




 本文深入探讨Apache Kafka的架构与原理,讲解其高吞吐率的实现机制,包括顺序读写、零拷贝、批量发送和消息压缩等策略。同时,介绍了Kafka的基本术语、工作流程、消息路由策略及消息发送的可靠性机制。
本文深入探讨Apache Kafka的架构与原理,讲解其高吞吐率的实现机制,包括顺序读写、零拷贝、批量发送和消息压缩等策略。同时,介绍了Kafka的基本术语、工作流程、消息路由策略及消息发送的可靠性机制。
1. 概述
1.1 kafaka 简介
Apache Kafka 是一个快速、可扩展的、高吞吐的、可容错的分布式“发布-订阅”消息系统,使用 Scala 与 Java 语言编写,能够将消息从一个端点传递到另一个端点,较之传统的消息中间件(例如 ActiveMQ、RabbitMQ),Kafka 具有高吞吐量、内置分区、支持消息副本和高容错的特性,非常适合大规模消息处理应用程序。
Kafka 官网: http://kafka.apache.org/
1.2 Kafa 系统架构
老版架构图:
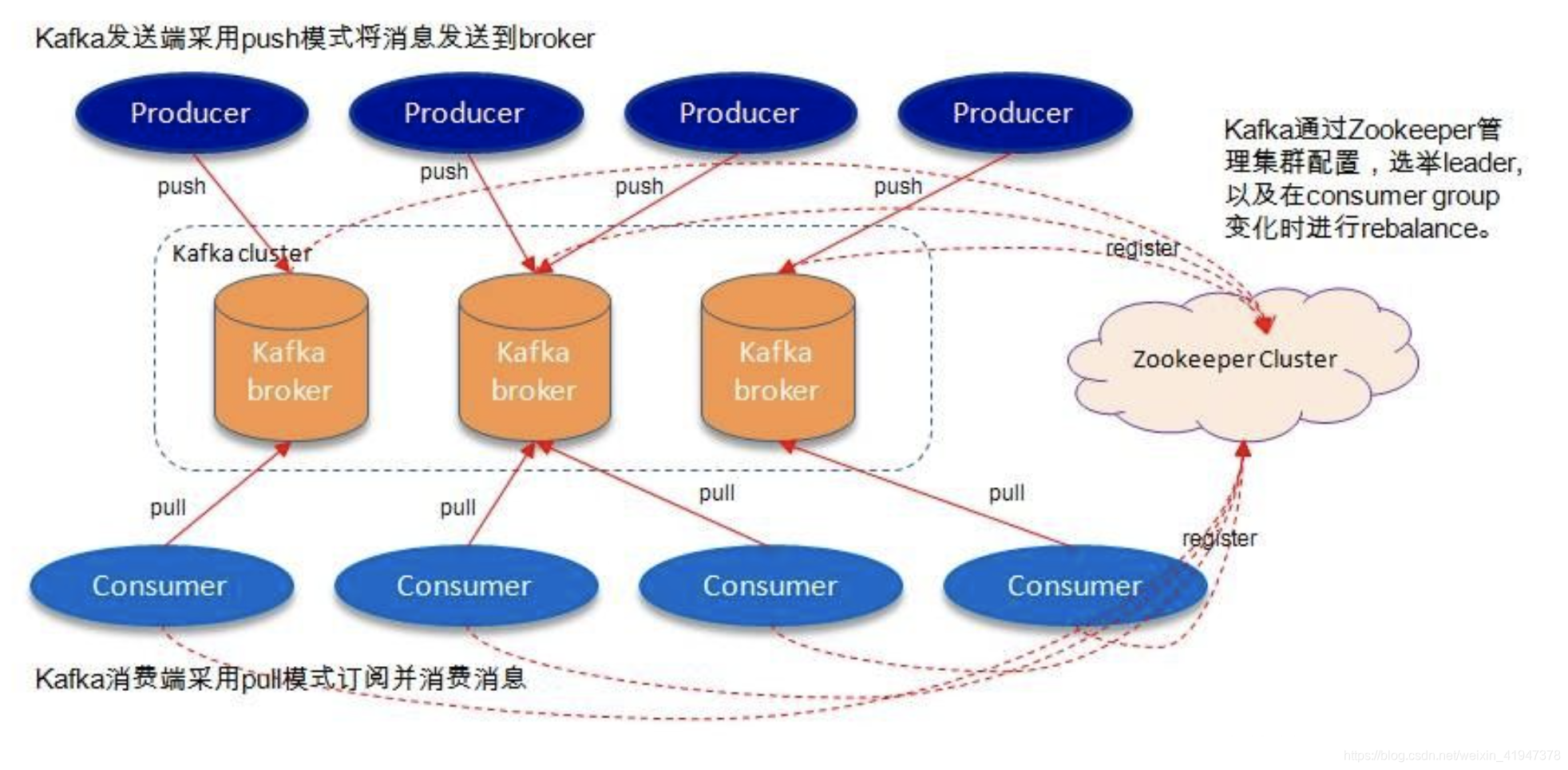
新版架构图:
Kafka 在 0.9 之前是基于 Zookeeper 来存储 Partition 的 Offset 信息 (consumers/{group}/offsets/{topic}/{partition}),因为 Zookeeper 并不适用于频繁的写操作,所以在 0.9 之后通过内置 Topic 的方式来记录对应 Partition 的 Offset:
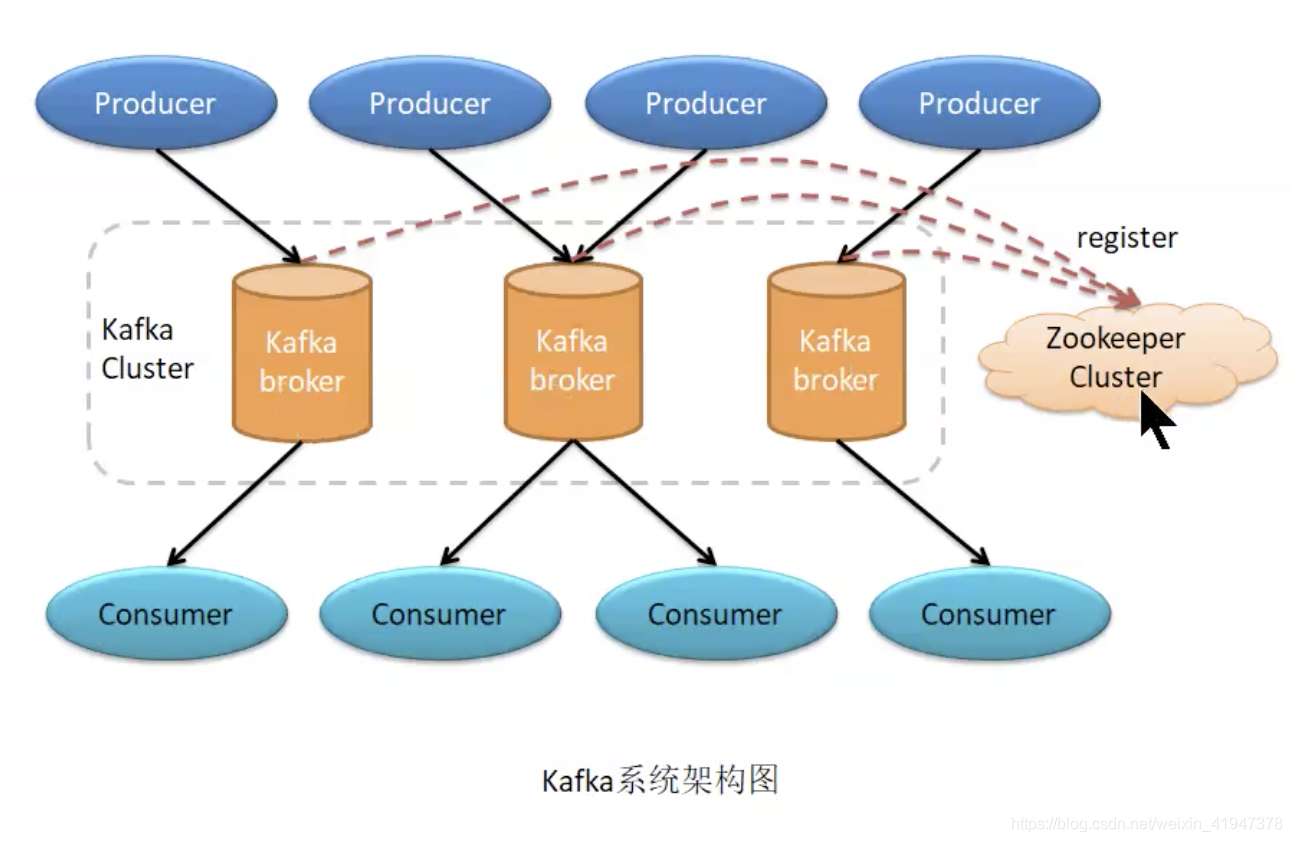
Kafka broker:就是Kafka主机
