




Abstract
1.通道注意在改善深层卷积神经网络的性能方面提供了巨大的潜能。但是现有的方法都致力于开发更复杂的注意模块,从而增加了计算负担。为了解决性能和复杂度之间的矛盾,本文提出了一种轻量级的注意模块——ECA,该模型只需要k(k≤9)个参数。
2.回顾SENet的通道注意力模块,实证地表明避免降维和适当的跨通道交互对于学习有效的通道注意是重要的。
3.本文提出了两点,分别是:
(1)提出了一种无需降维的局部跨通道交互策略,该策略可以通过快速的一维卷积实现。
(2)提出了一种通道维数函数来自适应地确定一维卷积核的大小,该核大小代表局部交叉通道相互作用的覆盖。
1.Introduction
1.本文关注的一个问题:人们是否能够以更有效的方式学习有效的通道注意。
2.首先回顾一下SENet中的通道注意力模块,输入特征--独立的对每个通道采用全局平均池化--两个非线性的FC--Sigmoid生成每个通道的权重。其中降维发生在FC层,为了避免过高的模型复杂度。实证分析表明,降维会给通道注意力的预测带来负面影响,捕获的通道之间的依赖关系是低效的。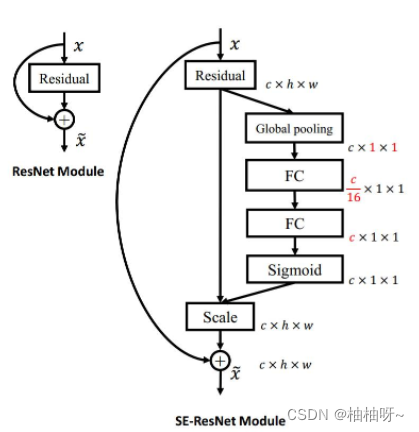
3.避免降维和适当的跨通道交互在通道注意机制的形成中是至关重要的。本文提出了一种适用于深层CNN的高效通道注意模型——ECA。
4.在没有降维的情况下进行通道式全局平均池化之后,ECA通过考虑每个通道及其k个相邻通道来捕获本通道跨通道交互。
5.ECA可以通过大小为k的快速一维卷积来有效实现。核大小 k表示局部跨通道交互的覆盖,即有多少相邻通道参与了本次通道的预测。但是这影响了ECA的效率和效力。解决办法是:提出了一个与通道维度相关的 函数来自适应的确定k。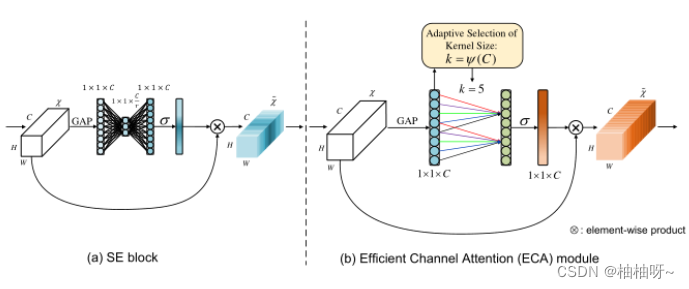
本文的贡献:
1. 证明避免降维和适当的跨通道交互对于学习有效的深层CNN的通道注意是重要的。
2.提出了一种新的高效通道注意模型(ECA),试图为深层CNN开发一个超轻量级的通道注意模块,该模型的复杂度很小,但有明显的改进。
3.在数据集上的实验结果表明,ECA不仅有更低的模型复杂度,而且具有非常有竞争力的性能。
2.Related Work
1.注意模块的发展可以大致分为两个方向:(1)增强特征聚合 (2)通道注意和空间注意结合。
2.ECA的目标是以较低的模型复杂度学习有效的通道注意。
3.ECA模块以捕获局部跨通道交互为目标,与通道局部卷积和通道卷积有一些相似之处;与它们不同的是,我们的方法重点是提出一种核大小自适应的一维卷积来代替通道注意模块中的FC层。与分组可分离卷积和深度可分离卷积相比,我们的方法在较低的模型复杂度下获得了更好的结果。
3.Proposed Method
1.SENet中的通道注意力
这一个卷积块的输出为,分别代表宽,高,通道数(卷积核的个数),通道权重的计算为:
(1)
g(X)是通道全局平均池化(GAP),是sigmoid函数,令y=g(X):
(2)
其中ReLU表示校正后的线性单元,为了避免高模型复杂度,将W1和W2的大小分别重置为。(2)中的降维可以降低模型的复杂度,但它破坏了信道及其权重之间的直接对应关系。(2)首先将通道特征投影到一个低维空间,然后将其映射回去,使得通道和其权重之间的对应关系是间接的。
2.ECA模块
(1)避免降维
比较SE与它的三个变体,这三个变体都没有进行维度的缩减。
①没有参数的SE-Var1仍然优于原始网络,说明信道注意有能力提高DCNNs的性能。
②SE-Var2独立地学习每个通道的权值,略优于SE块,而SE块参数较少。这可能表明,信道及其权重需要直接对应,而避免降维比考虑非线性通道相关性更为重要。
