







哈希表(hash table)是根据关键码(key)值(value)进行直接访问的数据结构
hash table的查询速度非常快,时间复杂度几乎是o(1)。如果需要在一秒种内查找上千条记录通常使用哈希表(例如拼写检查器)哈希表的速度明显比树快,树的操作通常需要O(N)的时间级。
基本思想:将元素的关键字k通过函数f映射到存储地址p,即p=f(k). 创建哈希表时按上述规则将关键字为k的元素存到p=f(k)位置,查找元素时再利用哈希函数计算出该元素的位置,从而实现按关键字存储元素。
但是哈希表存在冲突的情况,即p=f(k1)=f(k2),但是k1≠k2.实际中冲突不可避免,只能设法减少冲突。
- 生成哈希函数方法
(1)数字分析法
若已知关键字集合,并且每个关键的位数比哈希表的地址码位数多,可从中选取分布均匀的几位构成哈希地址。
(2)平方取中法
求关键字的平方扩大差别,再根据表长度取中间几位数作为哈希地址。
(3)分段叠加法
将关键字按照哈希地址的位数分为相等的各段,若最后一段较短舍去,然后将上述各段位数对其相加,最后舍弃最高进位的结果为该关键字的哈希地址。
包括移位法和折叠法,移位法将位数相等的各段各位对齐相加,舍弃最高进位,得到哈希地址。折叠法将位数相等的各段的奇数段正序 偶数段逆序,然后各段相加,舍弃最高进位,得到哈希地址。
例如:key=12360324711202065,将该关键字分为3位一段,舍去65,分别用两种方法相加得到哈希地址。
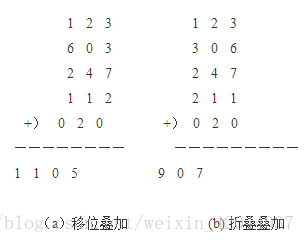
http://www.360doc.com/content/14/0721/09/16319846_395862328.shtml[图片来源]
(4)除留余数法
表长为m,用表长m去除关键字,取其余数作为哈希地址即 h(key)=key%m,其中m最好为素数,最重要的就是选取m。
例如,已知带散列的元素为(18,25,47,65,11,4,23),若取m=13,则此时哈希表为

由于选取的m较合适,上述过程没有冲突。
(5)伪随机数法
取关键字的塑基函数作为它的哈希地址,即h(key)=random(key).
- 处理冲突的方法
主要用的有两种:开放地址法和链地址法(也叫拉链法),另外两种方法不常用:再哈希法和建立公共溢出区
(1)开放地址法
hi=(h(key)+di)%m ,1<=i<=m-1,di为增量序列,m为表长
增量序列di有不同方法生成:
线性探查再散列
di=1,2,3……,m-1
一般形式: hi=(h(key)+di)%m二次探测再散列
di=1^2,-1^2,2^2,-2^2……k^2,-k^2 (k<=m/2)伪随机探测再散列法
di=伪随机数序列
实例:如下是一个哈希冲突的处理过程