Producer:消息生产者
Consumer:消息消费者
Zookeeper Cluster:ZK集群,管理broker
如上图,一个kafka架构包括:
- 若干个Producer(服务器日志、业务数据、web前端产生的page view等)
- 若干个Broker(kafka支持水平扩展,一般broker数量越多集群的吞吐量越大)
- 若干个consumer group
- 一个Zookeeper集群(kafka通过Zookeeper管理集群配置、选举Broker Controller)。
1.3 应用场景
官网就有介绍,打开官网找到USE CASES:
-
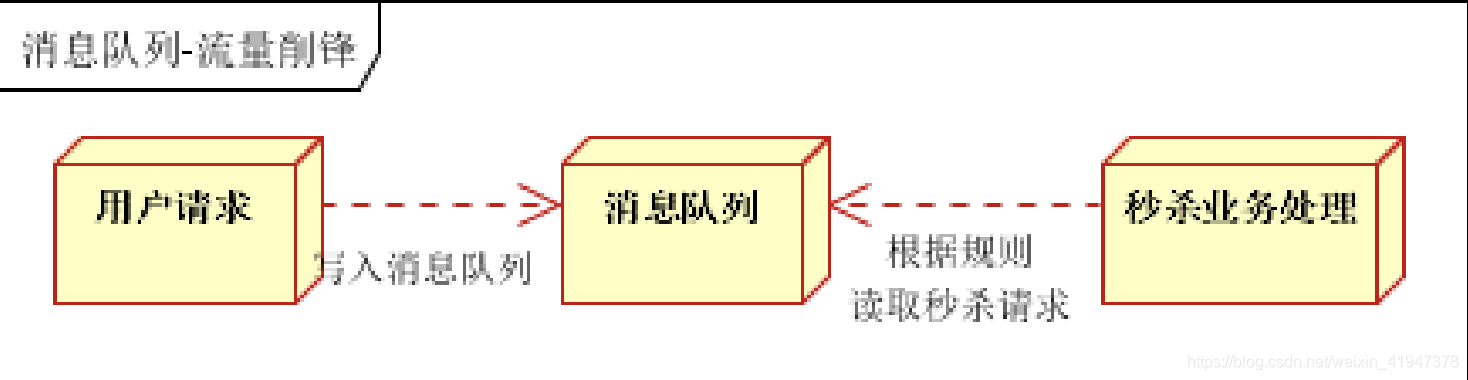
Messaging - 消息系统
- 最基本用法,生产者生产的没有处理的消息先缓存到Kafka里,后期进行逐步的处理,即生产和消费的速度不匹配的场景,限流削峰就是这种用法(类似于ActiveMQ、RabbitMQ)
- 一般在秒杀业务经常用到,主要防止流量过大导致系统宕机,但会造成超卖的问题。
Kafka可以很好地替代传统邮件代理。消息代理的使用有多种原因(将处理与数据生产者分离,缓冲未处理的消息等)。与大多数邮件系统相比,Kafka具有更好的吞吐量,内置的分区,复制和容错能力,这使其成为大规模邮件处理应用程序的理想解决方案。
根据我们的经验,消息传递的使用通常吞吐量较低,但是可能需要较低的端到端延迟,并且通常取决于Kafka提供的强大的持久性保证。
在这一领域,Kafka与ActiveMQ或 RabbitMQ等传统消息传递系统相当。 -
Website Activity Tracking - Web站点活动追踪
