



 本文提出了一种新的基于文本的说话人头部视频生成框架,该框架结合了高保真的面部表情和头部运动,与文本情感和语音节奏相协调。通过使用时间对齐的文本作为输入,该方法解决了音色差异问题,能够生成包含丰富细节的对话头视频,适用于不同说话者。框架分为与说话人无关和特定于说话人的两个阶段,前者生成动画参数,后者根据这些参数合成特定说话人的视频。通过运动捕捉数据集,模型学习了面部表情和头部运动,以匹配音频。实验结果显示,该方法生成的视频具有高质量和照片真实性。
本文提出了一种新的基于文本的说话人头部视频生成框架,该框架结合了高保真的面部表情和头部运动,与文本情感和语音节奏相协调。通过使用时间对齐的文本作为输入,该方法解决了音色差异问题,能够生成包含丰富细节的对话头视频,适用于不同说话者。框架分为与说话人无关和特定于说话人的两个阶段,前者生成动画参数,后者根据这些参数合成特定说话人的视频。通过运动捕捉数据集,模型学习了面部表情和头部运动,以匹配音频。实验结果显示,该方法生成的视频具有高质量和照片真实性。
Write-a-speaker: Text-based Emotional and Rhythmic Talking-head Generation
写一个演讲者:基于文本的情绪化和有节奏的谈话头生成
链接
Arxiv:https://arxiv.org/abs/2104.07995
Video:https://www.youtube.com/watch?v=weHA6LHv-Ew
摘要
在本文中,我们提出了一种新的基于文本的说话人头部视频生成框架,该框架综合了高保真的面部表情和头部运动,并与文本情感、语音节奏和停顿相一致。具体来说,我们的框架包括一个独立于说话人的阶段和一个特定于说话人的阶段。在与说话人无关的阶段,我们设计了三个并行网络,分别从文本中生成嘴巴、上脸和头部的动画参数。在特定说话人阶段,我们提出了一个3D人脸模型引导的注意网络来合成针对不同个体的视频。它将动画参数作为输入,并利用注意遮罩操纵输入个体的面部表情变化。此外,为了更好地在视觉运动(即面部表情变化和头部移动)和音频之间建立真实的对应关系,我们利用高精度的运动帽数据集,而不是依赖特定个体的长视频。在获得视觉和音频通信后,我们可以以端到端的方式有效地训练我们的网络。对定性和定量结果的大量实验表明,我们的算法实现了高质量的照片真实感对话头部视频,包括根据语音节奏进行的各种面部表情和头部运动,并超过了最先进的水平。
1. 介绍
Talking head合成技术旨在从输入语音中生成具有真实面部动画的特定说话人的对话视频。输出的说话人头部视频已被应用于许多应用,如智能辅助、人机交互、虚拟现实和计算机游戏。由于其广泛的应用,说话人头部合成引起了广泛的关注。
以前的许多以音频为输入的作品主要关注面部下部(如嘴巴)的同步,但往往忽略头部和面部上部(如眼睛和眉毛)的动画。然而,整体面部表情和头部运动也被视为传递交流信息的关键因素(Ekman 1997)。例如,人类无意识地使用面部表情和头部动作来表达自己的情绪。因此,生成完整的面部表情和头部动作将导致更具说服力的人物谈话视频。
此外,由于不同个体之间的音色差异可能导致测试话语中的声学特征超出训练声学特征的分布范围,因此建立在音频和视觉模式之间直接关联基础上的现有技术也可能无法推广到新说话者的音频(Chou等人,2018)。因此,基于声学特征的框架不能很好地处理来自不同音色的人的现场演讲或合成演讲(Sadoughi和Busso,2016)。
与以前的作品不同,我们采用时间对齐的文本(即,带有对齐音素时间戳的文本)作为输入特征,而不是声学特征,以缓解音色差距问题。一般来说,时间对齐的文本可以通过语音识别工具从音频中提取,或者通过文本到语音工具生成。由于口语脚本对不同的人是不变的,因此我们基于文本的框架能够针对不同的说话人实现健壮的性能。
