







目录:
1. 基本概念
树是一种应用十分广泛的数据结构,最常见的就是包括 UNIX、DOS 在内的许多常用操作系统的目录结构,下图是 UNIX 文件系统中的一个典型目录:
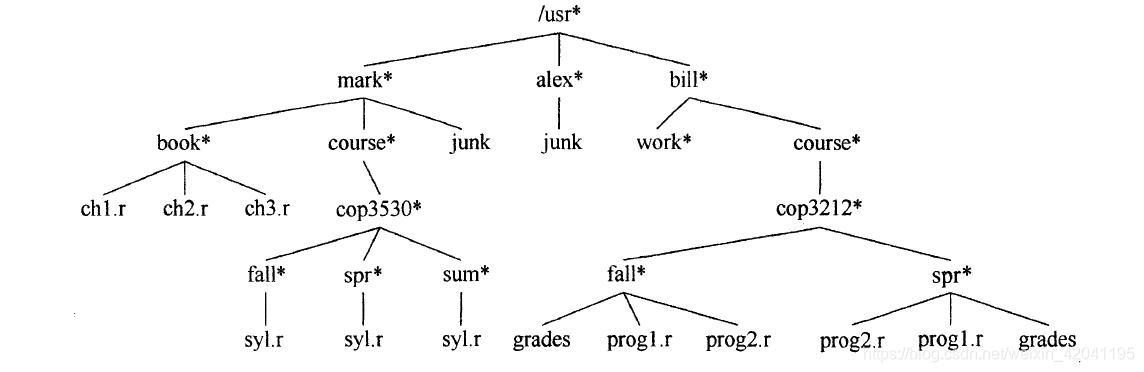
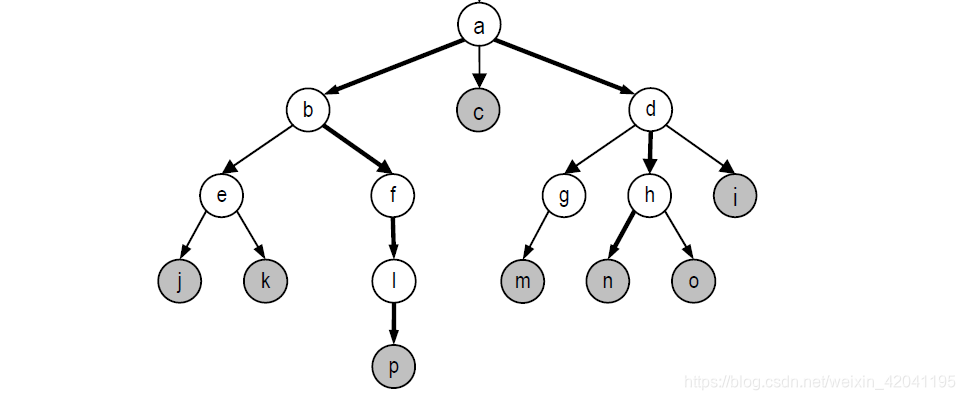
从图中我们可以对此数据结构有一个大致的了解,与我们日常生活中的树类似,有一个“根”以及众多的分支、叶子。为了更好的了解这一数据结构,我们以表格的形式给出一些与树相关的常用的术语,并配合下面的图片对其进行解释。
| 术语 | 意义 |
|---|---|
| 节点 | 所谓节点,就是指树中的元素,图中的每一个圆圈就代表一个节点。 |
| 父亲/孩子 | 如图中所示,a 结点是 b 节点的“直接上邻”,则称 a 节点是 b 节点的父亲,相应的 b 节点就是 a 节点的儿子。 |
| 祖先/后代 | 某节点的祖先/后代包括两部分:1. 该节点本身。2. 它的父亲的祖先/后代(例如 a、b、e 都是节点 e 的祖先;e、j、k 都是节点 e 的后代)。 |
| 子树 | 将树中任意一节点 v 的所有后代,按原有的结构组织在一起,也构成了一棵树,将此树称作“以 v 为根的子树”。 |
| 根节点 | 位于“最上层”的节点,如图中的 a 节点。 |
| 节点的深度 | 某节点的深度取决于它和根节点的“相对层次差距”,如图中根节点 a 的深度为 0 (深度为 0 的节点有且只有一个,就是根节点),位于根节点下一层的节点 b、c、d 深度为1,以此类推。 |
| 树的深度(高度) | 树中所有节点的最大深度,称作树的深度或高度(注意与节点的深度和高度进行区分)。图中的树的深度(高度)为 4。 |
| 内部节点/外部节点(叶子) | 至少拥有一个孩子的节点称作内部节点,没有任何孩子的节点称作外部节点(叶子)。 |
| 节点的高度 | 若“以节点 v 为根的子树”的深度(高度)为 h,则称节点 v 的高度为 h。 |
| 度 | 某节点孩子的数目,称作它的度(如图中 a 节点的度为 3)。 |