③采用SE层的SE-Var3在SE块中具有比二维FC层更好的降维效果。
(2)局部跨通道相互作用
聚合特征,在没有降维的情况下,通道注意力为:
(3)
关键的区别在于SE-Var3考虑跨通道交互,而SE-Var2不考虑,因此SE-Var3的性能更好。这一结果表明,跨通道交互有利于学习通道注意力。然而,SE-Var3需要大量的参数,这导致很高的模型复杂度,特别是对于大的通道数。
从卷积的角度来看,SE-Var2、SE-Var3和Eq.(5)可以分别视为深度可分离卷积、FC层卷积和群卷积。具有群卷积的SE块(SE-GC)用。过多的组卷积将增加内存访问成本,从而降低计算效率。不同组的SE-GC对SE-Var2没有任何好处,表明它不是捕获局部跨通道交互的有效方案,原因可能是SE-GC完全抛弃了不同群体之间的依赖关系。
本文探索了另一种方法来捕获局部跨通道交互,旨在计算性能和模型复杂度,具体来说,本文使用了一个波段矩阵来学习通道注意力:
让所有通道共享相同的学习参数:
这种策略可以很容易地通过核大小为k的一维卷积实现,即:
该方法被称为ECA模块,该模块只涉及k个参数,具有更低的模型复杂性,通过适当捕获局部的跨通道交互,保证了效率和性能。
(3)局部跨通道相互作用的覆盖范围
因为ECA模块的目标是适当的捕获局部跨通道交互,因此需要确定交互的覆盖范围(即一维卷积核的大小k)。利用分组卷积能成功改善CNN的架构,在固定group数量的情况下,高维通道与长距离卷积成正比。就这个理念,相互作用的覆盖范围(k)与通道维数C成正比是合理的。所以设:
最简单的映射是一个线性映射,即。但由于线性函数对于某些相关特征的局限性,另一方面,由于通道维数通常是2的指数倍,所以,我们将线性函数
扩展为非线性函数,从而引入一个可能的解。这里采用以2为底的指数函数来表示非线性映射关系:
然后,给定通道维数C,卷积核大小k可以自适应地确定:
通过映射ψ,高维通道具有较长的相互作用范围,而低维通道通过非线性映射具有较短的相互作用范围。
3.ECA应用于深度卷积神经网络
ECA模块使用不降维的GAP聚合卷积特征后,首先自适应地确定核大小k,然后进行一维卷积,最后使用sigmoid函数来学习通道注意。pytorch代码为:
def EfficientChannelAttention(x,gamma=2,b=1):
#x:input features with shape [N,C,H,W]
#gamma,b:parameters of mapping function
N,C,H,W =x.size()
t=int(abs((log(c,2)+b)/gamma))
k=t if t%2 else t+1
avg_pool = nn.AdaptiveAvgPool2d(1)
conv = nn.Conv1d(1,1,kernel_size=k,padding=int(k/2),bias=False)
sigmoid = nn.Sigmoid()
y = avg_pool(x)
y = conv(y.squeeze(-1).transpose(-1,-2))
y = y.transpose(-1,-2).unsqueeze(-1)
y = sigmoid(y)
return x * y.expend_as(x)4.Experiments
1.实验细节
数据集:ImageNet
1.骨干模型:ResNet-50,ResNet-101,ResNet-152,MobileNetV2。
2.数据增强:通过随机水平翻转将输入图像随机裁剪为224×224。
