






 本文通过debug方式分析Java项目中自增id的赋值逻辑,指出JDBC标准接口可让应用层框架执行赋值避免二次查询。同时对比了自增主键和UUID的优缺点,自增主键速度快但处理分布式数据易冲突,UUID独立性强但占空间且影响性能,实际应用需结合情况选择。
本文通过debug方式分析Java项目中自增id的赋值逻辑,指出JDBC标准接口可让应用层框架执行赋值避免二次查询。同时对比了自增主键和UUID的优缺点,自增主键速度快但处理分布式数据易冲突,UUID独立性强但占空间且影响性能,实际应用需结合情况选择。
前言
现在的项目实践中,表设计一般采用自增主键,那么在这当中会涉及到数据插入后,获取插入数据主键的一个场景处理。
对于这种情况,mybatis框架做了封装,提供了支持。
代码说明
通过debug方式,跟进执行路径,查看对应逻辑代码。
1、找到执行入口
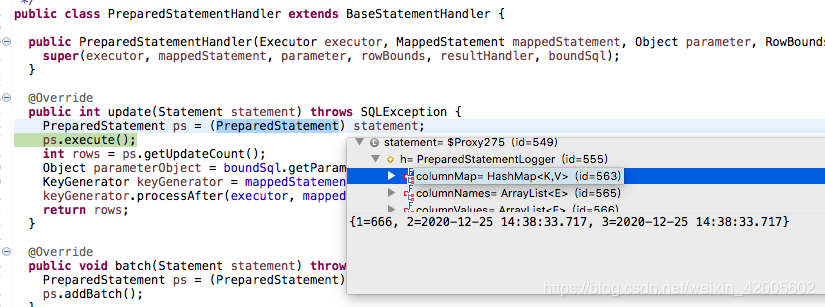
这里的参数赋值有三个,但不包括id的赋值,id是由数据库自增。