- 记录站点行为,收集数据,对用户行为进行分析,可以进行用户画像,精准营销
- 用户在网站的不同活动消息发布到不同的主题中心,然后可以对这些消息进行实时监测实时处理。当然,也可加载到 Hadoop 或离线处理数据仓库,对用户进行画像。像淘宝、京东这些大型的电商平台,用户的所有活动都是要进行追踪的。
Kafka最初的用例是能够将用户活动跟踪管道重建为一组实时的发布-订阅供稿。这意味着将网站活动(页面浏览,搜索或用户可能采取的其他操作)发布到中心主题,每种活动类型只有一个主题。这些提要可用于一系列用例的订阅,包括实时处理,实时监控,以及加载到Hadoop或脱机数据仓库系统中以进行脱机处理和报告。
活动跟踪通常量很大,因为每个用户页面视图都会生成许多活动消息。 -
Metrics - 数据监控
- 从分布式应用里收集指定类型的监控数据,聚合到Kafka里
Kafka通常用于操作监控数据。这涉及汇总来自分布式应用程序的统计信息,以生成操作数据的集中供稿。
-
Log Aggregation - 日志聚合
- 将应用服务器的日志文件收集到文件服务器,然后对文件进行清理,分类分主题写到Kafka(类似于Scribe或Flume)
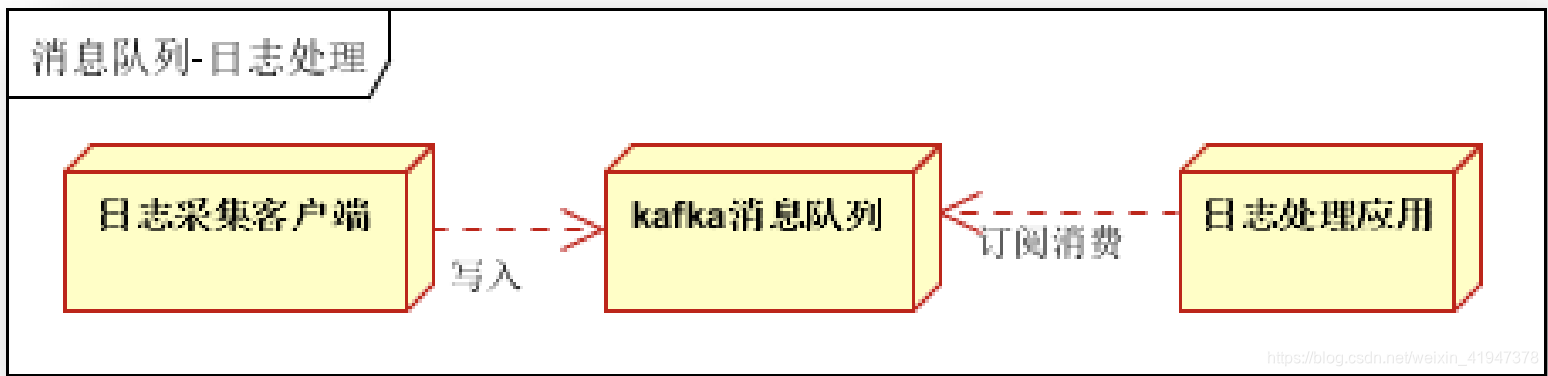
许多人使用Kafka代替日志聚合解决方案。日志聚合通常从服务器上收集物理日志文件,并将它们放在中央位置(也许是文件服务器或HDFS)以进行处理。Kafka提取文件的详细信息,并以日志流的形式更清晰地抽象日志或事件数据。这允许较低延迟的处理,并更容易支持多个数据源和分布式数据消耗。与以日志为中心的系统(例如Scribe或Flume)相比,Kafka具有同样出色的性能,由于复制而提供的更强的耐用性保证以及更低的端到端延迟。