| 有序树 | 在树 T 中,若在每个节点的所有孩子之间都可以定义某一线性次序,则称 T 为一棵有序树。 |
| m 叉树 | 每个内部节点均为 m 度的有序树,称作 m 叉树。 |
2. 树的 ADT(Abstract Data Type)
树这一抽象类型需要支持以下的基本方法:
| 方法 | 功能描述 |
|---|---|
| getElement() | 返回存放于当前节点处的对象 |
| setElement(e) | 将对象e 存入当前节点,并返回其中此前所存的内容 |
| getParent() | 返回当前节点的父节点 |
| getFirstChild() | 返回当前节点的长子(最左边的孩子) |
| getNextSibling() | 返回当前节点的最大弟弟(同一层次中右边相邻的节点) |
3. 二叉树
正如第一节表格中所定义的,二叉树就是指每个内部节点均为 2 度的有序树。由于它的节点至多有两个孩子,因此每个节点的孩子(如果存在的话)可以左、右区分,分别称其为左孩子和右孩子。由于二叉树在结构上具有特殊性,再次对其 ADT 稍作修改,将原本的 getFirstChild() 方法和 getNextSibling() 方法,修改为以下两个方法。
| 方法 | 功能描述 |
|---|---|
| getLeftChild() | 返回当前节点的左孩子 |
| getRightChild() | 返回当前节点的右孩子 |
对一组数据进行遍历是我们在编程中经常会做的一件事情,对于一般的树而言,其常见的遍历方式有:前序遍历、后续遍历和层次遍历。如果将范围限制在二叉树这一结构的话,还可以定义一种在某些场合十分有用的遍历方式——中序遍历(仅限于二叉树)。树的遍历最自然的实现方式就是通过递归实现,下面将介绍如何利用递归,实现二叉树的四种遍历方式。
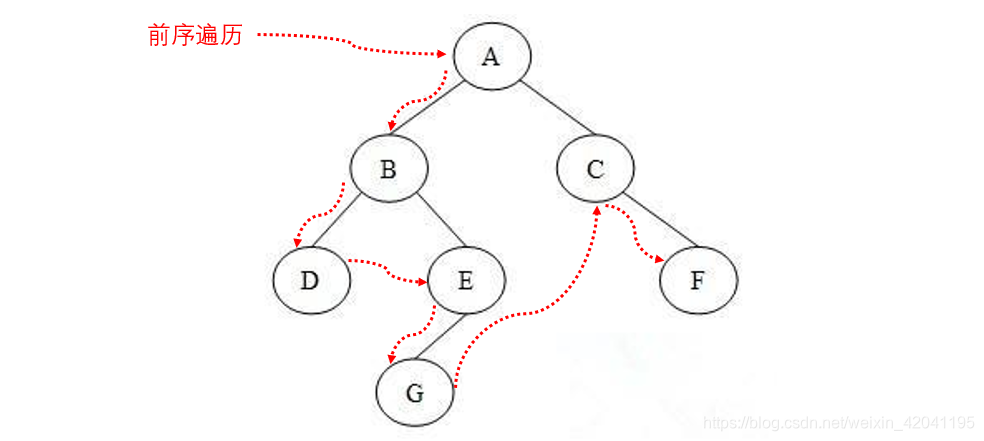
3.1 前序遍历
前序是指对数据的操作是“前序”的,即先访问节点并对其进行相应操作,然后才会继续访问后续的节点。
算法:PreorderTraversal(v)
输入:树节点v
功能:按“前序”对以节点v为根的子树进行遍历
具体实现:{
if (v != null) {