这里看到一个KeyGenerator的类型,这个名字name的很好,自说明性很好。
2、看看keyGenerator的执行逻辑
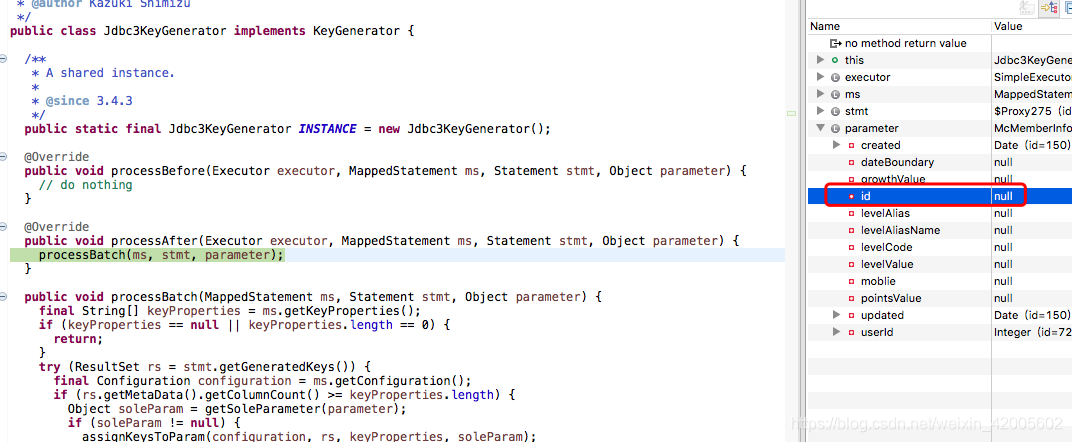
这里可以看出,参数类型的id依然是空,但是上图的sql执行已结束。
3、 跟进逻辑执行
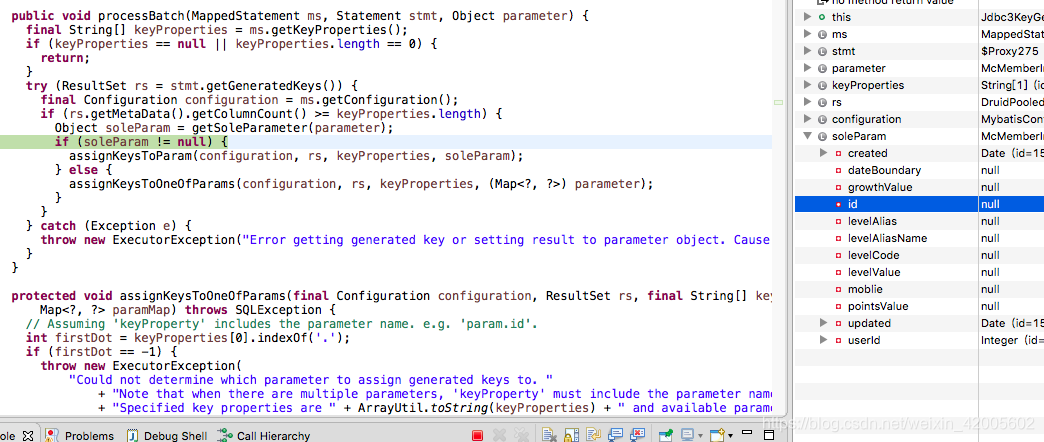
这是一部分逻辑,还没有到,但是看方法名assign,就要到了。
4、继续进入下一层逻辑
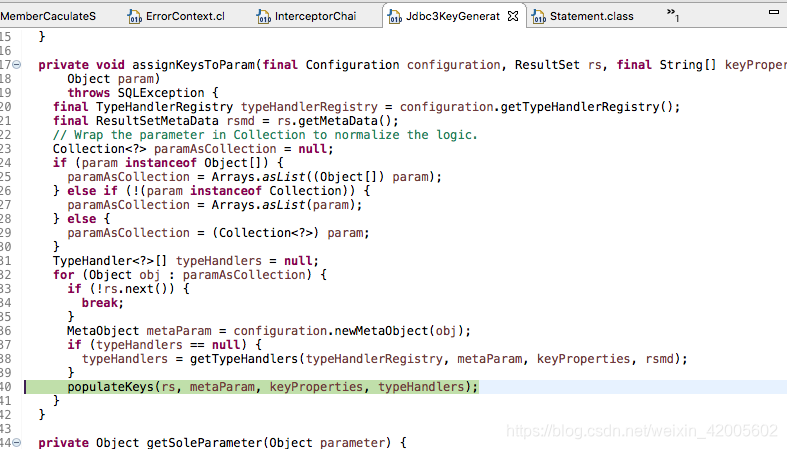
这个时候,id仍然是null
5、继续进入下一层逻辑
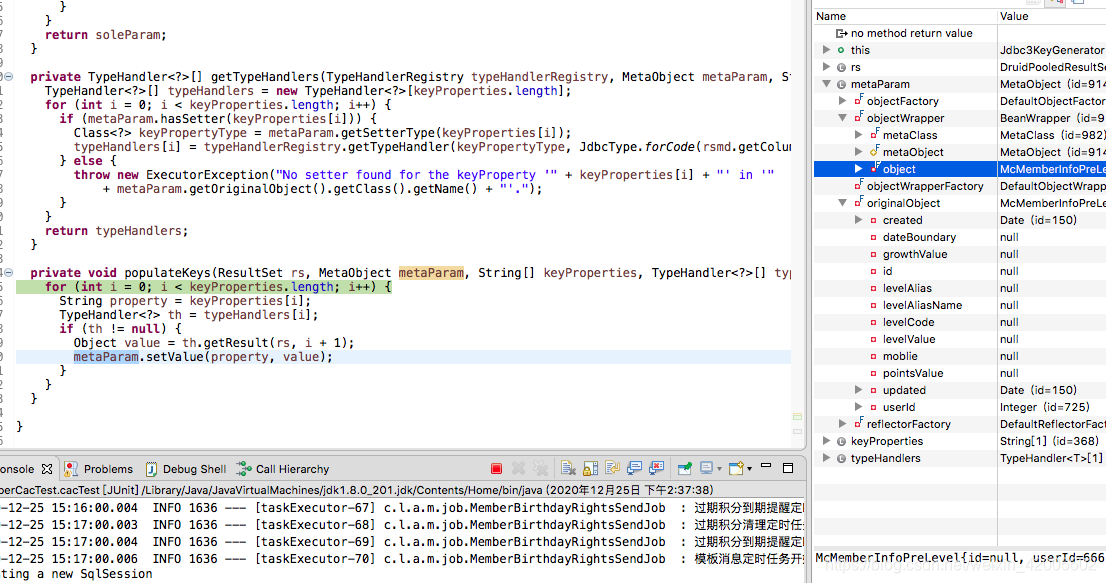
这里我们看到有set的动作,在执行前,id是仍然为null
6、关键取值
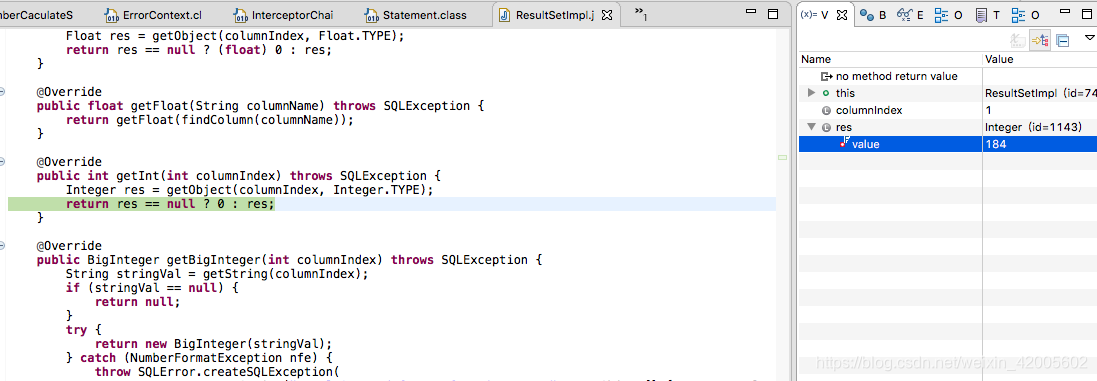
在Object value 的赋值逻辑,看到数据是从rs中获取,值是184
7、关键赋值
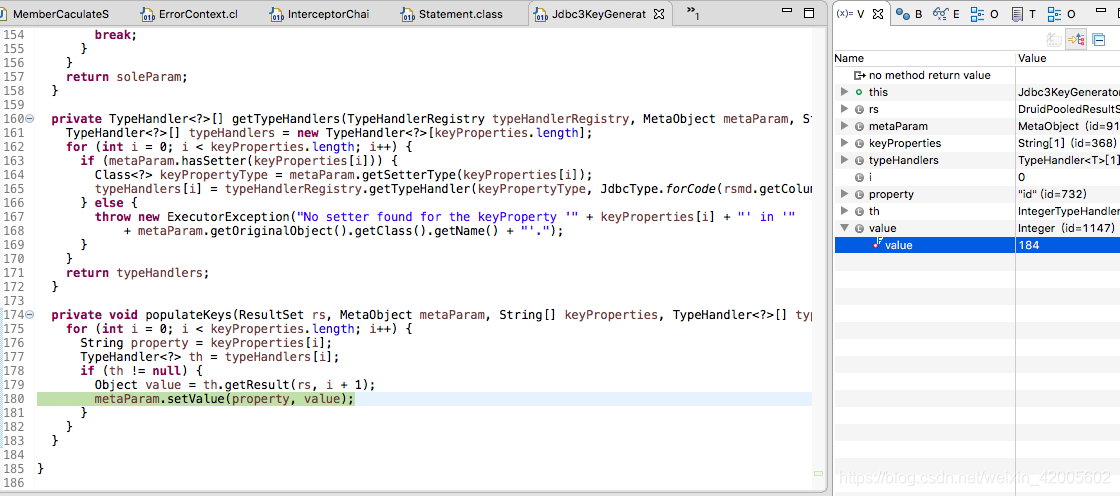