如下是按上述三种方法处理冲突的方法:
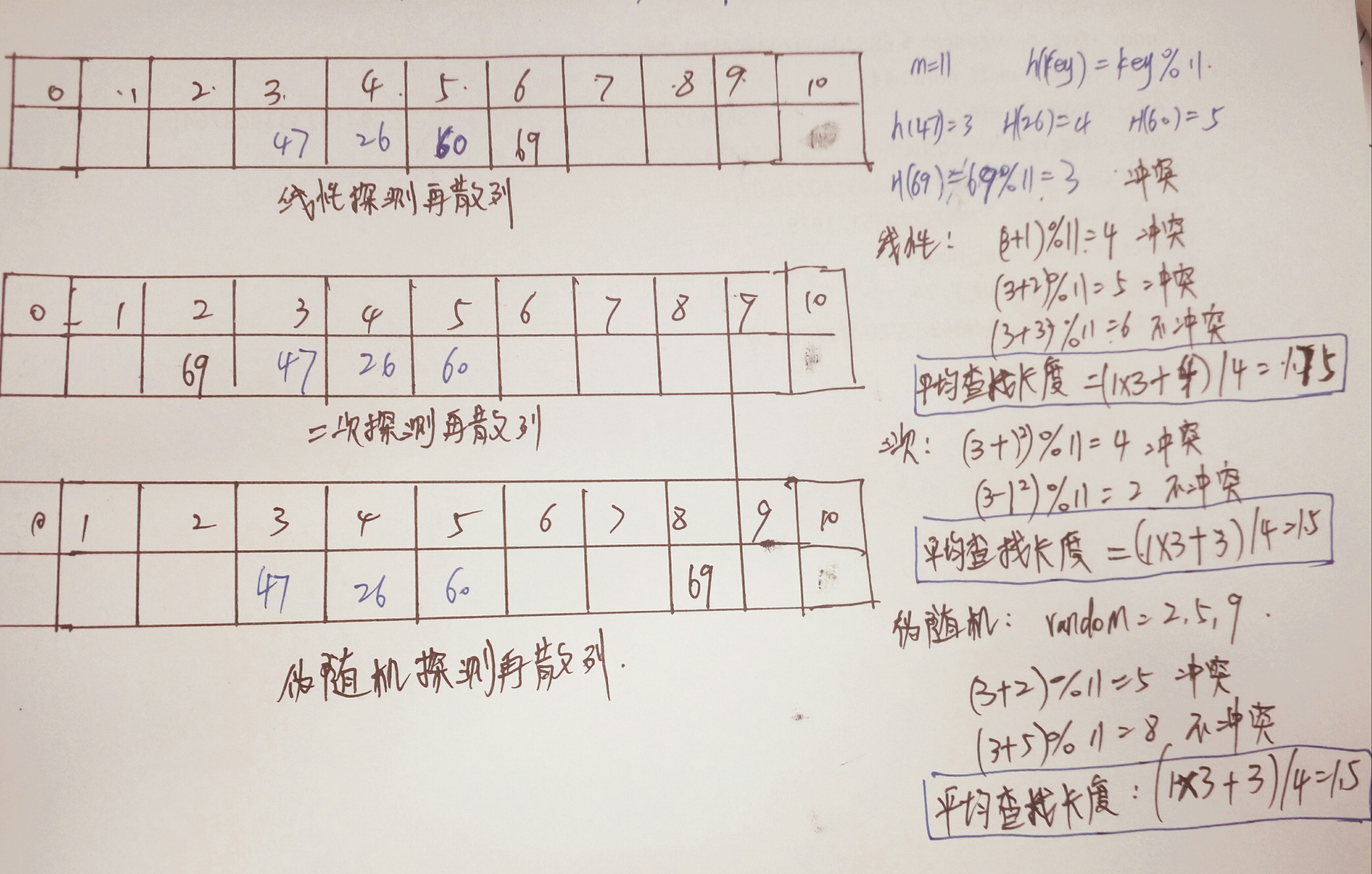
由上述例子可以看出,线性探测再散列容易发生“二次聚类”。但是线性探测再散列的优点:只要哈希表有空余就一定能找到一个不冲突的哈希地址,而二次探测再散列和伪随机数探测再散列不一定。
(2)链地址法(拉链法)
基本思想:将元素为同一地址i的通过单链表链接,将单链表的头指针放在哈希表的第i个单元中,因而插入和删除较方便。
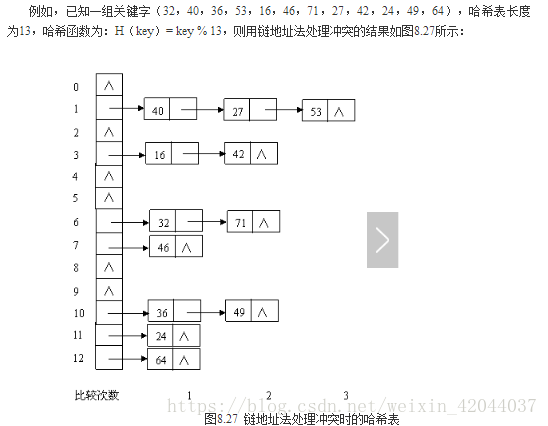
平均查找长度ASL=(1*7+2*4+3*1)/12=1.5
(3)再哈希法
同时构造多个哈希函数,直到找到不冲突的为止
hi=fi(key) ,i=1,2,3,…k
这种方法不易产生聚集,但增加计算时间。
(4)建立公共溢出区
将哈希表分为基本表和溢出表两部分,将于基本表冲突的元素均放入溢出表。














 7257
7257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