本文提出了一种新的基于语音脚本生成整体面部表情和相应头部动画的框架。我们的框架由两个阶段组成,即说话人无关阶段和说话人特定阶段。在与说话人无关的阶段,我们的网络作品旨在捕捉文本和视觉外观之间的一般关系。与以前的方法(Suwajanakorn、Seitz和Kemelmacher-Shlizerman 2017;Taylor等人2017;Fried等人2019)不同,我们的方法仅合成和混合口腔区域像素,我们的方法旨在产生整体面部表情变化和头部运动。因此,我们设计了三个网络,分别将输入文本映射为嘴巴、上脸和头部姿势的动画参数。此外,我们使用一个运动帽系统来构建高质量面部表情以及头部运动和音频之间的对应关系,作为我们的训练数据。因此,我们收集的数据可以用于有效地训练我们的非特定人网络,而不需要特定人的长时间谈话视频。
由于与说话人无关的网络输出的动画参数是通用的,因此我们需要根据特定的输入说话人定制动画参数,以获得令人信服的生成视频。在特定说话人阶段,我们将动画参数作为输入,然后利用它们来装配给定说话人的面部标志。此外,我们还开发了一个自适应注意网络,使被操纵的地标适应特定人的说话特征。在这样做的过程中,我们只需要新发言人的参考视频(约5分钟),而不是以前方法通常要求的超过一小时的特定发言人视频(Suwajanakorn、Seitz和Kemelmacher Shlizerman 2017;Fried等人,2019)。
总的来说,我们的方法从目标表演者的简短参考视频中生成照片逼真的说话头部视频。生成的视频还提供了前体的丰富细节,如逼真的衣服、头发和面部表情。
2. 相关工作
2.1 人脸动画合成
面部动画合成预先定义3D面部模型并生成动画参数以控制面部变化。LSTM(Hochreiter和Schmidhuber,1997)广泛用于序列建模的人脸动画合成。一些作品采用BiLSTM(Pham、Cheung和Pavlovic 2017)、CNN-LSTM(Pham、Wang和Pavlovic 2017)或精心设计的LSTM(Zhou等人,2018)和回归损失、GAN损失(Sadougi和Busso 2019)或多任务训练策略(Sadougi和Busso 2017)来合成完整的面部/口腔动画。然而,由于顺序计算,LSTM的工作速度往往较慢。CNN被证明具有处理顺序数据的类似能力(Bai、Kolter和Koltun,2018年)。一些作品利用CNN从声学特征(Karras et al.2017;Cudeiro et al.2019)或时间对齐音素(Taylor et al.2017)中模仿嘴巴或脸部。头部动画合成侧重于从输入语音合成头部姿势。一些作品使用BiLSTM(丁、朱和谢,2015;Green-wood、Matthews和Laycock,2018)或trans-former编码器(Vaswani等人,2017)直接回归头部姿势。更准确地说,由言语产生的头部姿势是一对多映射,Sadoughi和Busso(2018)采用了GAN(Goodfelle等人,2014;Mirza and Osindero 2014; Yu et al. 2019b,a) 保持多样性。
2.2 人脸视频生成
音频驱动。音频驱动的人脸视频合成直接从输入音频生成2D对话视频。之前的作品(Vougioukas、Petridis和Pantic 2019;Chen等人2018;Zhou等人2019;Wiles、Sophia和Zisserman 2018;Pra-jwal等人2020)利用两个子模块计算目标扬声器的人脸嵌入特征和音频嵌入特征,然后将其作为输入融合到一个会说话的人脸生成器。另一组作品将几何体生成和外观生成分离为两个阶段。视觉测量生成阶段推断出合适的面部标志,并将其作为外观生成阶段的输入。使用特定说话人模型(Suwa-janakorn、Seitz和Kemelmacher-Shlizerman 2017;Das等人2020;Zhou等人2020)或线性主成分(Chen等人2019、2020)推断地标。Thies等人(2020年)生成3D可变形模型(3DMM)的表达式系数,然后使用神经渲染器生成照片真实感图像。Fried等人(2019年)通过搜索和混合参考视频的现有表达式来推断表达式参数,然后使用递归神经网络生成修改后的视频。虽然他们的方法也以文本作为输入,但由于viseme搜索,生成新句子的效率很低(10min-2h)。此外,两部作品都未能控制上脸和头部姿势,以匹配语音节奏和情感。