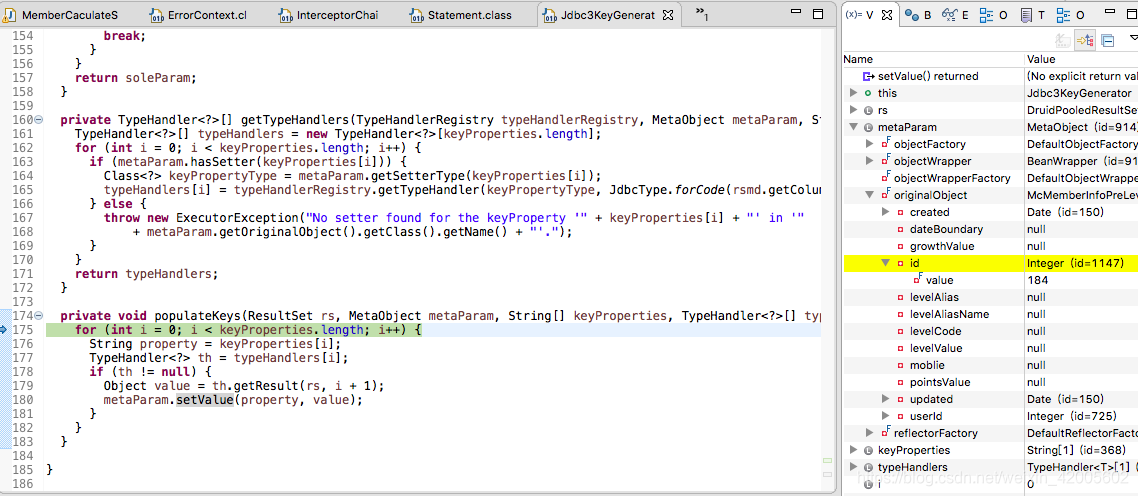
在执行完set后,插入数据的类型对象的id有了值。
到这里自增id赋值就结束了。
总结
自增id的补偿赋值很好的弥补了同自定义id的不足。但是为什么框架能做到呢。看下面的注释说明
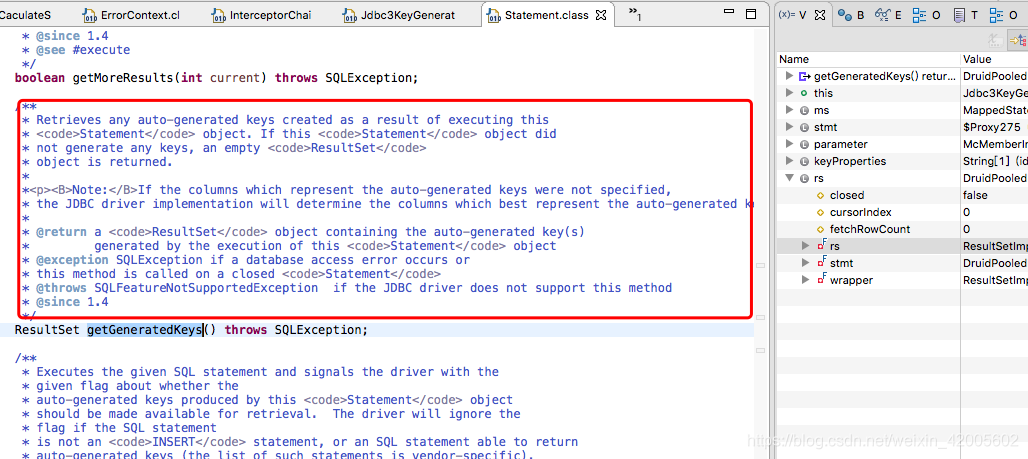
这是JDBC的标准接口,提供了这个口子,在sql执行返回后,可以带上自增id的信息,因此应用层框架可以执行赋值,避免二次查询。
实际项目是采用自增主键,还是自定义赋值主键,需要充分考虑到两者的优缺点同实际的情况结合。优缺点可以参考入下:
这种方式是使用数据库提供的自增数值型字段作为自增主键,它的优点是:
自增主键
这种方式是使用数据库提供的自增数值型字段作为自增主键,优点是:
1、数据库自动编号,速度快,而且是增量增长,按顺序存放,对于检索非常有利;
2、数字型,占用空间小,易排序,在程序中传递也方便;
3、如果通过非系统增加记录时,可以不用指定该字段,不用担心主键重复问题。
缺点 :
1、因为自动增长,在手动要插入指定ID的记录时会显得麻烦,尤其是当系统与其它系统集成时,需要数据导入时,很难保证原系统的ID不发生主键冲突(前提是老系统也是数字型的)。
2、如果经常有合并表的操作,就可能会出现主键重复的情况很难处理分布式存储的数据表。
3、数据量特别大时,会导致查询数据库操作变慢。此时需要进行数据库的水平拆分,划分到不同的数据库中,那么当添加数据时,每个表都会自增长,导致主键冲突。
UUID
优点:
1、能够保证独立性,程序可以在不同的数据库间迁移,效果不受影响。
保证生成的ID不仅是表独立的,而且是库独立的,这点在你想切分数据库的时候尤为重要。
缺点:
1、比较占地方,和INT类型相比,存储一个UUID要花费更多的空间。
2、使用UUID后,URL显得冗长,不够友好。
3、Join操作性能比int要低。
4、UUID做主键将会添加到表上的其他索引中,因此会降低性能。

















 1079
1079





 到【灌水乐园】发言
到【灌水乐园】发言