访问节点v并对其进行相应的操作
PreorderTraversal(v.getLeftChild()); // 递归的对左子树进行前序遍历
PreorderTraversal(v.getRightChild()); // 递归的对右子树进行前序遍历
}
}
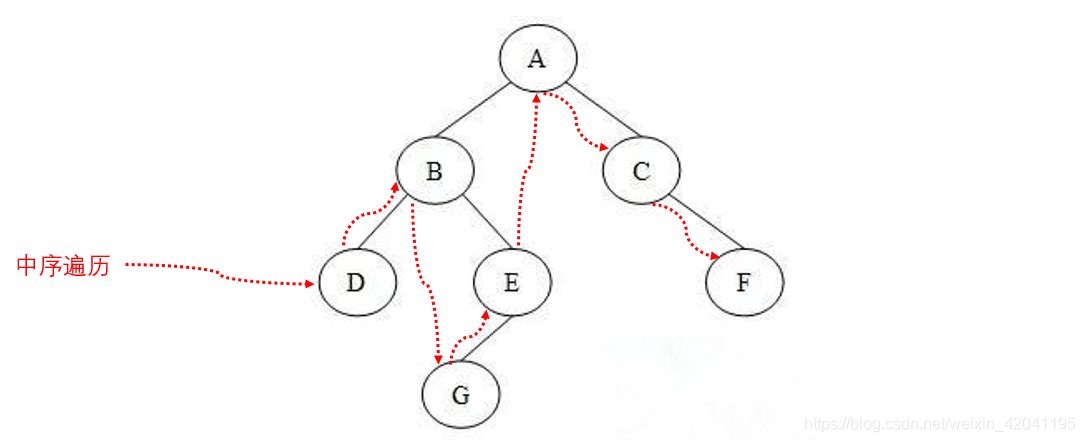
3.2 中序遍历
中序遍历是指先访问左子树,再访问当前节点,最后在访问右子树。
算法:InorderTraversal(v)
输入:树节点v
功能:按“中序”对以节点v为根的子树进行遍历
具体实现:{
if (v != null) {
InorderTraversal(v.getLeftChild()); // 递归的对左子树进行中序遍历
访问节点v并对其进行相应的操作
InorderTraversal(v.getRightChild()); // 递归的对右子树进行中序遍历
}
}
3.3 后续遍历
后续是指对数据的操作是“后续”的,即先访问左右子树,然后才会访问当前的节点。
算法:PostorderTraversal(v)
输入:树节点v
功能:按“后续”对以节点v为根的子树进行遍历
具体实现:{
if (v != null) {
PostorderTraversal(v.getLeftChild()); // 递归的对左子树进行后续遍历
PostorderTraversal(v.getRightChild()); // 递归的对右子树进行后续遍历
访问节点v并对其进行相应的操作
}
}
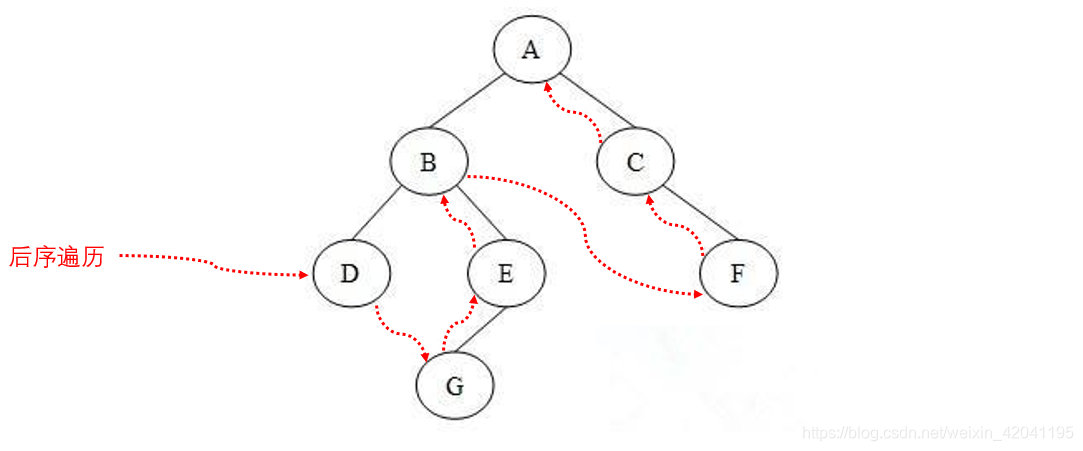
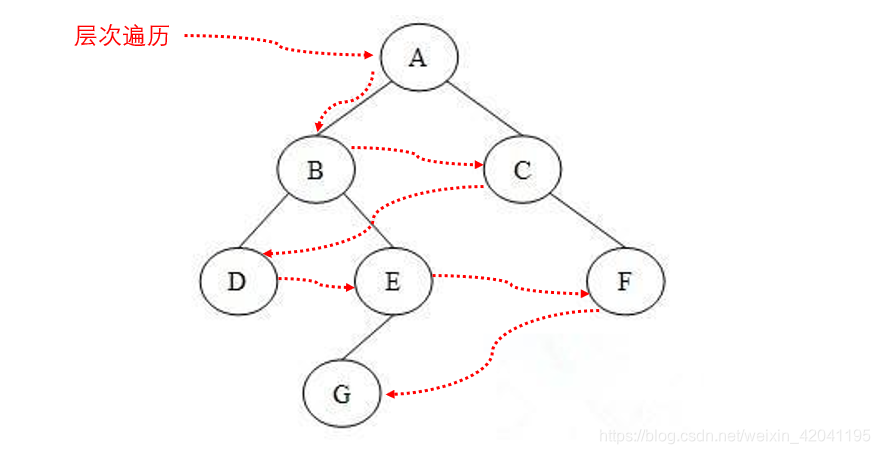
3.4 层次遍历
层次遍历是指从树的最上层(根节点)开始,按照次序依此对每一层的节点进行遍历。层次遍历可以借助队列实现。
算法:LevelorderTraversal(v)
输入:树节点v
功能:按“层次”对以节点v为根的子树进行遍历
具体实现:{
if (v != null) {
Queue queue = new Queue(); // 创建一个队列