视频驱动。视频驱动的方法将一个人的表情传递给另一个人。一些作品(Ha等人,2020年;Zeng等人,2020年;Song等人,2019年;Siarohin等人,2019年)将单个图像作为身份输入。其他作品采用视频(Thies等人,2015年、2018年)作为身份输入,以提高视觉质量。Thies等人(2016年)重建并渲染网格模型并填充内嘴作为输出,重建的面部纹理在说话时保持不变。一些作品使用GAN直接生成2D图像,而不是3D渲染(Nirkin、Keller和Hassner 2019;Zakharov等人2019;Wu等人2018;Thies、Zollh̉ofer和Nießner 2019)。Kim等人(2019年)基于对两位说话者未配对数据的顺序学习,保留口腔运动风格。或者,我们的工作生成成对的口腔表达数据,使风格学习更容易。Kim等人(2018年)还使用3DMM渲染几何体信息。我们的方法不是转移现有表达式,而是从文本生成新表达式。此外,我们的方法保留了说话人的嘴运动风格,并设计了一个自适应注意网络,以获得更高的图像分辨率和更好的视觉质量
3. 基于文本的说话人生成
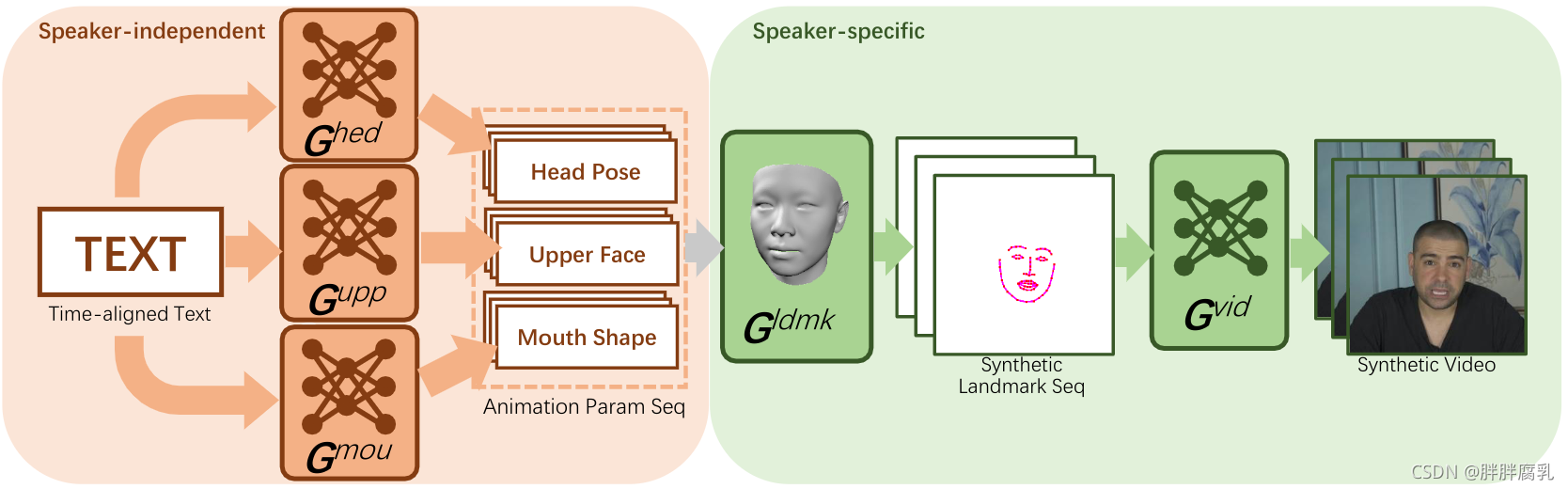
图2:我们方法的管道。与说话人无关的阶段将时间对齐的文本作为输入,并生成头部姿势、上脸和嘴形状动画参数。然后,特定于说话人的舞台根据动画参数生成合成的说话人头部视频。

图3:Mocap数据集的集合。录音是由一位戴着头盔的职业女演员进行的。头盔上的标记提供头部姿势的信息。头盔上的红外摄像机记录精确的面部表情。
我们的框架将时间对齐的文本作为输入,并输出照片逼真的对话头视频。它可以推广到一个特定的演讲者,他/她有大约5分钟的谈话视频(参考视频)。图2展示了我们框架的管道。 G mou , G upp G^{\text {mou }},G^{\text {upp }} Gmou ,Gupp 和 G hed G^{\text {hed }} Ghed 以时间对齐的文本作为输入,分别生成与说话人无关的口腔动画参数,正脸及头部姿态。他们没有从参考视频中学习,而是利用Mocap数据集获得更高的准确性。由于几何推断中的一个小错误可能会导致外观推断中的明显伪影,我们引入了一个3D人脸模块 G l d m k G^{ldmk} Gldmk 来合并头部和面部表情参数,并将其转换为特定于说话人的面部关键点序列。最后, G v i d G^{vid} Gvid 通过渲染头发、面部、上身和背景的纹理,根据人脸关键点序列合成特定于说话人的说话人头部视频。
3.1 Mocap数据集
为了获得高保真的完整面部表情和头部姿势,我们根据图3所示的运动捕捉(Mocap)系统1记录一个视听数据集。收集的数据包含mouth参数序列 m mou = { m t mou } t = 1 T m^{\text {mou }}=\left\{m_{t}^{\text {mou }}\right\}_{t=1}^{T} mmou ={mtmou }t=1T ,其中 m t mou ∈ R 28 m_{t}^{\text {mou }} \in \mathbb{R}^{28} mtmou ∈R28 ,上表面参数序列 m u p p = { m t u p p } t = 1 T m^{u p p}=\left\{m_{t}^{u p p}\right\}_{t=1}^{T} mupp={mtupp}t=1T ,其中 m t u p p ∈ R 23 m_{t}^{u p p} \in \mathbb{R}^{23} mtupp∈R23 和头部姿势参数序列 m hed = { m t hed } t = 1 T m^{\text {hed }}=\left\{m_{t}^{\text {hed }}\right\}_{t=1}^{T} mhed ={mthed }t=1T ,其中 m t hed ∈ R 6 m_{t}^{\text {hed }} \in \mathbb{R}^{6} mthed ∈R6。 T T T 是一段话语中的帧长度。 m mou m^{\text {mou }} mmou 和 m upp m^{\text {upp }} mupp 根据面移定义定义为混合形状权重。