉴于此,VGG网络模型的出现,提供了一种构建深度模型的思路。
有兴趣的可以阅读VGG的论文: VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION 模型名字来自于论文作者所在的实验室(Visual Geometry Group),构建的思路简单,就是重复使用简单的基础块(VGG块)。
VGG块的组成规律是:连续使用尺寸为3x3,填充为1的卷积核,后接一个尺寸为2x2,步幅为2的池化层。其中卷积层保持输入的高和宽不变,池化层则对其减半。
为什么使用3*3的卷积核,有哪些优势?
3*3的卷积是包含了上下左右和中心的最小单元的感受野,堆叠小的卷积核可以获得和大的卷积核相同大小的视野,让输入的通道数变得更大(可以将通道数看做特征值),尺寸变小。
比如2个3*3的卷积层(步幅为1)相当于1个5*5的卷积感受视野,3个3*3层相当于1个7*7的感受视野,这样可以加深模型的深度,使得学习能力变得更好,也就是说增强了CNN对特征的学习能力,而且相比较大的卷积核,参数大小也要小很多,计算量变得更小。
import d2lzh as d2l
from mxnet import gluon,init,nd
from mxnet.gluon import data as gdata,nn
#VGG块,若干个3*3卷积加一个池化层
def vgg_block(num_convs,num_channels):
blk=nn.Sequential()
for _ in range(num_convs):
blk.add(nn.Conv2D(num_channels,kernel_size=3,padding=1,activation='relu'))
blk.add(nn.MaxPool2D(pool_size=2,strides=2))
return blk
#VGGNet(VGG-11:8个卷积层加3个全连接层)
conv_arch=((1,64),(1,128),(2,256),(2,512),(2,512))#前两块是单卷积层,后三块是双卷积层
def vgg(conv_arch):
net=nn.Sequential()
for (num_convs,num_channels) in conv_arch:
net.add(vgg_block(num_convs,num_channels))
#三个全连接层
net.add(nn.Dense(4096,activation='relu'),nn.Dropout(0.5),
nn.Dense(4096,activation='relu'),nn.Dropout(0.5),
nn.Dense(10))
return net
#构造一个样本,查看每层的输出形状
net=vgg(conv_arch)
net.initialize()
X=nd.random.uniform(shape=(1,1,224,224))
for blk in net:
X=blk(X)
print(blk.name,'输出形状:',X.shape)
'''
sequential3 输出形状: (1, 64, 112, 112)
sequential4 输出形状: (1, 128, 56, 56)
sequential5 输出形状: (1, 256, 28, 28)
sequential6 输出形状: (1, 512, 14, 14)
sequential7 输出形状: (1, 512, 7, 7)
dense0 输出形状: (1, 4096)
dropout0 输出形状: (1, 4096)
dense1 输出形状: (1, 4096)
dropout1 输出形状: (1, 4096)
dense2 输出形状: (1, 10)
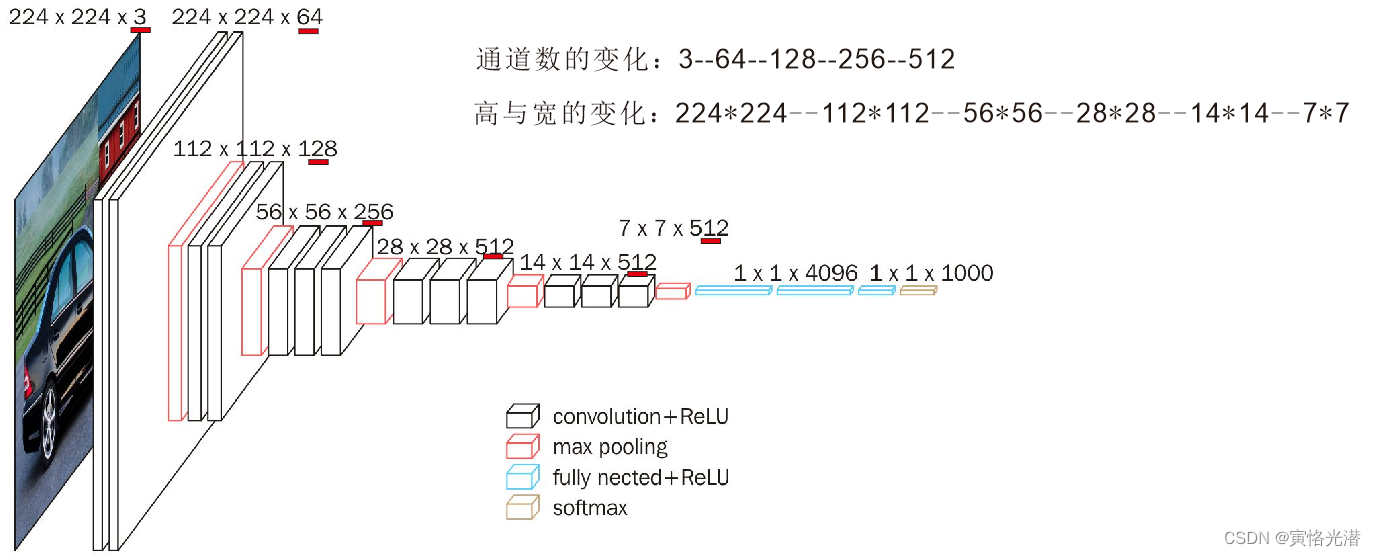
'''可以看出 每次的输出的高和宽减半,通道数翻倍,当高宽变成7*7之后传入到全连接层,由于都是3*3的卷积核,所以每层模型的参数尺寸和计算复杂度与输入高、宽、通道数以及输出通道数的乘积成正比。VGG的这种高宽减半以及通道数翻倍的设计,使得多数卷积层都有相同的模型参数尺寸和计算复杂度。
训练模型,与AlexNet类似,这里将学习率调大点。由于计算量大,容易内存溢出,将图片缩小至96来训练,这个看个人情况而定,如下错误:
mxnet.base.MXNetError: [10:10:03] c:\jenkins\workspace\mxnet-tag\mxnet\src\storage\./pooled_storage_manager.h:157: cudaMalloc failed: out of memory
import mxnet as mx
ratio=4
small_conv_arch=[(pair[0],pair[1]//ratio) for pair in conv_arch]
net=vgg(small_conv_arch)
lr,num_epochs,batch_size,ctx=0.05,5,128,mx.gpu()
net.initialize(ctx=ctx,init=init.Xavier())
trainer=gluon.Trainer(net.collect_params(),'sgd',{'learning_rate':lr})
train_iter,test_iter=d2l.load_data_fashion_mnist(batch_size,resize=96)
d2l.train_ch5(net,train_iter,test_iter,batch_size,trainer,ctx,num_epochs)
'''
epoch 1, loss 1.2532, train acc 0.554, test acc 0.792, time 53.6 sec
epoch 2, loss 0.4949, train acc 0.818, test acc 0.841, time 51.4 sec
epoch 3, loss 0.3940, train acc 0.856, test acc 0.871, time 51.4 sec
epoch 4, loss 0.3464, train acc 0.873, test acc 0.883, time 51.5 sec
epoch 5, loss 0.3153, train acc 0.884, test acc 0.890, time 51.5 sec
'''

















 1473
1473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