queue.enqueue(v); // 根节点入队
while(!queue.isEmpty()) { // 队列非空
Node node = queue.dequeue(); // 取出队列的首节点
访问节点node并对其进行相应的操作
// node节点的孩子入队
if(node.getLeftChild() != null) {
queue.enqueue(node.getLeftChild());
}
if(node.getRightChild() != null) {
queue.enqueue(node.getRightChild());
}
} // while
} // if
}
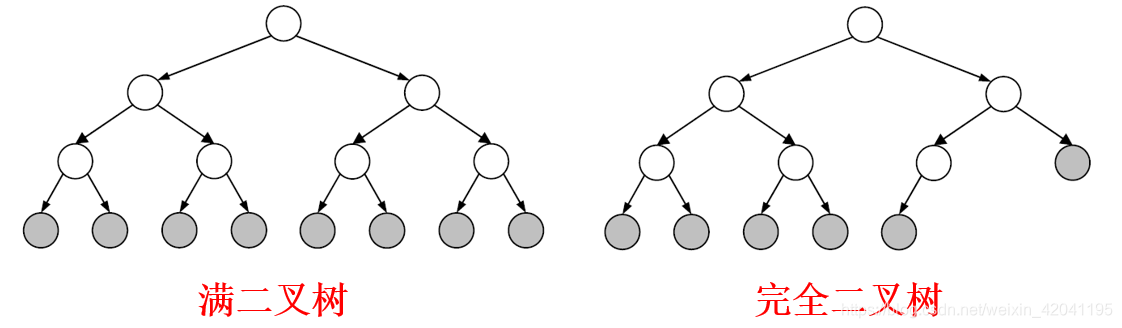
4. 真二叉树、满二叉树和完全二叉树
| 术语 | 意义 |
|---|---|
| 真二叉树 | 指不含 1 度节点的二叉树,也就是说,真二叉树所有内部节点的度均为 2(有两个孩子)。 |
| 满二叉树 | 若二叉树中所有叶子的深度完全相同,则称之为满二叉树。 |
| 完全二叉树 | 若在一棵满二叉树中,从最右侧起将相邻的若干匹叶子节点摘除掉,将摘除后所得到的二叉树称作完全二叉树。 |
不难看出,对于由 n 个节点构成的完全二叉树,其深度(高度) h = [log2(n)]([x]表示不超过实数x的最大整数)。
对于一组数据而言,数据查找一种是频率较高的操作,如何快速的找到指定的数据一直是探讨的探讨的重点之一。如果将数据组织成类似完全二叉树的结构(有同等级的高度即可),并让其中数据的排列带有一定的规则,即查找时可以根据当前节点中的某些参数,确定查找的数据是处于当前节点的左子树还是右子树。在此结构中,我们最多只需要查找 h + 1(h 为树的深度)次,就可以确定查找的数据的位置,也就是说,查找的时间复杂度被控制在了 O(log2(n))!
二叉查找树
关于树在查找中的应用,可以查看: 查找树(一):初探二叉查找树.














 692
692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