每个混合形状代表面部运动的某一部分,例如眼睛睁开,嘴巴向左。我们用英语记录了一位职业女演员的865次情感话语(203惊讶,273愤怒,255中立和134高兴),每次持续时间为3到6秒。时间对齐分析器用于计算音频中每个音素和每个单词的持续时间。根据对齐结果,我们将单词序列和音素序列分别表示为 w = { w t } t = 1 T w=\left\{w_{t}\right\}_{t=1}^{T} w={wt}t=1T 和 p h = { p h t } t = 1 T p h=\left\{p h_{t}\right\}_{t=1}^{T} ph={pht}t=1T ,其中 w t w_{t} wt 和 p h t p h_{t} pht 是在第T帧发出的单词和音素。通过这种方式,我们构建了一个高保真的Mocap数据集, 包括 m m o u , m u p p , m h e d , w m^{m o u}, m^{u p p}, m^{h e d}, w mmou,mupp,mhed,w 和 p h p h ph,然后用于训练与说话人无关的生成器。另一个中文数据集(925个3到6秒的话语)也同样建立起来。这两个数据集都是为研究目的发布的。
3.2 嘴动画生成器
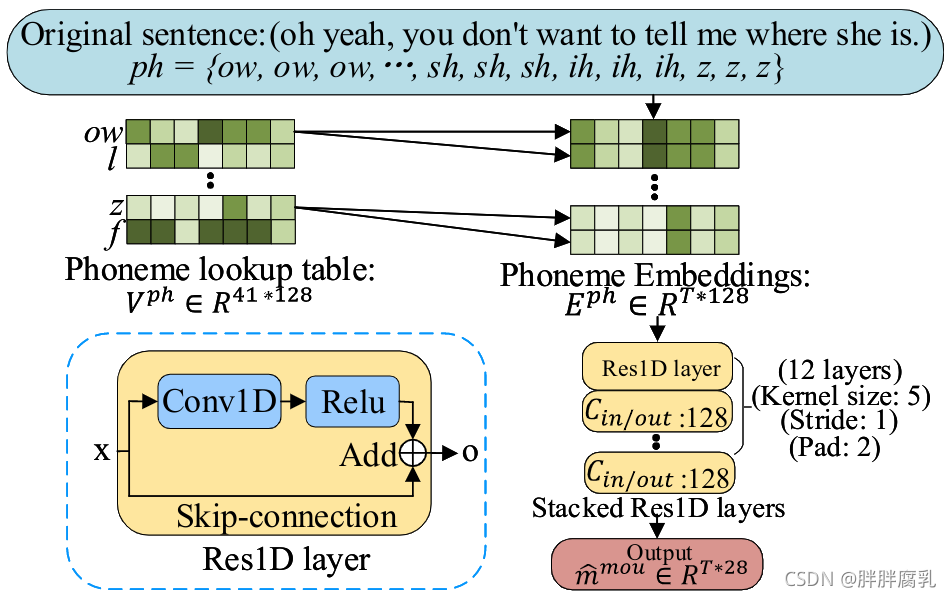
图4:嘴巴动画生成器
由于口腔动画主要用于发声音素而不是语义结构, G m o u G^{mou} Gmou 学习从 p h ph ph 到 m m o u m^{mou} mmou 的映射,忽略 w w w ,如图4所示。第一步是将 p h ph ph 从音素空间转换成更灵活的空间中的嵌入向量 E p h E^{ph} Eph。我们构建了一个可训练的查找表(Tang等人,2014年) V p h V^{ph} Vph 以满足目标,该表是在训练阶段随机初始化和更新的。然后,叠加的Res1D层接收 E p h E^{ph} Eph 作为输入,并根据共同发音效应输出合成嘴参数序列 m ^ m o u {\hat{m}^{mou}} m^mou。为了便于并行计算,我们设计了基于CNN而非LSTM的结构。
我们将L1损失和LSGAN损失(Mao等人,2017年)用于训练 G m o u G^{mou} Gmou。L1损失写为:
L 1 mou = 1 T ∑ i = 1 T ( ∥ m i mou − m ^ i mou ∥ 1 ) L_{1}^{\text {mou }}=\frac{1}{T} \sum_{i=1}^{T}\left(\left\|m_{i}^{\text {mou }}-\hat{m}_{i}^{\text {mou }}\right\|_{1}\right) L1mou =T1i=1∑T(∥mimou −m^imou ∥1)
这里 m i m o u m_{i}^{m o u} mimou 和 m ^ i m o u \hat{m}_{i}^{m o u} m^imou分别是第 i i i 帧的实向量和生成向量。对抗性损失表示为:
L a d v m o u = arg min G m o u max D mou L G A N ( G mou , D mou ) L_{a d v}^{m o u}=\arg \min _{G^{m o u}} \max _{D^{\text {mou }}} L_{G A N}\left(G^{\text {mou }}, D^{\text {mou }}\right) Ladvmou=argGmouminDmou maxLGAN(Gmou ,Dmou )
灵感来自于面片鉴别器的想法 (Isola et al. 2017),
D
mou
D^{\text {mou }}
Dmou 应用于混合形状的时间主干,它也由堆叠的 Res1D 层组成。目标函数写为:
L
(
G
m
o
u
)
=
L
a
d
v
m
o
u
+
λ
m
o
u
L
1
m
o
u
L\left(G^{m o u}\right)=L_{a d v}^{m o u}+\lambda_{m o u} L_{1}^{m o u}