3.超参数:采用随机梯度下降法(SGD)进行优化,权值衰减为1e-4,动量为0.9,小批量为256。通过将初始学习率设置为0.1(每30个epoch减少10倍),所有模型都在100个epoch内进行训练。对于使用我们的ECA培训MobileNetV2。在400个epoch内使用SGD训练网络,权重衰减为4e-5,动量为0.9,小批量大小为96。初始学习率设置为0.045,线性衰减率为0.98%。
数据集:MS Coco
1.骨干模型:ResNet-50,ResNet-101,FPN
2.数据设置:输入图像的较短一侧调整为800
3.超参数:使用重量衰减为1e-4、动量为0.9、小批量大小为8(4个GPU,每个GPU有2个图像)的SGD对所有型号进行优化。将学习率初始化为0.01,并分别在8和11个epoch后将学习率降低10倍。
2.在ImageNet-1K上的图像分类
首先评估内核大小对我们的ECA模块的影响,并验证我们的方法自适应确定内核大小的有效性。
(1)核大小(k)对ECA模块的影响
评估了k对ECA模块的影响,并验证了所提出的核大小自适应选择的有效性。
1.当k在所有卷积块中固定时,对于ResNet-50和ResNet-101,ECA模块分别在k=9和k=5时获得最佳结果。
2.由于ResNet-101具有更多的中间层,这些中间层决定了ResNet-101的性能,因此它可能更喜欢较小的内核大小。
3.不同的深层CNN具有不同的最优k个数,并且k对ECA-Net的性能有明显的影响。
4.自适应核大小选择试图为每个卷积块找到最优的k个数,这样可以减轻深层CNN深度的影响,避免人工调整参数k,而且通常会带来进一步的改进,证明了自适应选择核大小的有效性。
5.不同k数值的ECA模块均优于SE模块,表明避免降维和局部跨通道交互确实对学习通道注意有正向影响。
(2)使用不同深度cnn的比较
ResNet、ResNet-101、ResNet-152、MobileNetV2:SENet,CBAM,A2-Nets,AA-Net,GSoP-Net1和GCNet;ECANet在获得了较低的模型复杂性的同时,获得了更好或具有竞争力的结果。
(3)与其他CNN模型的比较
ResNet-200,Inception-v3,ResNeXt,DenseNet;ECA-Net的性能优于最先进的cnn,同时有利于更低的模型复杂度。
3.在MSCOCO上的对象检测
1.骨干网络:Faster RCNN、Mask RCNN、RetinaNet
2.比较:ResNet、SENet
(1)Faster RCNN:明显地提高目标检测的性能
(2)Mask RCNN:ECA模块可以很好地推广到目标检测,更适合检测小目标。
(3)RetinaNet:ECA模块比原始的ResNet带来了明显的改进,同时使用较低的模型复杂度优于SE块。特别是,我们的ECA模块为小物体获得了更多的增益,而这些物体通常更难被检测到。
4.在MSCOCO上的实例分割
ECA模块比原始ResNet取得了显著的增益,同时在模型复杂度较低的情况下表现优于SE块。这些结果验证了我们的ECA模块对各种任务具有良好的泛化能力。
5.Conclusion
1.本文关注于学习具有低模型复杂度的深度cnn的有效通道注意。
2.提出了一种有效的信道注意(ECA)模块,该模块通过快速的一维卷积产生信道注意,其核大小可以通过信道维数的非线性映射自适应地确定。
3.实验结果表明,我们的ECA是一个非常轻量级的即插即用块,可以提高各种深度CNN架构的性能,包括广泛使用的ResNets和轻量级的MobileNetV2。
4.我们的ECA-Net在目标检测和实例分割任务中表现出良好的泛化能力。


















 3787
3787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









