







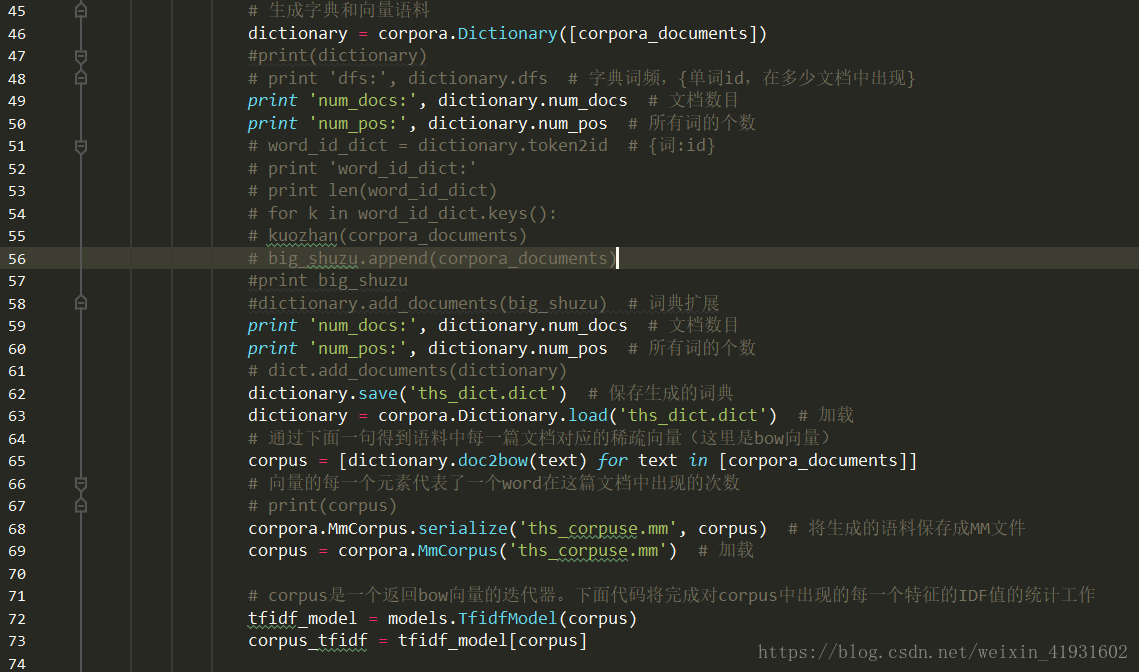

# 生成字典和向量语料
dictionary = corpora.Dictionary([corpora_documents])
#print(dictionary)
# print 'dfs:', dictionary.dfs # 字典词频,{单词id,在多少文档中出现}
print 'num_docs:', dictionary.num_docs # 文档数目
print 'num_pos:', dictionary.num_pos # 所有词的个数
# word_id_dict = dictionary.token2id # {词:id}
# print 'word_id_dict:'
# print len(word_id_dict) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















05-05
 2675
2675
2675
11-01
4306
4306
12-26
352
352
08-03
627
627
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