L(Gmou)=Ladvmou+λmouL1mou
3.3 上脸/头部姿势生成器
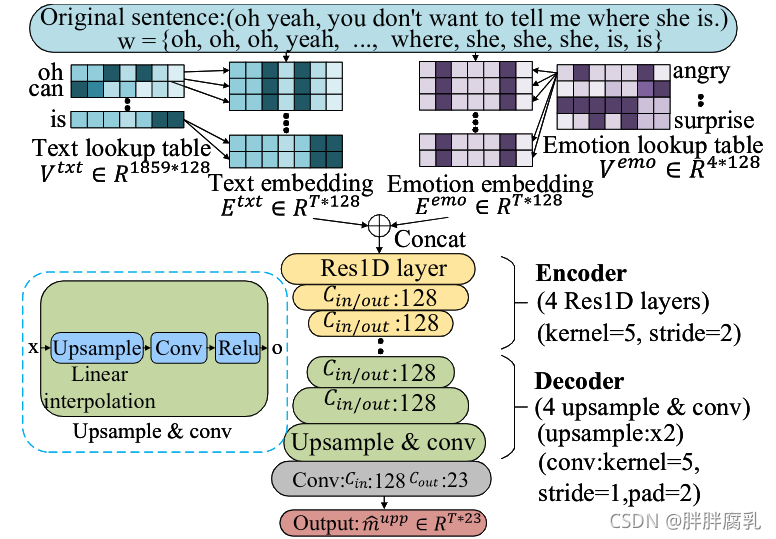
图 5:上面部表情生成器。
虽然嘴巴运动有助于语音协同发音,但上面部表情和头部运动往往会传达情绪、意图和语音节奏。因此, G u p p G^{upp} Gupp 和 G h e d G^{hed} Ghed 旨在从 w w w 而不是 p h ph ph 捕获更长时间的依赖关系。它们共享相同的网络并且与 G m o u G^{mou} Gmou 的网络不同,如图 5 所示。与 V p h V^{ph} Vph 类似,一个可训练的查找表 V t x t V^{txt} Vtxt 将 w w w 映射到嵌入向量 E t x t E^{txt} Etxt。为了生成具有一致情感的 m u p p m^{upp} mupp,情感标签(惊喜、愤怒、中性、幸福)要么由文本情感分类器检测(Yang 等人,2019 年),要么明确分配给特定的情感类型。另一个可训练的查找表 V e m o V^{emo} Vemo 将情感标签投影到嵌入向量 E e m o E^{emo} Eemo。 E t x t E^{txt} Etxt 和 E e m o E^{emo} Eemo 被馈送到编码器-解码器网络以合成 m u p p m^{upp} mupp 。受益于大的感受野,编码器-解码器结构捕获了单词之间的长期依赖关系。
由于从文本合成 m u p p m^{upp} mupp 是一对多映射,L1 损失被 SSIM 损失取代(Wang 等人,2004 年)。 SSIM 模拟人类视觉感知,具有提取结构信息的优点。我们扩展 SSIM 以分别对每个参数执行,即 SSIM-Seq 损失,公式为
L S u p p = 1 − 1 23 ∑ i = 1 23 ( 2 μ i μ ^ i + δ 1 ) ( 2 cov i + δ 2 ) ) ( μ i 2 + μ ^ i 2 + δ 1 ) ( σ i 2 + σ ^ i 2 + δ 2 ) ) L_{S}^{u p p}=1-\frac{1}{23} \sum_{i=1}^{23} \frac{\left.\left(2 \mu_{i} \hat{\mu}_{i}+\delta_{1}\right)\left(2 \operatorname{cov}_{i}+\delta_{2}\right)\right)}{\left.\left(\mu_{i}^{2}+\hat{\mu}_{i}^{2}+\delta_{1}\right)\left(\sigma_{i}^{2}+\hat{\sigma}_{i}^{2}+\delta_{2}\right)\right)} LSupp=1−231i=1∑23(μi2+μ^i2+δ1)(σi2+σ^i2+δ2))(2μiμ^i+δ1)(2covi+δ2))
μ i / μ ^ i \mu_{i} / \hat{\mu}_{i} μi/μ^i和 σ i / σ ^ i \sigma_{i} / \hat{\sigma}_{i} σi/σ^i 表示实数/合成 mupp 第 i i i 维的均值和标准差, cov i \operatorname{cov}_{i} covi 是协方差。 δ 1 \delta_{1} δ1 和 δ 2 \delta_{2} δ2 是两个小常数。 GAN 损失表示为:
L adv upp = arg min G u p p max D u p p L G A N ( G upp , D upp ) L_{\text {adv }}^{\text {upp }}=\arg \min _{G^{u p p}} \max _{D^{u p p}} L_{G A N}\left(G^{\text {upp }}, D^{\text {upp }}\right) Ladv upp =argGuppminDuppmaxLGAN(Gupp ,Dupp )
其中
D
u
p
p
D^{u p p}
Dupp 与
D
mou
D^{\text {mou }}
Dmou 共享相同的结构。目标函数写为:
L