- 将应用服务器的日志文件收集到文件服务器,然后对文件进行清理,分类分主题写到Kafka(类似于Scribe或Flume)
-
Stream Processiong - 流处理
- 有点类似于工作流的感觉,一个业务细分为多个节点,每个节点等于一个主题,当前节点处理完成就发布到下一个节点的主题处理
Kafka的许多用户在由多个阶段组成的处理管道中处理数据,其中原始输入数据从Kafka主题中使用,然后进行汇总,充实或以其他方式转换为新主题,以供进一步使用或后续处理。例如,用于推荐新闻文章的处理管道可能会从RSS提要中检索文章内容,并将其发布到“文章”主题中。进一步的处理可能会使该内容规范化或重复数据删除,并将清洗后的文章内容发布到新主题;最后的处理阶段可能会尝试向用户推荐此内容。这样的处理管道基于各个主题创建实时数据流图。从0.10.0.0开始,一个轻量但功能强大的流处理库称为Kafka Streams 可以在Apache Kafka中使用来执行上述数据处理。除了Kafka Streams,其他开源流处理工具还包括Apache Storm和 Apache Samza。
-
事件源 Event Sourcing
- 应用中的各种事件,每一种类型的事件都可以作为一个主题,事件很大的特征就是时间顺序,可以按照事件产生的时间先后顺序写入到Kafka,不同的事件写入到不同的主题
事件源是一种应用程序设计方式,其中状态更改以时间顺序记录。Kafka对非常大的存储日志数据的支持使其成为使用这种样式构建的应用程序的绝佳后端。
-
Commit Log - 提交日志
- 可以用作分布式系统的一种外部提交日志
