









缺点:
1)K 值需要预先设定,而不能自适应,一般选择20,如果数据量小的话,可以调参。
2)当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的 K 个邻居中大容量类的样本占多数。这个缺点是KNN算法不可避免的。
该算法适用于对样本容量比较大的类域进行自动分类。
可以用一个图来描述:
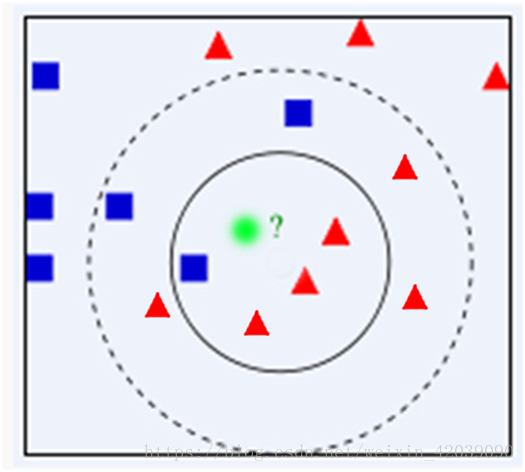
算法步骤:
step.1---初始化距离为最大值
step.2---计算未知样本和每个训练样本的距离dist
step.3---得到目前K个最临近样本中的最大距离maxdist
step.4---如果dist小于maxdist,则将该训练样本作为K-最近 邻样本
step.5---重复步骤2、3、4,直到未知样本和所有训练样本的 距离都算完
step.6---统计K个最近邻样本中每个类别出现的次数
step.7---选择出现频率最大的类别作为未知样本的类别
我们使用的是scikit-learn 库中的neighbors.KNeighborsClassifier 来实行KNN.
(一)、导入包:
from sklearn import neighbors
neighbors.KNeighborsClassifier(n_neighbors=5, weights='uniform',algorithm='auto', leaf_size=30,p=2, metric=’minkowski’, metric_params=None,n_jobs=1)
其中:
(1)Algorithm 是分类时采取的算法,有 {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’},一般情况下选择auto就可以,它会自动进行选择最合适的算法。
(2)当p=1时,距离方法定义为曼哈顿距离,p=2时为欧几里得距离。一般默认值为2。
(二)、fit() 训练拟合,要分为训练集和测试集,可以自己手动分割或者调用train_test_split。
一般形式: train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取train data和testdata,形式为:
X_train,X_test, y_train,y_test = cross_validation.train_test_split(train_data,train_target,test_size=0.4,random_state=0) 参数解释: train_data:所要划分的样本特征集 train_target:所要划分的样本结果 test_size:样本占比,如果是整数的话就是样本的数量 random_state:是随机数的种子。
knn=KNeighborsClassifier()
knn.fit( X_train, y_train)
(三)、预测:
knn.predict(X)
这里输入X一个数组,形式类似于(如果是一个二维特征的话):[ [0,1 ],[2,1]...]
(四)、评估:
neighbors.KNeighborsClassifier.score(X, y, sample_weight=None)
我们一般会把我们的训练数据集分成两类,一个用作学习并训练模型,一列用作测试,这个动能就是学习之后进行测试的功能来看一下准确度。
首先我们先拿我们在机器学习系列中的KNN算法中的电影分裂举例。我们在那个系列中自己实现了一个KNN分类器,采取的是欧几里得的距离,这里我们直接使用sklearn库中的函数来实现KNN算法,大家可以参考两者来看。
import numpy as np
import sklearn
from sklearn import datasets
from sklearn.neighbors importKNeighborsClassifier
X_train =np.array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
y_train=['0','1','1','1']
knn=KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train,y_train)
knn.predict([[5,0],[4,0]])#要注意哦,预测的时候也要上使用数组形式的














 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