(
G
u
p
p
)
=
L
a
d
v
u
p
p
+
λ
u
p
p
L
S
u
p
p
L\left(G^{u p p}\right)=L_{a d v}^{u p p}+\lambda_{u p p} L_{S}^{u p p}
L(Gupp)=Ladvupp+λuppLSupp
G hed G^{\text {hed }} Ghed 共享相同的网络和损失,但忽略了 V emo V^{\text {emo }} Vemo 来生成 m hed m^{\text {hed }} mhed ,因为不同情绪下头部姿势的变化不如面部表情的变化显着。
3.4 风格保留人脸关键点生成器
G l d m k G^{ldmk} Gldmk 从参考视频重建 3D 人脸,然后驱动它获得说话人特定的地标图像。多线性 3DMM U ( s , e ) U(s,e) U(s,e) 由形状参数 s ∈ R 60 s \in \mathbb{R}^{60} s∈R60 和表达式参数 e ∈ R 51 e \in \mathbb{R}^{51} e∈R51 构成。线性形状基础取自 LSFM (Booth et al. 2018) 并按奇异值缩放。我们根据Mocap数据集的定义在LSFM上雕刻51个面部混合形状作为表达基础,使 e e e 与 ( m t u p p , m t m o u ) \left(m_{t}^{u p p}, m_{t}^{m o u}\right) (mtupp,mtmou) 一致。采用3DMM拟合方法来估计参考视频的 s s s 。之后,我们使用生成的 m ^ hed , m ^ mou \hat{m}^{\text {hed }}, \hat{m}^{\text {mou }} m^hed ,m^mou 和 m ^ u p p \hat{m}^{u p p} m^upp 驱动特定于说话者的 3D 人脸以获得关键点图像序列。我们之前的实验表明,从地标图像生成的视频和渲染的密集网格在视觉上是无关紧要的,因此我们选择关键点图像来减少渲染器。
此外,说话者可能会使用不同的嘴形来发音相同的单词,例如有些人倾向于张大嘴巴,而人们对不匹配的风格很敏感。同时,通用 m ^ u p p \hat{m}^{u p p} m^upp 和 m ^ h e d \hat{m}^{h e d} m^hed 在实践中在不同的人之间工作得很好。因此,我们重新定位 m ^ m o u \hat{m}^{m o u} m^mou 以保留说话者的风格,同时保持 m ^ u p p \hat{m}^{u p p} m^upp 和 m ^ h e d \hat{m}^{h e d} m^hed 不变。一方面,我们从参考视频中提取时间对齐的文本并使用 G mou G^{\text {mou }} Gmou 生成 m ^ mou \hat{m}^{\text {mou }} m^mou 。另一方面,我们使用 3DMM 从参考视频中估计个性化的 m ˘ mou \breve{m}^{\text {mou }} m˘mou 。通过这种方式,我们获得了发音相同音素的成对嘴形。使用配对数据,可以轻松学习从 m ^ m o u \hat{m}^{m o u} m^mou 到 m ˘ m o u \breve{m}^{m o u} m˘mou 的样式保留映射。具有 MSE 损失的两层全连接网络在我们的实验中运行良好。我们使用映射的 m ˘ mou \breve{m}^{\text {mou }} m˘mou 来生成地标图像。
3.5 逼真的视频生成器
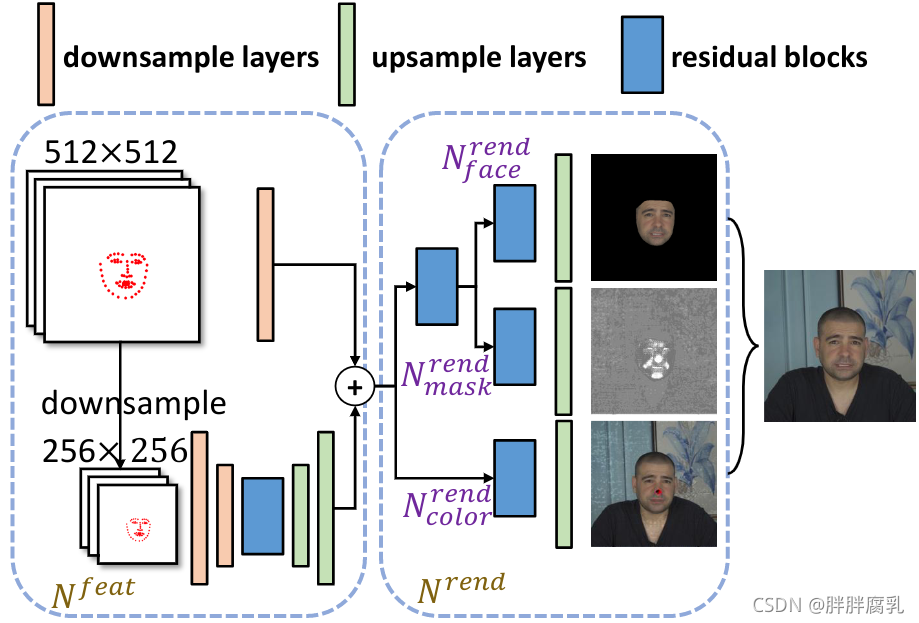
图 6:逼真的视频生成器。

图 7:我们的照片级逼真视频生成器的示例输出。它表明自适应注意力掩码能够将嘴巴和眼睛区域与其他区域区分开来。
G v i d G^{vid} Gvid 从地标图像中逐帧生成说话头视频 { I ^ t } t = 1 T \left\{\hat{I}_{t}\right\}_{t=1}^{T} {I^t}t=1T 。 I ^ t \hat{I}_{t} I^t 它描绘了说话者的完整面部表情、头发、头部和上身姿势,以及第 t t t 帧的背景。考虑到高时间相干性,我们通过在长度为 15 的时间滑动窗口中堆叠地标图像来构建条件时空体积 V V V 作为 G v i d G^{vid} Gvid 的输入。