Kafka可以用作分布式系统的一种外部提交日志。该日志有助于在节点之间复制数据,并充当故障节点恢复其数据的重新同步机制。Kafka中的日志压缩功能有助于支持此用法。在这种用法中,Kafka类似于Apache BookKeeper项目。
PS:Kafka的定位个人感觉像一个数据/消息中转站,有人存,有人用。
1.4 kafka 高吞吐率实现
Kafka 与其它 MQ 相比,其最大的特点就是高吞吐率。为了增加存储能力,Kafka 将所有的消息都写入到了低速大容的硬盘。按理说,这将导致性能损失,但实际上,kafka 仍可保持超高的吞吐率,性能并未受到影响。其主要采用了如下的方式实现了高吞吐率。
- 顺序读写:Kafka 将消息写入到了分区 partition 中,而分区中消息是顺序读写的。顺序读写要远快于随机读写。
- 零拷贝:生产者、消费者对于 kafka 中消息的操作是采用零拷贝实现的。(直接操作内核空间)
- 批量发送:Kafka 允许使用批量消息发送模式。(先把每次要发送的消息都放入缓存,根据不同的策略,比如缓存空间满了,在批量一起发送出去)
- 消息压缩:Kafka 支持对消息集合进行压缩。(可以把一堆消息压缩成一个消息,这样传输次数、传输量都变少了,传输压力就变小了,当然压缩和解压的操作是在生产者和消费者端完成的,会增加生产者和消费者端的CPU工作量,但是对于大消息的处理,瓶颈主要集中在网络传输传输上而不是CPU,所以是值得的)
2. Kafka 基本术语
对于 Kafka 基本原理的介绍,可以通过对以下基本术语的介绍进行。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























 到【灌水乐园】发言
到【灌水乐园】发言