尽管典型的图像合成网络(Isola et al. 2017; Wang et al. 2018; Yu and Porikli 2016, 2017a,b)能够产生合理的头部图像,但它们的输出往往在高频运动区域模糊,尤其是眼睛和嘴巴区域。可能的解释是眼睛和嘴巴的运动与地标高度相关,而躯干姿势和背景较少,因此将所有部分视为一个整体并不是最好的解决方案。受观察的启发,我们设计了一个自适应注意力结构。如图 6 所示, G v i d G^{vid} Gvid 由特征提取网络 N f e a t N^{feat} Nfeat 和自注意力渲染网络 N r e n d N^{rend} Nrend 组成。为了从高分辨率地标图像中提取特征, N f e a t N^{feat} Nfeat 由两个不同输入尺度的路径组成。两条路径的提取特征按元素相加。 N r e n d N^{rend} Nrend 根据潜在特征渲染会说话的头部图像。为了模拟身体部位的不同相关性,我们设计了三个并行子网络的组合。 N face rend N_{\text {face }}^{\text {rend }} Nface rend 生成目标人脸 I ^ face \hat{I}^{\text {face }} I^face 。 N c l r r e n d N_{c l r}^{r e n d} Nclrrend 预计会计算全局颜色图 I ^ color \hat{I}^{\text {color }} I^color ,包括头发、上身、背景等。 N mask rend N_{\operatorname{mask}}^{\text {rend }} Nmaskrend 产生专注于高频运动区域的自适应注意力融合掩码 M。最终生成的图像 由以下给出:
I ^ t = M ∗ I ^ face + ( 1 − M ) ∗ I ^ color \hat{I}_{t}=M * \hat{I}^{\text {face }}+(1-M) * \hat{I}^{\text {color }} I^t=M∗I^face +(1−M)∗I^color
图7详细展示了我们的注意力掩码。
我们遵循 pix2pixHD (Wang et al. 2018) 的鉴别器,由 3 个多尺度鉴别器
D
1
vid
,
D
2
vid
D_{1}^{\text {vid }}, D_{2}^{\text {vid }}
D1vid ,D2vid 和
D
3
v
i
d
D_{3}^{v i d}
D3vid 组成。它们的输入是
I
^
t
/
I
t
\hat{I}_{t} / I_{t}
I^t/It 和
V
V
V ,其中
I
t
I_{t}
It 是真实的帧。对抗性损失定义为:
L a d v v i d = min G v i d max D 1 v i d , D 2 v i d , D 3 v i d ∑ i = 1 3 L G A N ( G v i d , D i v i d ) L_{a d v}^{v i d}=\min _{G^{v i d}} \max _{D_{1}^{v i d}, D_{2}^{v i d}, D_{3}^{v i d}} \sum_{i=1}^{3} L_{G A N}\left(G^{v i d}, D_{i}^{v i d}\right) Ladvvid=GvidminD1vid,D2vid,D3vidmaxi=1∑3LGAN(Gvid,Divid)
为了捕捉精细的面部细节,我们采用了感知损失(Johnson、Alahi 和 Fei-Fei 2016),遵循 Yu 等人。 (2018):
L perc = ∑ i = 1 n 1 W i H i C i ∥ F i ( I t ) − F i ( I ^ t ) ∥ 1 L_{\text {perc }}=\sum_{i=1}^{n} \frac{1}{W_{i} H_{i} C_{i}}\left\|F_{i}\left(I_{t}\right)-F_{i}\left(\hat{I}_{t}\right)\right\|_{1} Lperc =i=1∑nWiHiCi1∥∥∥Fi(It)−Fi(I^t)∥∥∥1
其中 F i ∈ R W i × H i × C i F_{i} \in \mathbb{R}^{W_{i} \times H_{i} \times C_{i}} Fi∈RWi×Hi×Ci 是 VGG-19 第 i 层的特征图(Simonyan and Zisserman 2014)。匹配低层和高层特征引导生成网络学习细粒度细节和全局部分排列。此外,我们使用 L 1 L_{1} L1 损失来监督生成的 I ^ face \hat{I}_{\text {face }} I^face 和 I ^ t \hat{I}_{t} I^t:
L 1 i m g = ∥ I t − I ^ t ∥ 1 , L 1 f a c e = ∥ I t f a c e − I ^ t f a c e ∥ 1 L_{1}^{i m g}=\left\|I_{t}-\hat{I}_{t}\right\|_{1}, L_{1}^{f a c e}=\left\|I_{t}^{f a c e}-\hat{I}_{t}^{f a c e}\right\|_{1} L1img=∥∥∥It−I^t∥∥∥1,L1face=∥∥∥Itface−I^tface∥∥∥1
根据检测到的地标(Baltrusaitis 等人,2018 年), I face I_{\text {face }} Iface 是从 I t I_{t} It 中裁剪出来的。总损失定义为:
L ( G v i d ) = α L p e r c + β L 1 i m g + γ L 1 f a c e + L a d v v i d L\left(G^{v i d}\right)=\alpha L_{p e r c}+\beta L_{1}^{i m g}+\gamma L_{1}^{f a c e}+L_{a d v}^{v i d} L(Gvid)=αLperc+βL1img+γL1face+Ladvvid
4. 实验及结果
我们在单个 GTX 2080Ti 上使用 PyTorch 实现系统。在 Mocap 数据集上训练说话人独立阶段需要 3 小时。在 5 分钟的参考视频中,针对演讲者特定阶段的培训需要一天时间。我们的方法以每秒 5 帧的速度生成 512 × 512 分辨率的视频。更多的实现细节在补充材料中介绍。我们将所提出的方法与最先进的音频/视频驱动方法进行比较,并评估子模块的有效性。视频比较显示在补充视频中。
5. 局限性

图 15:来自极端参数的失败案例,包括 (a) 上面部表情; (b) 嘴巴表情; © 头部旋转; (d) 头部翻译。
我们的工作有几个局限性。所提出的方法利用了高质量的 Mocap 数据集。我们的方法仅限于产生说英语或中文的说话者,因为我们只捕获了 Mocap 数据集与两种语言。 Mocap 数据的数量也不足以捕获更详细的动作对应关系以及文本输入的语义和句法结构。在不久的将来,我们将记录更多语言的 Mocap 数据并发布用于研究目的。我们的渲染网络无法处理动态背景和复杂的上身运动,例如耸肩、摆臂、驼背、极端头部姿势等。如果预期的表情或头部运动超出参考视频的范围,则生成的视频将退化。情绪对生成的嘴唇和头部动画的影响被忽略。图 15 显示了一些失败案例。未来,我们将致力于解决上述问题。
6. 结论
本文提出了一个基于文本的谈话头视频生成框架。合成的视频显示了情感完整的面部表情、有节奏的头部运动、上半身运动和背景。生成框架可以适应新演讲者的 5 分钟参考视频。我们的方法通过一系列实验进行评估,包括定性评估和定量评估。评估结果表明,我们的方法可以生成高质量的照片逼真的头部谈话视频,并且优于最先进的方法。据我们所知,我们的工作是第一个从时间对齐的文本表示中制作带有情绪面部表情和有节奏的头部运动的完整头部谈话视频。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









